 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multimodal LLMs on Code Generation for Complex Interactive Webpages
May 29, 2026Recent advancements in multimodal large language models (MLLMs) have achieved remarkable progress in multimodal reasoning and code generation, catalyzing a new paradigm for front-end development. In particular, these models can directly transform visual designs into executable code, significantly improving the efficiency and adaptability of web development. Modern web applications are dynamic and interactive, featuring frequent user-page interactions. However, existing benchmarks largely evaluate the code generation of static webpages, ignoring the complex interactive behaviors in real-world applications. Besides, their evaluation criteria remain confined to visual fidelity and code structure, overlooking the interaction consistency between the generated and the reference webpages. To address these limitations, we introduce WebIGBench, the first benchmark designed to evaluate code generation for interactive webpages with complex interactions. By combining manually designed interaction paths with UI automation, we collected 103 complex webpages from real-world websites. This benchmark covers 5 popular interactive action types (e.g., click, input) involving 871 distinct interactive actions. Moreover, we propose a novel evaluation pipeline to address the gap in automated assessment of interactive actions. Extensive experiments on several representative MLLMs reveal the performance boundaries of current models in interactive webpage code generation using WebIGBench. The proposed benchmark is available at https://github.com/anoa12159-hue/WebIGBench_eval.
Enhancing Gradient Inversion Attacks in Federated Learning via Hierarchical Feature Optimization
Apr 01, 2026Federated Learning (FL) has emerged as a compelling paradigm for privacy-preserving distributed machine learning, allowing multiple clients to collaboratively train a global model by transmitting locally computed gradients to a central server without exposing their private data. Nonetheless, recent studies find that the gradients exchanged in the FL system are also vulnerable to privacy leakage, e.g., an attacker can invert shared gradients to reconstruct sensitive data by leveraging pre-trained generative adversarial networks (GAN) as prior knowledge. However, existing attacks simply perform gradient inversion in the latent space of the GAN model, which limits their expression ability and generalizability. To tackle these challenges, we propose \textbf{G}radient \textbf{I}nversion over \textbf{F}eature \textbf{D}omains (GIFD), which disassembles the GAN model and searches the hierarchical features of the intermediate layers. Instead of optimizing only over the initial latent code, we progressively change the optimized layer, from the initial latent space to intermediate layers closer to the output images. In addition, we design a regularizer to avoid unreal image generation by adding a small ${l_1}$ ball constraint to the searching range. We also extend GIFD to the out-of-distribution (OOD) setting, which weakens the assumption that the training sets of GANs and FL tasks obey the same data distribution. Furthermore, we consider the challenging OOD scenario of label inconsistency and propose a label mapping technique as an effective solution. Extensive experiments demonstrate that our method can achieve pixel-level reconstruction and outperform competitive baselines across a variety of FL scenarios.
ErrorLLM: Modeling SQL Errors for Text-to-SQL Refinement
Mar 04, 2026Despite the remarkable performance of large language models (LLMs) in text-to-SQL (SQL generation), correctly producing SQL queries remains challenging during initial generation. The SQL refinement task is subsequently introduced to correct syntactic and semantic errors in generated SQL queries. However, existing paradigms face two major limitations: (i) self-debugging becomes increasingly ineffective as modern LLMs rarely produce explicit execution errors that can trigger debugging signals; (ii) self-correction exhibits low detection precision due to the lack of explicit error modeling grounded in the question and schema, and suffers from severe hallucination that frequently corrupts correct SQLs. In this paper, we propose ErrorLLM, a framework that explicitly models text-to-SQL Errors within a dedicated LLM for text-to-SQL refinement. Specifically, we represent the user question and database schema as structural features, employ static detection to identify execution failures and surface mismatches, and extend ErrorLLM's semantic space with dedicated error tokens that capture categorized implicit semantic error types. Through a well-designed training strategy, we explicitly model these errors with structural representations, enabling the LLM to detect complex implicit errors by predicting dedicated error tokens. Guided by the detected errors, we perform error-guided refinement on the SQL structure by prompting LLMs. Extensive experiments demonstrate that ErrorLLM achieves the most significant improvements over backbone initial generation. Further analysis reveals that detection quality directly determines refinement effectiveness, and ErrorLLM addresses both sides by high detection F1 score while maintain refinement effectiveness.
AXIOM: Benchmarking LLM-as-a-Judge for Code via Rule-Based Perturbation and Multisource Quality Calibration
Dec 23, 2025Large language models (LLMs) have been increasingly deployed in real-world software engineering, fostering the development of code evaluation metrics to study the quality of LLM-generated code. Conventional rule-based metrics merely score programs based on their surface-level similarities with reference programs instead of analyzing functionality and code quality in depth. To address this limitation, researchers have developed LLM-as-a-judge metrics, prompting LLMs to evaluate and score code, and curated various code evaluation benchmarks to validate their effectiveness. However, these benchmarks suffer from critical limitations, hindering reliable assessments of evaluation capability: Some feature coarse-grained binary labels, which reduce rich code behavior to a single bit of information, obscuring subtle errors. Others propose fine-grained but subjective, vaguely-defined evaluation criteria, introducing unreliability in manually-annotated scores, which is the ground-truth they rely on. Furthermore, they often use uncontrolled data synthesis methods, leading to unbalanced score distributions that poorly represent real-world code generation scenarios. To curate a diverse benchmark with programs of well-balanced distributions across various quality levels and streamline the manual annotation procedure, we propose AXIOM, a novel perturbation-based framework for synthesizing code evaluation benchmarks at scale. It reframes program scores as the refinement effort needed for deployment, consisting of two stages: (1) Rule-guided perturbation, which prompts LLMs to apply sequences of predefined perturbation rules to existing high-quality programs to modify their functionality and code quality, enabling us to precisely control each program's target score to achieve balanced score distributions. (2) Multisource quality calibration, which first selects a subset of...
Debiased Dual-Invariant Defense for Adversarially Robust Person Re-Identification
Nov 13, 2025Person re-identification (ReID) is a fundamental task in many real-world applications such as pedestrian trajectory tracking. However, advanced deep learning-based ReID models are highly susceptible to adversarial attacks, where imperceptible perturbations to pedestrian images can cause entirely incorrect predictions, posing significant security threats. Although numerous adversarial defense strategies have been proposed for classification tasks, their extension to metric learning tasks such as person ReID remains relatively unexplored. Moreover, the several existing defenses for person ReID fail to address the inherent unique challenges of adversarially robust ReID. In this paper, we systematically identify the challenges of adversarial defense in person ReID into two key issues: model bias and composite generalization requirements. To address them, we propose a debiased dual-invariant defense framework composed of two main phases. In the data balancing phase, we mitigate model bias using a diffusion-model-based data resampling strategy that promotes fairness and diversity in training data. In the bi-adversarial self-meta defense phase, we introduce a novel metric adversarial training approach incorporating farthest negative extension softening to overcome the robustness degradation caused by the absence of classifier. Additionally, we introduce an adversarially-enhanced self-meta mechanism to achieve dual-generalization for both unseen identities and unseen attack types. Experiments demonstrate that our method significantly outperforms existing state-of-the-art defenses.
CoMaPOI: A Collaborative Multi-Agent Framework for Next POI Prediction Bridging the Gap Between Trajectory and Language
May 28, 2025
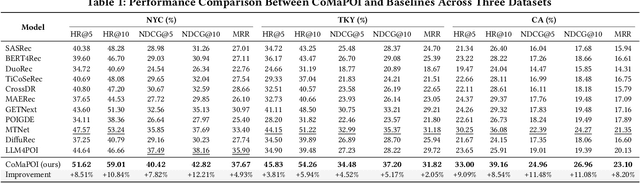
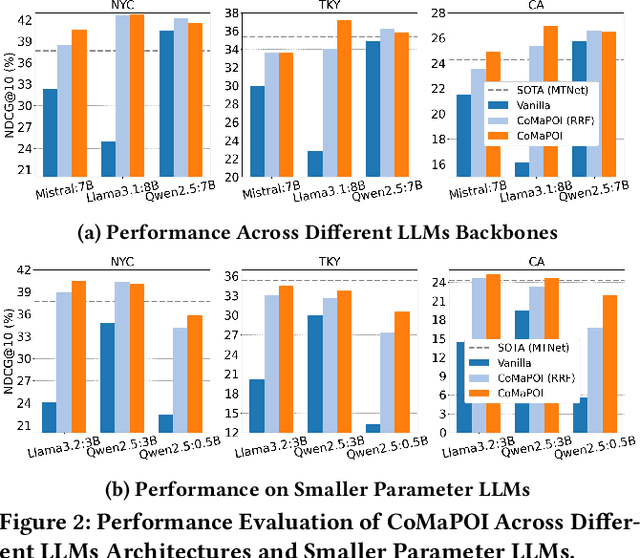
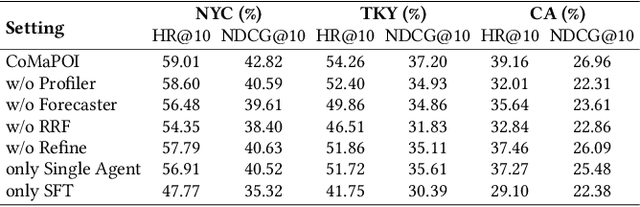
Large Language Models (LLMs) offer new opportunities for the next Point-Of-Interest (POI) prediction task, leveraging their capabilities in semantic understanding of POI trajectories. However, previous LLM-based methods, which are superficially adapted to next POI prediction, largely overlook critical challenges associated with applying LLMs to this task. Specifically, LLMs encounter two critical challenges: (1) a lack of intrinsic understanding of numeric spatiotemporal data, which hinders accurate modeling of users' spatiotemporal distributions and preferences; and (2) an excessively large and unconstrained candidate POI space, which often results in random or irrelevant predictions. To address these issues, we propose a Collaborative Multi Agent Framework for Next POI Prediction, named CoMaPOI. Through the close interaction of three specialized agents (Profiler, Forecaster, and Predictor), CoMaPOI collaboratively addresses the two critical challenges. The Profiler agent is responsible for converting numeric data into language descriptions, enhancing semantic understanding. The Forecaster agent focuses on dynamically constraining and refining the candidate POI space. The Predictor agent integrates this information to generate high-precision predictions. Extensive experiments on three benchmark datasets (NYC, TKY, and CA) demonstrate that CoMaPOI achieves state of the art performance, improving all metrics by 5% to 10% compared to SOTA baselines. This work pioneers the investigation of challenges associated with applying LLMs to complex spatiotemporal tasks by leveraging tailored collaborative agents.
Repository-Level Graph Representation Learning for Enhanced Security Patch Detection
Dec 11, 2024



Software vendors often silently release security patches without providing sufficient advisories (e.g., Common Vulnerabilities and Exposures) or delayed updates via resources (e.g., National Vulnerability Database). Therefore, it has become crucial to detect these security patches to ensure secure software maintenance. However, existing methods face the following challenges: (1) They primarily focus on the information within the patches themselves, overlooking the complex dependencies in the repository. (2) Security patches typically involve multiple functions and files, increasing the difficulty in well learning the representations. To alleviate the above challenges, this paper proposes a Repository-level Security Patch Detection framework named RepoSPD, which comprises three key components: 1) a repository-level graph construction, RepoCPG, which represents software patches by merging pre-patch and post-patch source code at the repository level; 2) a structure-aware patch representation, which fuses the graph and sequence branch and aims at comprehending the relationship among multiple code changes; 3) progressive learning, which facilitates the model in balancing semantic and structural information. To evaluate RepoSPD, we employ two widely-used datasets in security patch detection: SPI-DB and PatchDB. We further extend these datasets to the repository level, incorporating a total of 20,238 and 28,781 versions of repository in C/C++ programming languages, respectively, denoted as SPI-DB* and PatchDB*. We compare RepoSPD with six existing security patch detection methods and five static tools. Our experimental results demonstrate that RepoSPD outperforms the state-of-the-art baseline, with improvements of 11.90%, and 3.10% in terms of accuracy on the two datasets, respectively.
Active-Passive Federated Learning for Vertically Partitioned Multi-view Data
Sep 06, 2024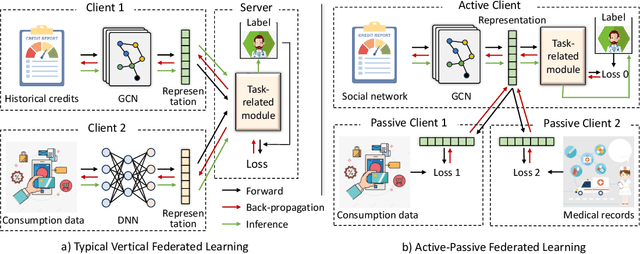


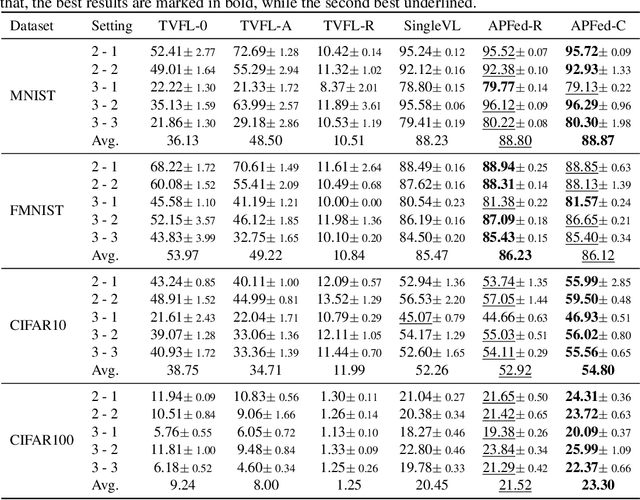
Vertical federated learning is a natural and elegant approach to integrate multi-view data vertically partitioned across devices (clients) while preserving their privacies. Apart from the model training, existing methods requires the collaboration of all clients in the model inference. However, the model inference is probably maintained for service in a long time, while the collaboration, especially when the clients belong to different organizations, is unpredictable in real-world scenarios, such as concellation of contract, network unavailablity, etc., resulting in the failure of them. To address this issue, we, at the first attempt, propose a flexible Active-Passive Federated learning (APFed) framework. Specifically, the active client is the initiator of a learning task and responsible to build the complete model, while the passive clients only serve as assistants. Once the model built, the active client can make inference independently. In addition, we instance the APFed framework into two classification methods with employing the reconstruction loss and the contrastive loss on passive clients, respectively. Meanwhile, the two methods are tested in a set of experiments and achieves desired results, validating their effectiveness.
DA-PFL: Dynamic Affinity Aggregation for Personalized Federated Learning
Mar 14, 2024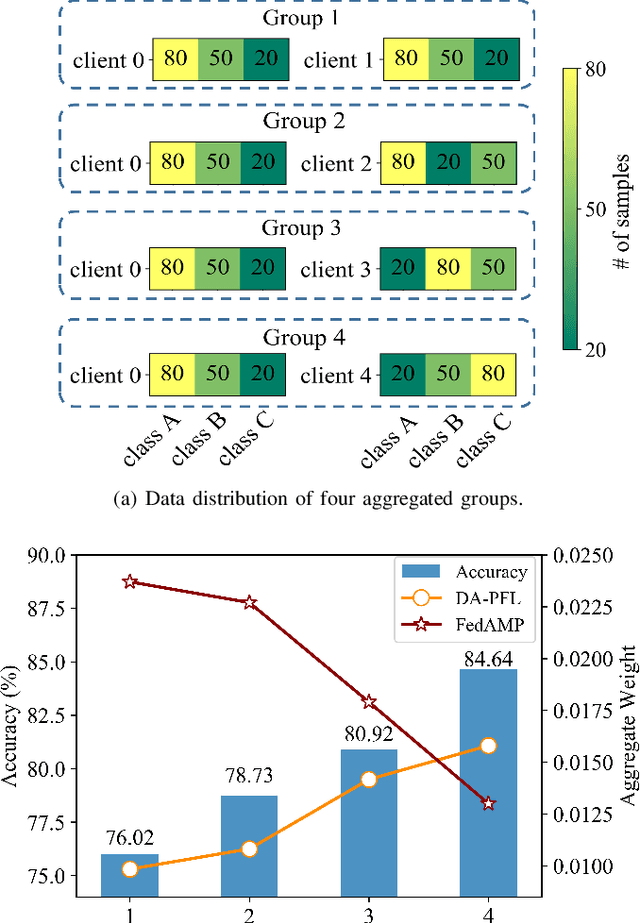
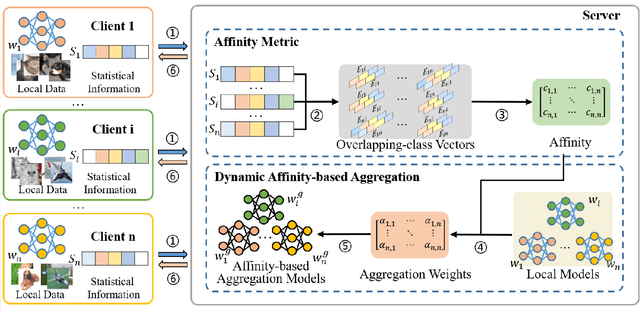
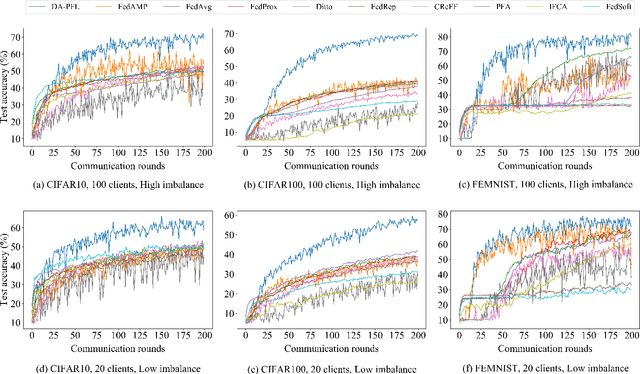
Personalized federated learning becomes a hot research topic that can learn a personalized learning model for each client. Existing personalized federated learning models prefer to aggregate similar clients with similar data distribution to improve the performance of learning models. However, similaritybased personalized federated learning methods may exacerbate the class imbalanced problem. In this paper, we propose a novel Dynamic Affinity-based Personalized Federated Learning model (DA-PFL) to alleviate the class imbalanced problem during federated learning. Specifically, we build an affinity metric from a complementary perspective to guide which clients should be aggregated. Then we design a dynamic aggregation strategy to dynamically aggregate clients based on the affinity metric in each round to reduce the class imbalanced risk. Extensive experiments show that the proposed DA-PFL model can significantly improve the accuracy of each client in three real-world datasets with state-of-the-art comparison methods.
FedHCDR: Federated Cross-Domain Recommendation with Hypergraph Signal Decoupling
Mar 06, 2024In recent years, Cross-Domain Recommendation (CDR) has drawn significant attention, which utilizes user data from multiple domains to enhance the recommendation performance. However, current CDR methods require sharing user data across domains, thereby violating the General Data Protection Regulation (GDPR). Consequently, numerous approaches have been proposed for Federated Cross-Domain Recommendation (FedCDR). Nevertheless, the data heterogeneity across different domains inevitably influences the overall performance of federated learning. In this study, we propose FedHCDR, a novel Federated Cross-Domain Recommendation framework with Hypergraph signal decoupling. Specifically, to address the data heterogeneity across domains, we introduce an approach called hypergraph signal decoupling (HSD) to decouple the user features into domain-exclusive and domain-shared features. The approach employs high-pass and low-pass hypergraph filters to decouple domain-exclusive and domain-shared user representations, which are trained by the local-global bi-directional transfer algorithm. In addition, a hypergraph contrastive learning (HCL) module is devised to enhance the learning of domain-shared user relationship information by perturbing the user hypergraph. Extensive experiments conducted on three real-world scenarios demonstrate that FedHCDR outperforms existing baselines significantly.