 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Trade-off to Synergy: A Versatile Symbiotic Watermarking Framework for Large Language Models
May 15, 2025The rise of Large Language Models (LLMs) has heightened concerns about the misuse of AI-generated text, making watermarking a promising solution. Mainstream watermarking schemes for LLMs fall into two categories: logits-based and sampling-based. However, current schemes entail trade-offs among robustness, text quality, and security. To mitigate this, we integrate logits-based and sampling-based schemes, harnessing their respective strengths to achieve synergy. In this paper, we propose a versatile symbiotic watermarking framework with three strategies: serial, parallel, and hybrid. The hybrid framework adaptively embeds watermarks using token entropy and semantic entropy, optimizing the balance between detectability, robustness, text quality, and security. Furthermore, we validate our approach through comprehensive experiments on various datasets and models. Experimental results indicate that our method outperforms existing baselines and achieves state-of-the-art (SOTA) performance. We believe this framework provides novel insights into diverse watermarking paradigms. Our code is available at \href{https://github.com/redwyd/SymMark}{https://github.com/redwyd/SymMark}.
PIG: Privacy Jailbreak Attack on LLMs via Gradient-based Iterative In-Context Optimization
May 15, 2025Large Language Models (LLMs) excel in various domains but pose inherent privacy risks. Existing methods to evaluate privacy leakage in LLMs often use memorized prefixes or simple instructions to extract data, both of which well-alignment models can easily block. Meanwhile, Jailbreak attacks bypass LLM safety mechanisms to generate harmful content, but their role in privacy scenarios remains underexplored. In this paper, we examine the effectiveness of jailbreak attacks in extracting sensitive information, bridging privacy leakage and jailbreak attacks in LLMs. Moreover, we propose PIG, a novel framework targeting Personally Identifiable Information (PII) and addressing the limitations of current jailbreak methods. Specifically, PIG identifies PII entities and their types in privacy queries, uses in-context learning to build a privacy context, and iteratively updates it with three gradient-based strategies to elicit target PII. We evaluate PIG and existing jailbreak methods using two privacy-related datasets. Experiments on four white-box and two black-box LLMs show that PIG outperforms baseline methods and achieves state-of-the-art (SoTA) results. The results underscore significant privacy risks in LLMs, emphasizing the need for stronger safeguards. Our code is availble at \href{https://github.com/redwyd/PrivacyJailbreak}{https://github.com/redwyd/PrivacyJailbreak}.
Neural Honeytrace: A Robust Plug-and-Play Watermarking Framework against Model Extraction Attacks
Jan 16, 2025Developing high-performance deep learning models is resource-intensive, leading model owners to utilize Machine Learning as a Service (MLaaS) platforms instead of publicly releasing their models. However, malicious users may exploit query interfaces to execute model extraction attacks, reconstructing the target model's functionality locally. While prior research has investigated triggerable watermarking techniques for asserting ownership, existing methods face significant challenges: (1) most approaches require additional training, resulting in high overhead and limited flexibility, and (2) they often fail to account for advanced attackers, leaving them vulnerable to adaptive attacks. In this paper, we propose Neural Honeytrace, a robust plug-and-play watermarking framework against model extraction attacks. We first formulate a watermark transmission model from an information-theoretic perspective, providing an interpretable account of the principles and limitations of existing triggerable watermarking. Guided by the model, we further introduce: (1) a similarity-based training-free watermarking method for plug-and-play and flexible watermarking, and (2) a distribution-based multi-step watermark information transmission strategy for robust watermarking. Comprehensive experiments on four datasets demonstrate that Neural Honeytrace outperforms previous methods in efficiency and resisting adaptive attacks. Neural Honeytrace reduces the average number of samples required for a worst-case t-Test-based copyright claim from $12,000$ to $200$ with zero training cost.
DA-PFL: Dynamic Affinity Aggregation for Personalized Federated Learning
Mar 14, 2024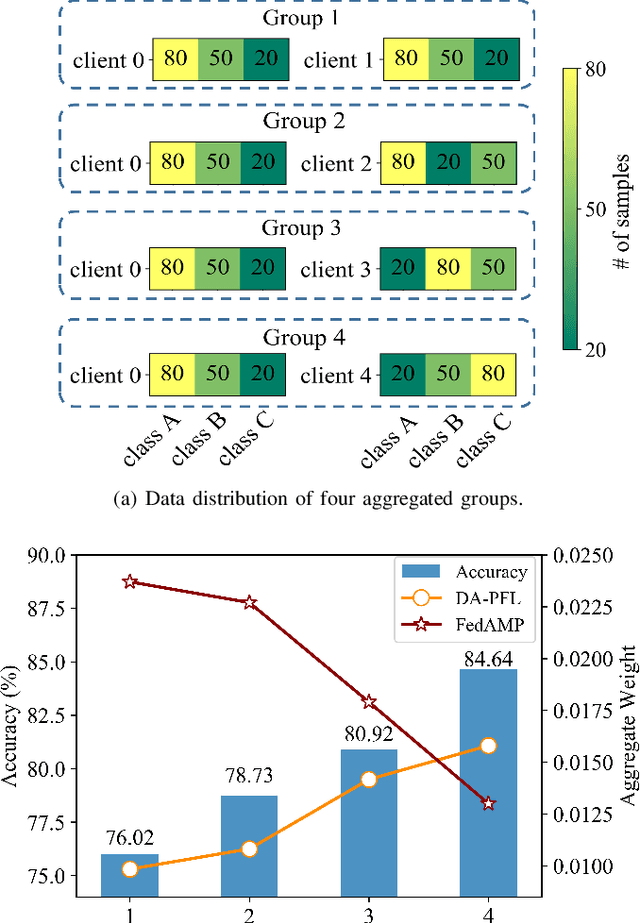
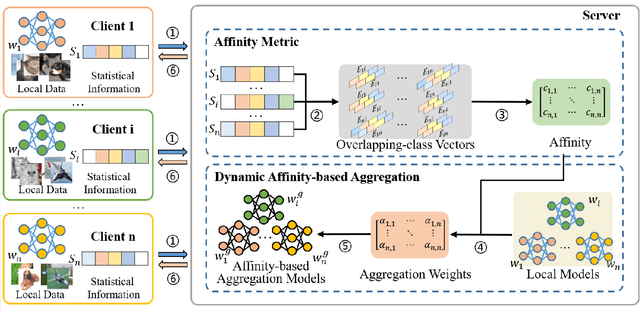
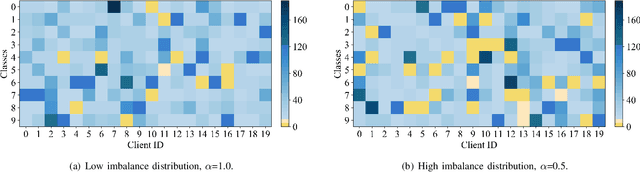
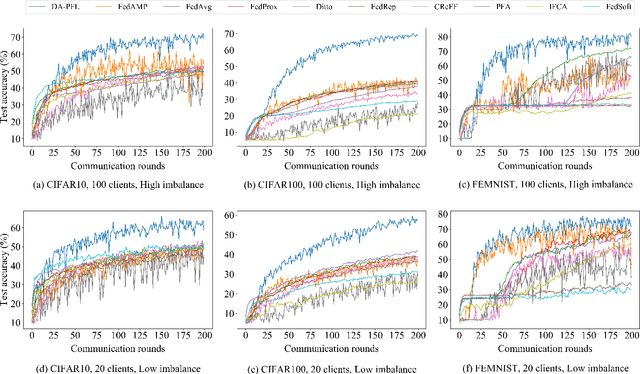
Personalized federated learning becomes a hot research topic that can learn a personalized learning model for each client. Existing personalized federated learning models prefer to aggregate similar clients with similar data distribution to improve the performance of learning models. However, similaritybased personalized federated learning methods may exacerbate the class imbalanced problem. In this paper, we propose a novel Dynamic Affinity-based Personalized Federated Learning model (DA-PFL) to alleviate the class imbalanced problem during federated learning. Specifically, we build an affinity metric from a complementary perspective to guide which clients should be aggregated. Then we design a dynamic aggregation strategy to dynamically aggregate clients based on the affinity metric in each round to reduce the class imbalanced risk. Extensive experiments show that the proposed DA-PFL model can significantly improve the accuracy of each client in three real-world datasets with state-of-the-art comparison methods.
Enhancing Stock Market Prediction with Extended Coupled Hidden Markov Model over Multi-Sourced Data
Sep 02, 2018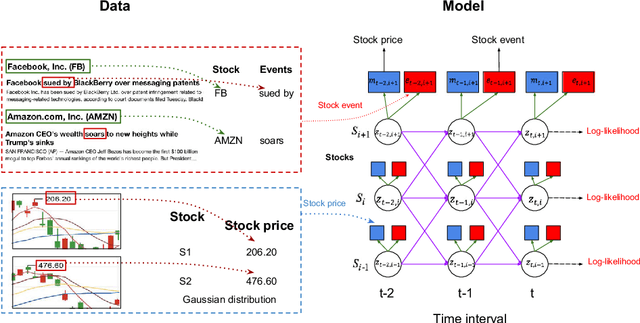


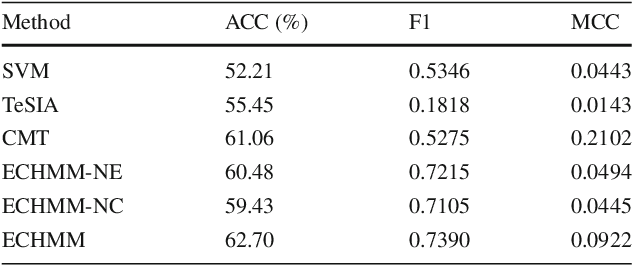
Traditional stock market prediction methods commonly only utilize the historical trading data, ignoring the fact that stock market fluctuations can be impacted by various other information sources such as stock related events. Although some recent works propose event-driven prediction approaches by considering the event data, how to leverage the joint impacts of multiple data sources still remains an open research problem. In this work, we study how to explore multiple data sources to improve the performance of the stock prediction. We introduce an Extended Coupled Hidden Markov Model incorporating the news events with the historical trading data. To address the data sparsity issue of news events for each single stock, we further study the fluctuation correlations between the stocks and incorporate the correlations into the model to facilitate the prediction task. Evaluations on China A-share market data in 2016 show the superior performance of our model against previous methods.