 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Multi-Interest Modeling for Cross-Domain Recommendation to Cold-Start Users
Apr 28, 2026Cross-domain recommendation (CDR) has demonstrated to be an effective solution for alleviating the user cold-start issue. By leveraging rich user-item interactions available in a richly informative source domain, CDR could improve the recommendation performance for cold-start users in the target domain. Previous CDR approaches mostly adhere the Embedding and Mapping (EMCDR) paradigm, which learns a user-shared mapping function to transfer users' preference from the source domain to the target domain, neglecting users' personalized preference. Recent CDR approaches further leverage the meta-learning paradigm, considering the CDR task for each user independently and learning user-specific mapping functions for each user. However, they mostly learn representations for each user individually, which ignores the common preference between different users, neglecting valuable information for CDR. In addition, all these approaches usually summarize the user's preference into an overall representation, which can hardly capture the user's multi-interest preference. To this end, we propose a personalized multi-interest modeling framework for CDR to cold-start users, termed as NF-NPCDR. Specifically, we propose a personalized preference encoder that enhances the neural process (NP) with the normalizing flow (NF) to convert the Gaussian (unimodal) distribution to a multimodal distribution, providing a novel way to capture the user's personalized multi-interest preference. Then, we propose a common preference encoder with a preference pool to capture the common preference between different users. Furthermore, we introduce a stochastic adaptive decoder to incorporate both the personalized and common preference for cold-start users, adaptively modulating both preference for better recommendation.
Rethinking Transferable Adversarial Attacks on Point Clouds from a Compact Subspace Perspective
Jan 30, 2026Transferable adversarial attacks on point clouds remain challenging, as existing methods often rely on model-specific gradients or heuristics that limit generalization to unseen architectures. In this paper, we rethink adversarial transferability from a compact subspace perspective and propose CoSA, a transferable attack framework that operates within a shared low-dimensional semantic space. Specifically, each point cloud is represented as a compact combination of class-specific prototypes that capture shared semantic structure, while adversarial perturbations are optimized within a low-rank subspace to induce coherent and architecture-agnostic variations. This design suppresses model-dependent noise and constrains perturbations to semantically meaningful directions, thereby improving cross-model transferability without relying on surrogate-specific artifacts. Extensive experiments on multiple datasets and network architectures demonstrate that CoSA consistently outperforms state-of-the-art transferable attacks, while maintaining competitive imperceptibility and robustness under common defense strategies. Codes will be made public upon paper acceptance.
Optimal Transport-Induced Samples against Out-of-Distribution Overconfidence
Jan 29, 2026Deep neural networks (DNNs) often produce overconfident predictions on out-of-distribution (OOD) inputs, undermining their reliability in open-world environments. Singularities in semi-discrete optimal transport (OT) mark regions of semantic ambiguity, where classifiers are particularly prone to unwarranted high-confidence predictions. Motivated by this observation, we propose a principled framework to mitigate OOD overconfidence by leveraging the geometry of OT-induced singular boundaries. Specifically, we formulate an OT problem between a continuous base distribution and the latent embeddings of training data, and identify the resulting singular boundaries. By sampling near these boundaries, we construct a class of OOD inputs, termed optimal transport-induced OOD samples (OTIS), which are geometrically grounded and inherently semantically ambiguous. During training, a confidence suppression loss is applied to OTIS to guide the model toward more calibrated predictions in structurally uncertain regions. Extensive experiments show that our method significantly alleviates OOD overconfidence and outperforms state-of-the-art methods.
Neural Honeytrace: A Robust Plug-and-Play Watermarking Framework against Model Extraction Attacks
Jan 16, 2025Developing high-performance deep learning models is resource-intensive, leading model owners to utilize Machine Learning as a Service (MLaaS) platforms instead of publicly releasing their models. However, malicious users may exploit query interfaces to execute model extraction attacks, reconstructing the target model's functionality locally. While prior research has investigated triggerable watermarking techniques for asserting ownership, existing methods face significant challenges: (1) most approaches require additional training, resulting in high overhead and limited flexibility, and (2) they often fail to account for advanced attackers, leaving them vulnerable to adaptive attacks. In this paper, we propose Neural Honeytrace, a robust plug-and-play watermarking framework against model extraction attacks. We first formulate a watermark transmission model from an information-theoretic perspective, providing an interpretable account of the principles and limitations of existing triggerable watermarking. Guided by the model, we further introduce: (1) a similarity-based training-free watermarking method for plug-and-play and flexible watermarking, and (2) a distribution-based multi-step watermark information transmission strategy for robust watermarking. Comprehensive experiments on four datasets demonstrate that Neural Honeytrace outperforms previous methods in efficiency and resisting adaptive attacks. Neural Honeytrace reduces the average number of samples required for a worst-case t-Test-based copyright claim from $12,000$ to $200$ with zero training cost.
Imperceptible Adversarial Attacks on Point Clouds Guided by Point-to-Surface Field
Dec 26, 2024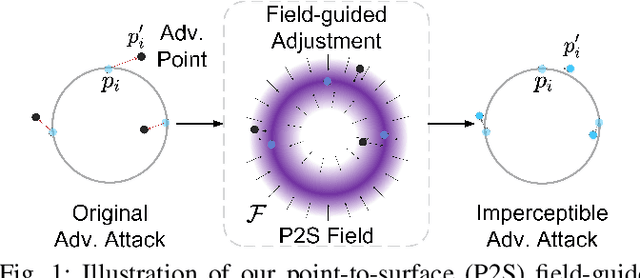


Adversarial attacks on point clouds are crucial for assessing and improving the adversarial robustness of 3D deep learning models. Traditional solutions strictly limit point displacement during attacks, making it challenging to balance imperceptibility with adversarial effectiveness. In this paper, we attribute the inadequate imperceptibility of adversarial attacks on point clouds to deviations from the underlying surface. To address this, we introduce a novel point-to-surface (P2S) field that adjusts adversarial perturbation directions by dragging points back to their original underlying surface. Specifically, we use a denoising network to learn the gradient field of the logarithmic density function encoding the shape's surface, and apply a distance-aware adjustment to perturbation directions during attacks, thereby enhancing imperceptibility. Extensive experiments show that adversarial attacks guided by our P2S field are more imperceptible, outperforming state-of-the-art methods.
ConsPrompt: Easily Exploiting Contrastive Samples for Few-shot Prompt Learning
Nov 08, 2022Prompt learning recently become an effective linguistic tool to motivate the PLMs' knowledge on few-shot-setting tasks. However, studies have shown the lack of robustness still exists in prompt learning, since suitable initialization of continuous prompt and expert-first manual prompt are essential in fine-tuning process. What is more, human also utilize their comparative ability to motivate their existing knowledge for distinguishing different examples. Motivated by this, we explore how to use contrastive samples to strengthen prompt learning. In detail, we first propose our model ConsPrompt combining with prompt encoding network, contrastive sampling module, and contrastive scoring module. Subsequently, two sampling strategies, similarity-based and label-based strategies, are introduced to realize differential contrastive learning. The effectiveness of proposed ConsPrompt is demonstrated in five different few-shot learning tasks and shown the similarity-based sampling strategy is more effective than label-based in combining contrastive learning. Our results also exhibits the state-of-the-art performance and robustness in different few-shot settings, which proves that the ConsPrompt could be assumed as a better knowledge probe to motivate PLMs.
PWG-IDS: An Intrusion Detection Model for Solving Class Imbalance in IIoT Networks Using Generative Adversarial Networks
Oct 06, 2021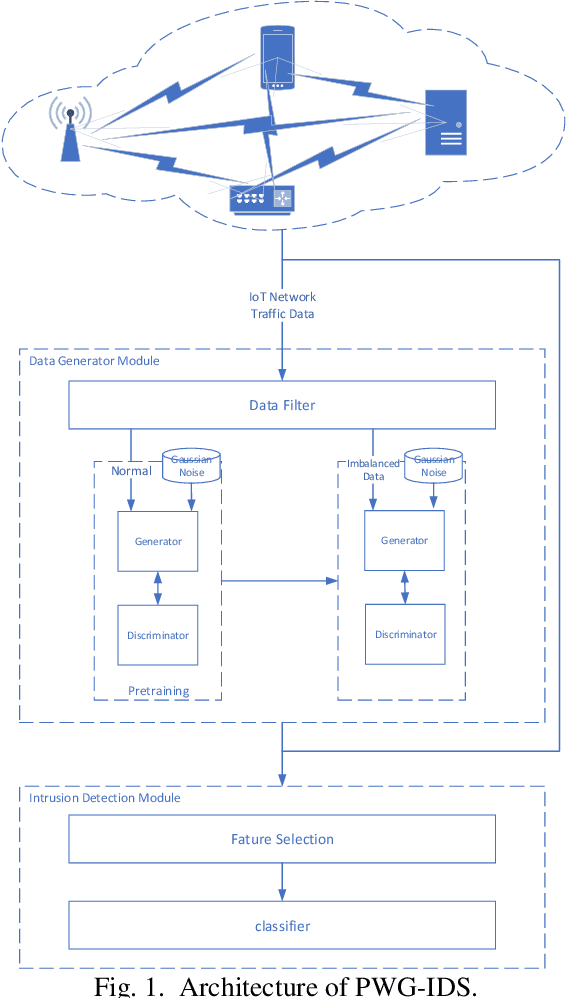
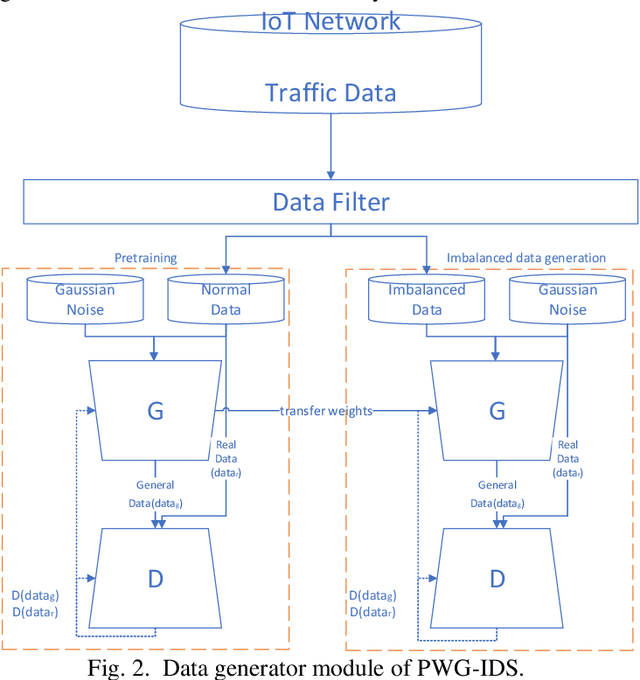
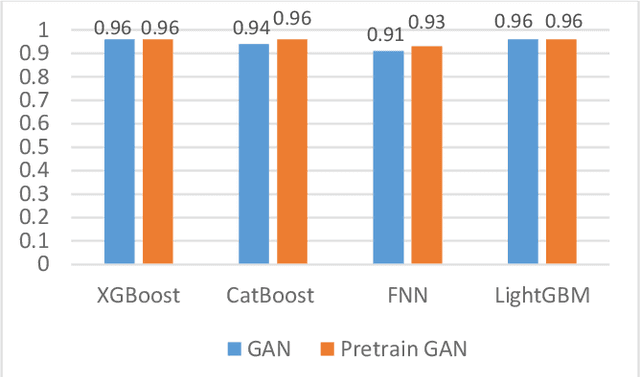
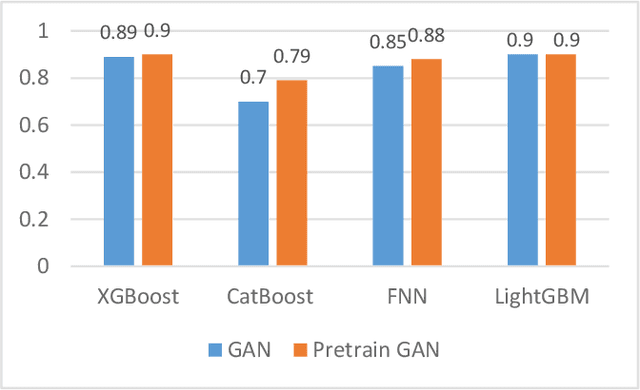
With the continuous development of industrial IoT (IIoT) technology, network security is becoming more and more important. And intrusion detection is an important part of its security. However, since the amount of attack traffic is very small compared to normal traffic, this imbalance makes intrusion detection in it very difficult. To address this imbalance, an intrusion detection system called pretraining Wasserstein generative adversarial network intrusion detection system (PWG-IDS) is proposed in this paper. This system is divided into two main modules: 1) In this module, we introduce the pretraining mechanism in the Wasserstein generative adversarial network with gradient penalty (WGAN-GP) for the first time, firstly using the normal network traffic to train the WGAN-GP, and then inputting the imbalance data into the pre-trained WGAN-GP to retrain and generate the final required data. 2) Intrusion detection module: We use LightGBM as the classification algorithm to detect attack traffic in IIoT networks. The experimental results show that our proposed PWG-IDS outperforms other models, with F1-scores of 99% and 89% on the 2 datasets, respectively. And the pretraining mechanism we proposed can also be widely used in other GANs, providing a new way of thinking for the training of GANs.
TREATED:Towards Universal Defense against Textual Adversarial Attacks
Sep 13, 2021
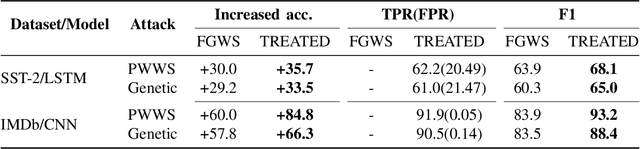
Recent work shows that deep neural networks are vulnerable to adversarial examples. Much work studies adversarial example generation, while very little work focuses on more critical adversarial defense. Existing adversarial detection methods usually make assumptions about the adversarial example and attack method (e.g., the word frequency of the adversarial example, the perturbation level of the attack method). However, this limits the applicability of the detection method. To this end, we propose TREATED, a universal adversarial detection method that can defend against attacks of various perturbation levels without making any assumptions. TREATED identifies adversarial examples through a set of well-designed reference models. Extensive experiments on three competitive neural networks and two widely used datasets show that our method achieves better detection performance than baselines. We finally conduct ablation studies to verify the effectiveness of our method.
Mask is All You Need: Rethinking Mask R-CNN for Dense and Arbitrary-Shaped Scene Text Detection
Sep 08, 2021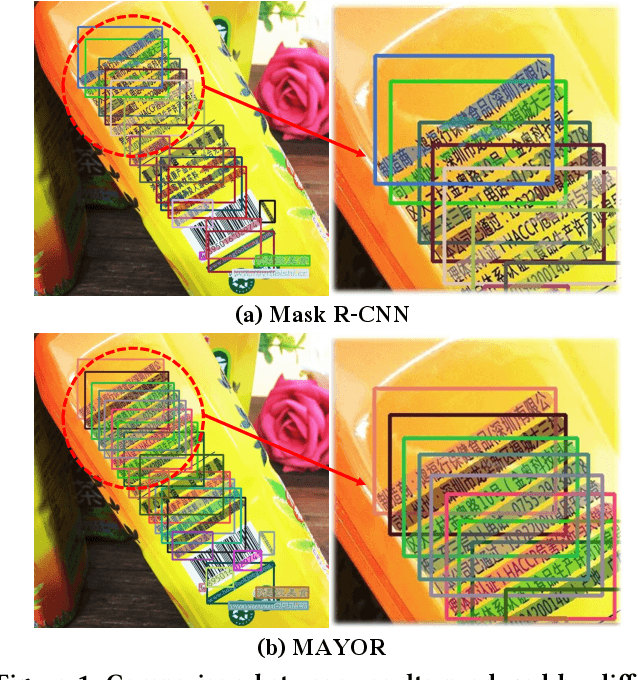
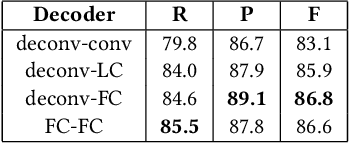
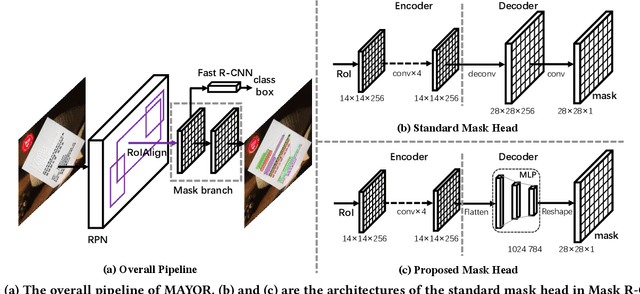
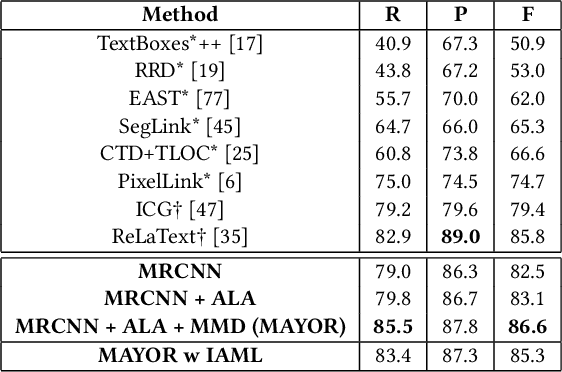
Due to the large success in object detection and instance segmentation, Mask R-CNN attracts great attention and is widely adopted as a strong baseline for arbitrary-shaped scene text detection and spotting. However, two issues remain to be settled. The first is dense text case, which is easy to be neglected but quite practical. There may exist multiple instances in one proposal, which makes it difficult for the mask head to distinguish different instances and degrades the performance. In this work, we argue that the performance degradation results from the learning confusion issue in the mask head. We propose to use an MLP decoder instead of the "deconv-conv" decoder in the mask head, which alleviates the issue and promotes robustness significantly. And we propose instance-aware mask learning in which the mask head learns to predict the shape of the whole instance rather than classify each pixel to text or non-text. With instance-aware mask learning, the mask branch can learn separated and compact masks. The second is that due to large variations in scale and aspect ratio, RPN needs complicated anchor settings, making it hard to maintain and transfer across different datasets. To settle this issue, we propose an adaptive label assignment in which all instances especially those with extreme aspect ratios are guaranteed to be associated with enough anchors. Equipped with these components, the proposed method named MAYOR achieves state-of-the-art performance on five benchmarks including DAST1500, MSRA-TD500, ICDAR2015, CTW1500, and Total-Text.
CODEs: Chamfer Out-of-Distribution Examples against Overconfidence Issue
Aug 13, 2021
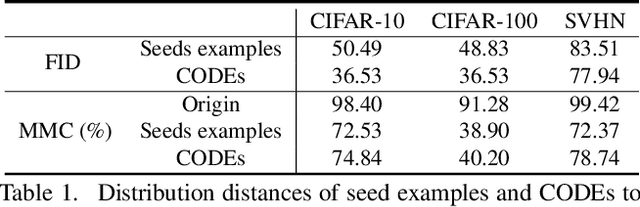

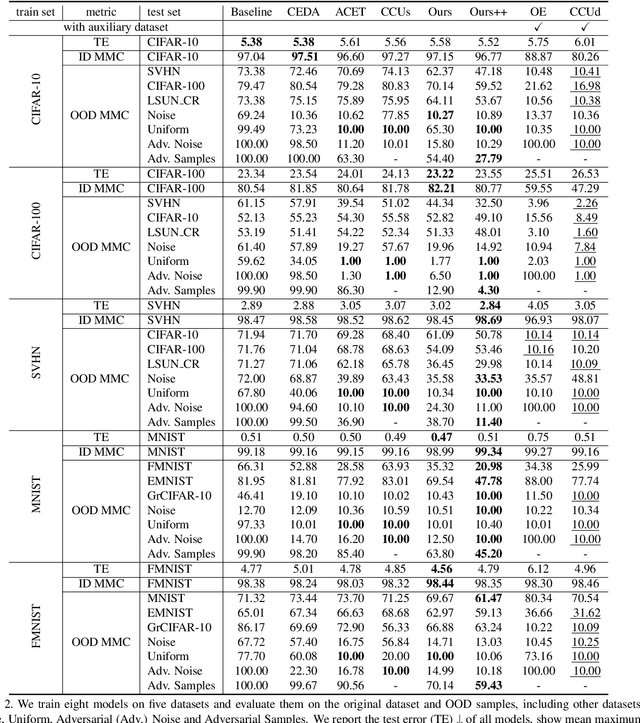
Overconfident predictions on out-of-distribution (OOD) samples is a thorny issue for deep neural networks. The key to resolve the OOD overconfidence issue inherently is to build a subset of OOD samples and then suppress predictions on them. This paper proposes the Chamfer OOD examples (CODEs), whose distribution is close to that of in-distribution samples, and thus could be utilized to alleviate the OOD overconfidence issue effectively by suppressing predictions on them. To obtain CODEs, we first generate seed OOD examples via slicing&splicing operations on in-distribution samples from different categories, and then feed them to the Chamfer generative adversarial network for distribution transformation, without accessing to any extra data. Training with suppressing predictions on CODEs is validated to alleviate the OOD overconfidence issue largely without hurting classification accuracy, and outperform the state-of-the-art methods. Besides, we demonstrate CODEs are useful for improving OOD detection and classification.