 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelping Language Models Learn More: Multi-dimensional Task Prompt for Few-shot Tuning
Dec 13, 2023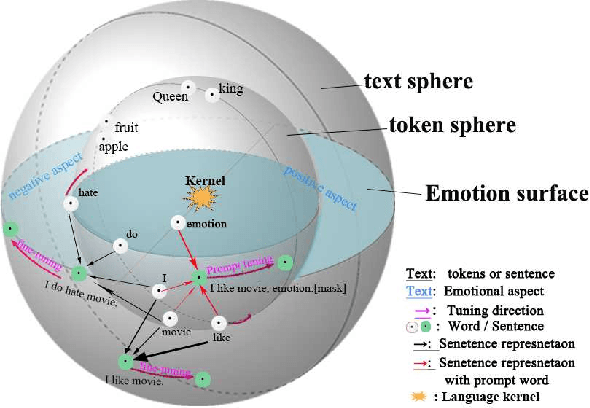


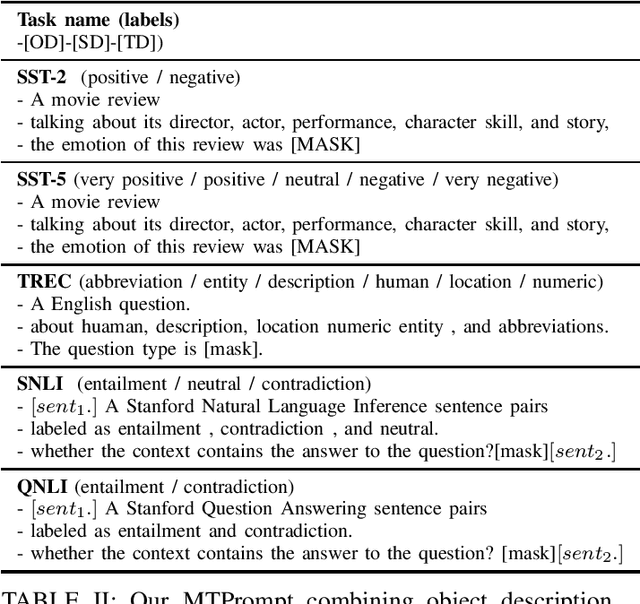
Large language models (LLMs) can be used as accessible and intelligent chatbots by constructing natural language queries and directly inputting the prompt into the large language model. However, different prompt' constructions often lead to uncertainty in the answers and thus make it hard to utilize the specific knowledge of LLMs (like ChatGPT). To alleviate this, we use an interpretable structure to explain the prompt learning principle in LLMs, which certificates that the effectiveness of language models is determined by position changes of the task's related tokens. Therefore, we propose MTPrompt, a multi-dimensional task prompt learning method consisting based on task-related object, summary, and task description information. By automatically building and searching for appropriate prompts, our proposed MTPrompt achieves the best results on few-shot samples setting and five different datasets. In addition, we demonstrate the effectiveness and stability of our method in different experimental settings and ablation experiments. In interaction with large language models, embedding more task-related information into prompts will make it easier to stimulate knowledge embedded in large language models.
ConsPrompt: Easily Exploiting Contrastive Samples for Few-shot Prompt Learning
Nov 08, 2022Prompt learning recently become an effective linguistic tool to motivate the PLMs' knowledge on few-shot-setting tasks. However, studies have shown the lack of robustness still exists in prompt learning, since suitable initialization of continuous prompt and expert-first manual prompt are essential in fine-tuning process. What is more, human also utilize their comparative ability to motivate their existing knowledge for distinguishing different examples. Motivated by this, we explore how to use contrastive samples to strengthen prompt learning. In detail, we first propose our model ConsPrompt combining with prompt encoding network, contrastive sampling module, and contrastive scoring module. Subsequently, two sampling strategies, similarity-based and label-based strategies, are introduced to realize differential contrastive learning. The effectiveness of proposed ConsPrompt is demonstrated in five different few-shot learning tasks and shown the similarity-based sampling strategy is more effective than label-based in combining contrastive learning. Our results also exhibits the state-of-the-art performance and robustness in different few-shot settings, which proves that the ConsPrompt could be assumed as a better knowledge probe to motivate PLMs.
STPrompt: Semantic-guided and Task-driven prompts for Effective Few-shot Classification
Oct 29, 2022



The effectiveness of prompt learning has been demonstrated in different pre-trained language models. By formulating suitable template and choosing representative label mapping, prompt learning can be used as an efficient knowledge probe. However, finding suitable prompt in existing methods requires multiple experimental attempts or appropriate vector initialization on formulating suitable template and choosing representative label mapping, which it is more common in few-shot learning tasks. Motivating by PLM working process, we try to construct the prompt from task semantic perspective and thus propose the STPrompt -Semantic-guided and Task-driven Prompt model. Specifically, two novel prompts generated from the semantic dependency tree (Dep-prompt) and task-specific metadata description (Meta-prompt), are firstly constructed in a prompt augmented pool, and the proposed model would automatically select a suitable semantic prompt to motivating the prompt learning process. Our results show that the proposed model achieves the state-of-the-art performance in five different datasets of few-shot text classification tasks, which prove that more semantic and significant prompts could assume as a better knowledge proving tool.
Construction and Application of Teaching System Based on Crowdsourcing Knowledge Graph
Oct 18, 2020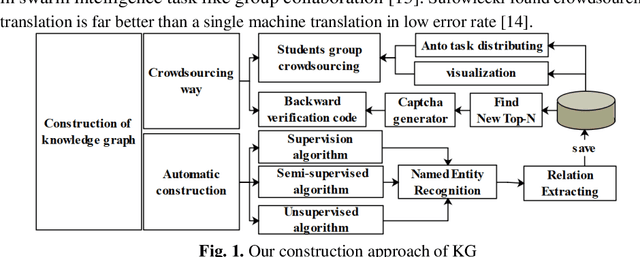
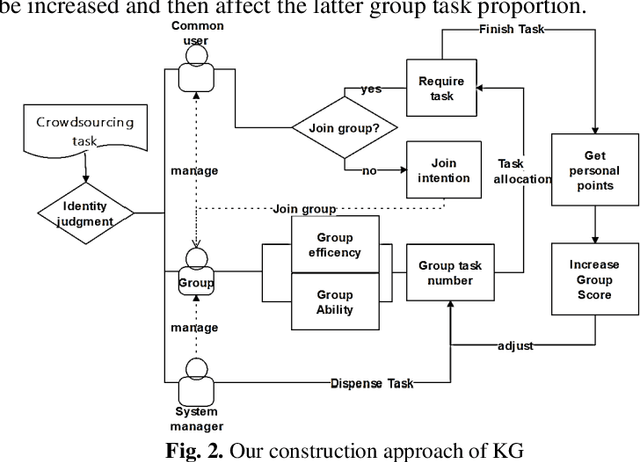
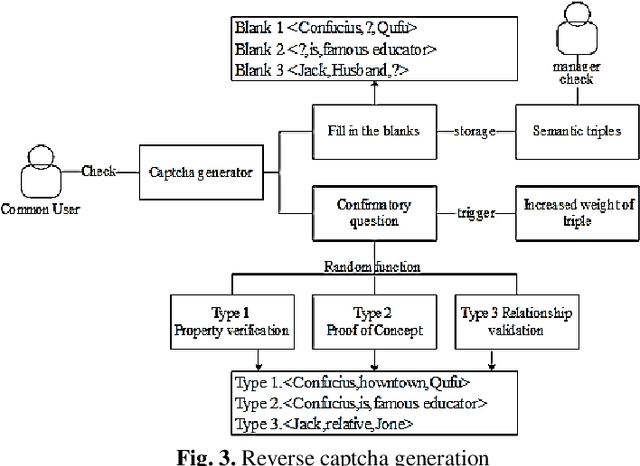

Through the combination of crowdsourcing knowledge graph and teaching system, research methods to generate knowledge graph and its applications. Using two crowdsourcing approaches, crowdsourcing task distribution and reverse captcha generation, to construct knowledge graph in the field of teaching system. Generating a complete hierarchical knowledge graph of the teaching domain by nodes of school, student, teacher, course, knowledge point and exercise type. The knowledge graph constructed in a crowdsourcing manner requires many users to participate collaboratively with fully consideration of teachers' guidance and users' mobilization issues. Based on the three subgraphs of knowledge graph, prominent teacher, student learning situation and suitable learning route could be visualized. Personalized exercises recommendation model is used to formulate the personalized exercise by algorithm based on the knowledge graph. Collaborative creation model is developed to realize the crowdsourcing construction mechanism. Though unfamiliarity with the learning mode of knowledge graph and learners' less attention to the knowledge structure, system based on Crowdsourcing Knowledge Graph can still get high acceptance around students and teachers
* Number of references:15 Classification code:903.3 Information Retrieval and Use Conference code: 235759