 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHelping Language Models Learn More: Multi-dimensional Task Prompt for Few-shot Tuning
Paper and Code
Dec 13, 2023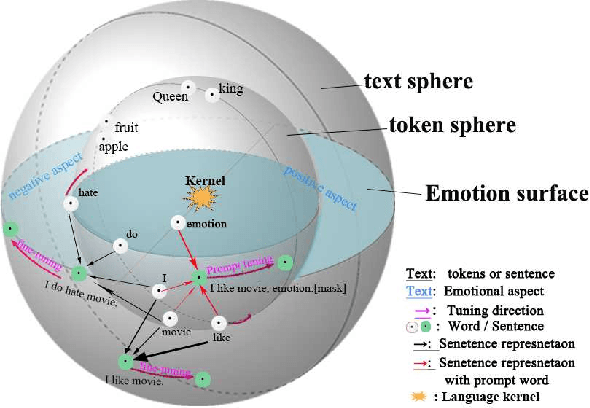


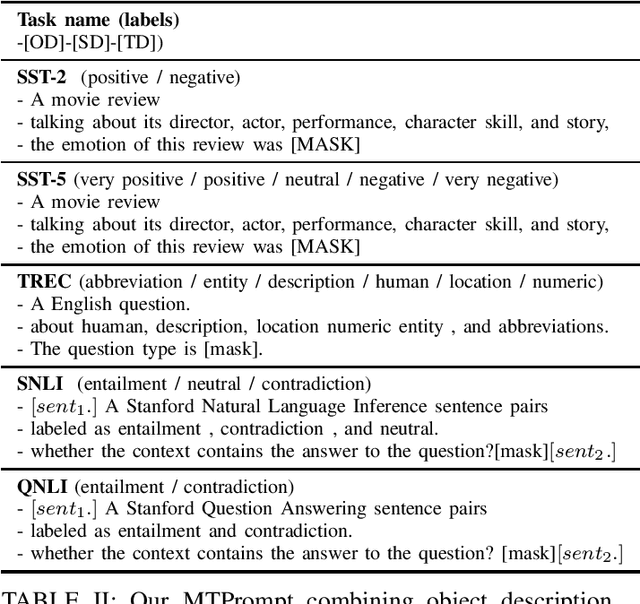
Large language models (LLMs) can be used as accessible and intelligent chatbots by constructing natural language queries and directly inputting the prompt into the large language model. However, different prompt' constructions often lead to uncertainty in the answers and thus make it hard to utilize the specific knowledge of LLMs (like ChatGPT). To alleviate this, we use an interpretable structure to explain the prompt learning principle in LLMs, which certificates that the effectiveness of language models is determined by position changes of the task's related tokens. Therefore, we propose MTPrompt, a multi-dimensional task prompt learning method consisting based on task-related object, summary, and task description information. By automatically building and searching for appropriate prompts, our proposed MTPrompt achieves the best results on few-shot samples setting and five different datasets. In addition, we demonstrate the effectiveness and stability of our method in different experimental settings and ablation experiments. In interaction with large language models, embedding more task-related information into prompts will make it easier to stimulate knowledge embedded in large language models.