 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Image-Level Morphological Trait Annotation for Organismal Images
Apr 02, 2026Morphological traits are physical characteristics of biological organisms that provide vital clues on how organisms interact with their environment. Yet extracting these traits remains a slow, expert-driven process, limiting their use in large-scale ecological studies. A major bottleneck is the absence of high-quality datasets linking biological images to trait-level annotations. In this work, we demonstrate that sparse autoencoders trained on foundation-model features yield monosemantic, spatially grounded neurons that consistently activate on meaningful morphological parts. Leveraging this property, we introduce a trait annotation pipeline that localizes salient regions and uses vision-language prompting to generate interpretable trait descriptions. Using this approach, we construct Bioscan-Traits, a dataset of 80K trait annotations spanning 19K insect images from BIOSCAN-5M. Human evaluation confirms the biological plausibility of the generated morphological descriptions. We assess design sensitivity through a comprehensive ablation study, systematically varying key design choices and measuring their impact on the quality of the resulting trait descriptions. By annotating traits with a modular pipeline rather than prohibitively expensive manual efforts, we offer a scalable way to inject biologically meaningful supervision into foundation models, enable large-scale morphological analyses, and bridge the gap between ecological relevance and machine-learning practicality.
* ICLR 2026
CUBE: A Standard for Unifying Agent Benchmarks
Mar 16, 2026The proliferation of agent benchmarks has created critical fragmentation that threatens research productivity. Each new benchmark requires substantial custom integration, creating an "integration tax" that limits comprehensive evaluation. We propose CUBE (Common Unified Benchmark Environments), a universal protocol standard built on MCP and Gym that allows benchmarks to be wrapped once and used everywhere. By separating task, benchmark, package, and registry concerns into distinct API layers, CUBE enables any compliant platform to access any compliant benchmark for evaluation, RL training, or data generation without custom integration. We call on the community to contribute to the development of this standard before platform-specific implementations deepen fragmentation as benchmark production accelerates through 2026.
REMem: Reasoning with Episodic Memory in Language Agent
Feb 13, 2026Humans excel at remembering concrete experiences along spatiotemporal contexts and performing reasoning across those events, i.e., the capacity for episodic memory. In contrast, memory in language agents remains mainly semantic, and current agents are not yet capable of effectively recollecting and reasoning over interaction histories. We identify and formalize the core challenges of episodic recollection and reasoning from this gap, and observe that existing work often overlooks episodicity, lacks explicit event modeling, or overemphasizes simple retrieval rather than complex reasoning. We present REMem, a two-phase framework for constructing and reasoning with episodic memory: 1) Offline indexing, where REMem converts experiences into a hybrid memory graph that flexibly links time-aware gists and facts. 2) Online inference, where REMem employs an agentic retriever with carefully curated tools for iterative retrieval over the memory graph. Comprehensive evaluation across four episodic memory benchmarks shows that REMem substantially outperforms state-of-the-art memory systems such as Mem0 and HippoRAG 2, showing 3.4% and 13.4% absolute improvements on episodic recollection and reasoning tasks, respectively. Moreover, REMem also demonstrates more robust refusal behavior for unanswerable questions.
Autonomous Continual Learning of Computer-Use Agents for Environment Adaptation
Feb 10, 2026Real-world digital environments are highly diverse and dynamic. These characteristics cause agents to frequently encounter unseen scenarios and distribution shifts, making continual learning in specific environments essential for computer-use agents (CUAs). However, a key challenge lies in obtaining high-quality and environment-grounded agent data without relying on costly human annotation. In this work, we introduce ACuRL, an Autonomous Curriculum Reinforcement Learning framework that continually adapts agents to specific environments with zero human data. The agent first explores target environments to acquire initial experiences. During subsequent iterative training, a curriculum task generator leverages these experiences together with feedback from the previous iteration to synthesize new tasks tailored for the agent's current capabilities. To provide reliable reward signals, we introduce CUAJudge, a robust automatic evaluator for CUAs that achieves 93% agreement with human judgments. Empirically, our method effectively enables both intra-environment and cross-environment continual learning, yielding 4-22% performance gains without catastrophic forgetting on existing environments. Further analyses show highly sparse updates (e.g., 20% parameters), which helps explain the effective and robust adaptation. Our data and code are available at https://github.com/OSU-NLP-Group/ACuRL.
When Benign Inputs Lead to Severe Harms: Eliciting Unsafe Unintended Behaviors of Computer-Use Agents
Feb 09, 2026Although computer-use agents (CUAs) hold significant potential to automate increasingly complex OS workflows, they can demonstrate unsafe unintended behaviors that deviate from expected outcomes even under benign input contexts. However, exploration of this risk remains largely anecdotal, lacking concrete characterization and automated methods to proactively surface long-tail unintended behaviors under realistic CUA scenarios. To fill this gap, we introduce the first conceptual and methodological framework for unintended CUA behaviors, by defining their key characteristics, automatically eliciting them, and analyzing how they arise from benign inputs. We propose AutoElicit: an agentic framework that iteratively perturbs benign instructions using CUA execution feedback, and elicits severe harms while keeping perturbations realistic and benign. Using AutoElicit, we surface hundreds of harmful unintended behaviors from state-of-the-art CUAs such as Claude 4.5 Haiku and Opus. We further evaluate the transferability of human-verified successful perturbations, identifying persistent susceptibility to unintended behaviors across various other frontier CUAs. This work establishes a foundation for systematically analyzing unintended behaviors in realistic computer-use settings.
Intelligent Multimodal Multi-Sensor Fusion-Based UAV Identification, Localization, and Countermeasures for Safeguarding Low-Altitude Economy
Oct 27, 2025The development of the low-altitude economy has led to a growing prominence of uncrewed aerial vehicle (UAV) safety management issues. Therefore, accurate identification, real-time localization, and effective countermeasures have become core challenges in airspace security assurance. This paper introduces an integrated UAV management and control system based on deep learning, which integrates multimodal multi-sensor fusion perception, precise positioning, and collaborative countermeasures. By incorporating deep learning methods, the system combines radio frequency (RF) spectral feature analysis, radar detection, electro-optical identification, and other methods at the detection level to achieve the identification and classification of UAVs. At the localization level, the system relies on multi-sensor data fusion and the air-space-ground integrated communication network to conduct real-time tracking and prediction of UAV flight status, providing support for early warning and decision-making. At the countermeasure level, it adopts comprehensive measures that integrate ``soft kill'' and ``hard kill'', including technologies such as electromagnetic signal jamming, navigation spoofing, and physical interception, to form a closed-loop management and control process from early warning to final disposal, which significantly enhances the response efficiency and disposal accuracy of low-altitude UAV management.
Watch and Learn: Learning to Use Computers from Online Videos
Oct 06, 2025Computer use agents (CUAs) need to plan task workflows grounded in diverse, ever-changing applications and environments, but learning is hindered by the scarcity of large-scale, high-quality training data in the target application. Existing datasets are domain-specific, static, and costly to annotate, while current synthetic data generation methods often yield simplistic or misaligned task demonstrations. To address these limitations, we introduce Watch & Learn (W&L), a framework that converts human demonstration videos readily available on the Internet into executable UI trajectories at scale. Instead of directly generating trajectories or relying on ad hoc reasoning heuristics, we cast the problem as an inverse dynamics objective: predicting the user's action from consecutive screen states. This formulation reduces manual engineering, is easier to learn, and generalizes more robustly across applications. Concretely, we develop an inverse dynamics labeling pipeline with task-aware video retrieval, generate over 53k high-quality trajectories from raw web videos, and demonstrate that these trajectories improve CUAs both as in-context demonstrations and as supervised training data. On the challenging OSWorld benchmark, UI trajectories extracted with W&L consistently enhance both general-purpose and state-of-the-art frameworks in-context, and deliver stronger gains for open-source models under supervised training. These results highlight web-scale human demonstration videos as a practical and scalable foundation for advancing CUAs towards real-world deployment.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025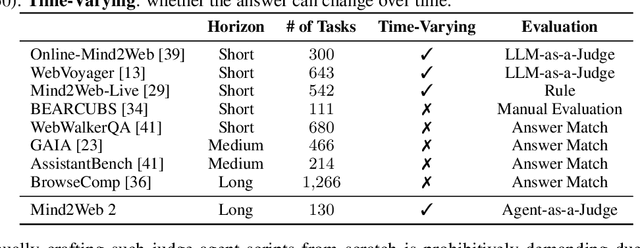
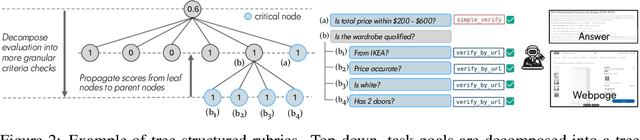

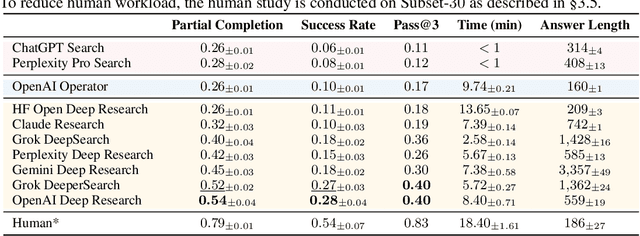
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025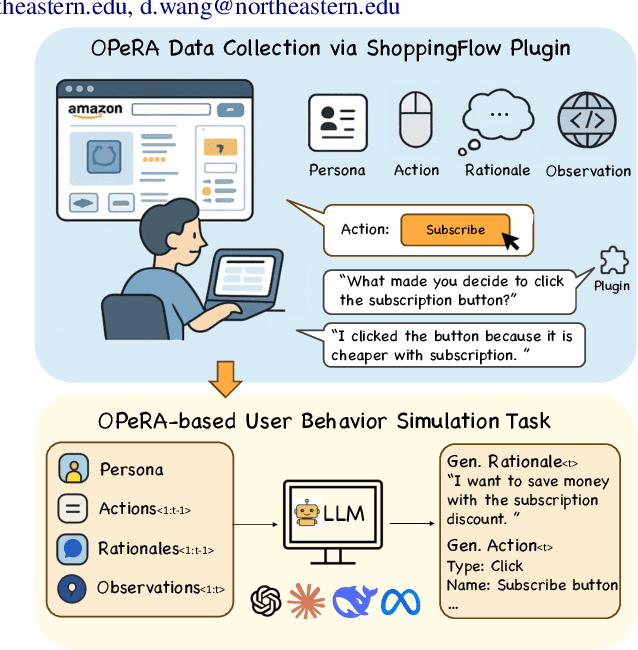
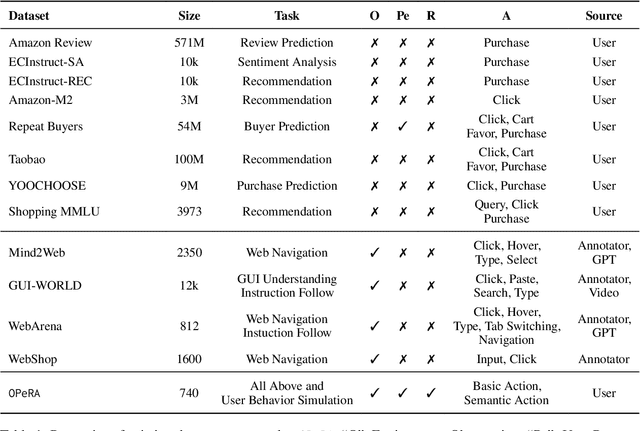
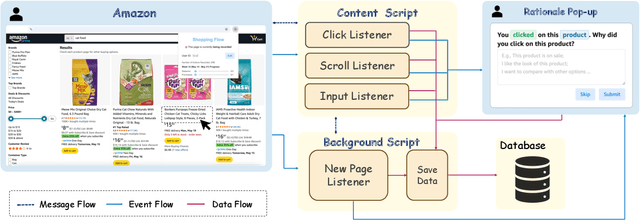
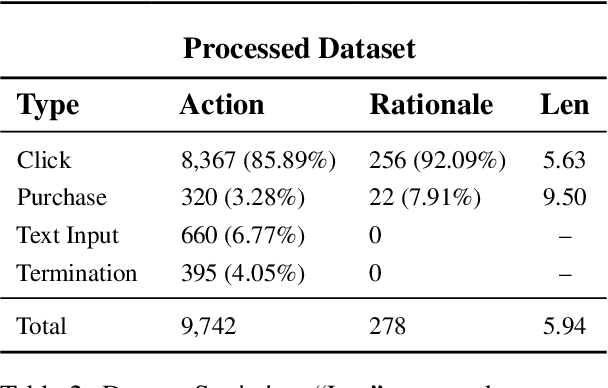
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
BioCLIP 2: Emergent Properties from Scaling Hierarchical Contrastive Learning
May 29, 2025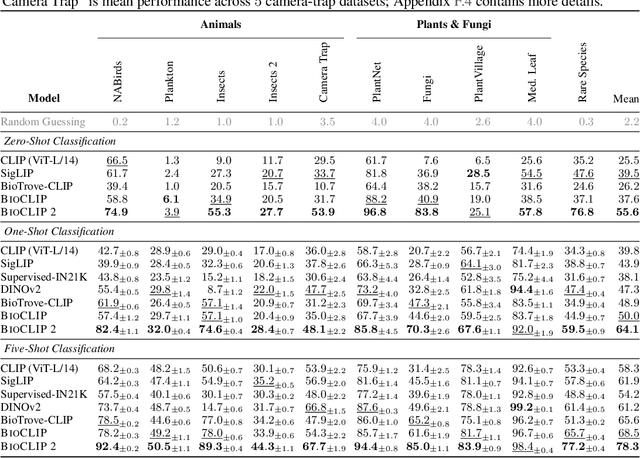
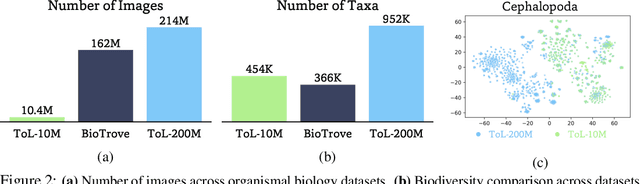
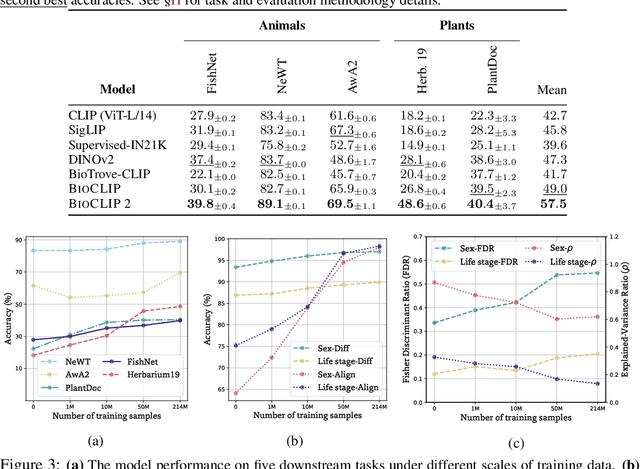
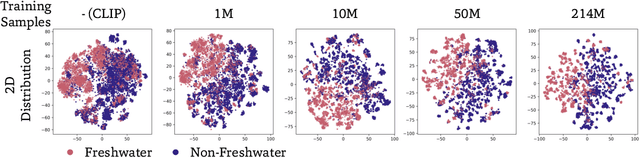
Foundation models trained at scale exhibit remarkable emergent behaviors, learning new capabilities beyond their initial training objectives. We find such emergent behaviors in biological vision models via large-scale contrastive vision-language training. To achieve this, we first curate TreeOfLife-200M, comprising 214 million images of living organisms, the largest and most diverse biological organism image dataset to date. We then train BioCLIP 2 on TreeOfLife-200M to distinguish different species. Despite the narrow training objective, BioCLIP 2 yields extraordinary accuracy when applied to various biological visual tasks such as habitat classification and trait prediction. We identify emergent properties in the learned embedding space of BioCLIP 2. At the inter-species level, the embedding distribution of different species aligns closely with functional and ecological meanings (e.g., beak sizes and habitats). At the intra-species level, instead of being diminished, the intra-species variations (e.g., life stages and sexes) are preserved and better separated in subspaces orthogonal to inter-species distinctions. We provide formal proof and analyses to explain why hierarchical supervision and contrastive objectives encourage these emergent properties. Crucially, our results reveal that these properties become increasingly significant with larger-scale training data, leading to a biologically meaningful embedding space.