 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIN-Bench: Tracing Native Evidence Chains in Long-Context Multimodal Scientific Interleaved Literature
Jan 15, 2026Evaluating whether multimodal large language models truly understand long-form scientific papers remains challenging: answer-only metrics and synthetic "Needle-In-A-Haystack" tests often reward answer matching without requiring a causal, evidence-linked reasoning trace in the document. We propose the "Fish-in-the-Ocean" (FITO) paradigm, which requires models to construct explicit cross-modal evidence chains within native scientific documents. To operationalize FITO, we build SIN-Data, a scientific interleaved corpus that preserves the native interleaving of text and figures. On top of it, we construct SIN-Bench with four progressive tasks covering evidence discovery (SIN-Find), hypothesis verification (SIN-Verify), grounded QA (SIN-QA), and evidence-anchored synthesis (SIN-Summary). We further introduce "No Evidence, No Score", scoring predictions when grounded to verifiable anchors and diagnosing evidence quality via matching, relevance, and logic. Experiments on eight MLLMs show that grounding is the primary bottleneck: Gemini-3-pro achieves the best average overall score (0.573), while GPT-5 attains the highest SIN-QA answer accuracy (0.767) but underperforms on evidence-aligned overall scores, exposing a gap between correctness and traceable support.
RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Environments
May 28, 2025Computer-use agents (CUAs) promise to automate complex tasks across operating systems (OS) and the web, but remain vulnerable to indirect prompt injection. Current evaluations of this threat either lack support realistic but controlled environments or ignore hybrid web-OS attack scenarios involving both interfaces. To address this, we propose RedTeamCUA, an adversarial testing framework featuring a novel hybrid sandbox that integrates a VM-based OS environment with Docker-based web platforms. Our sandbox supports key features tailored for red teaming, such as flexible adversarial scenario configuration, and a setting that decouples adversarial evaluation from navigational limitations of CUAs by initializing tests directly at the point of an adversarial injection. Using RedTeamCUA, we develop RTC-Bench, a comprehensive benchmark with 864 examples that investigate realistic, hybrid web-OS attack scenarios and fundamental security vulnerabilities. Benchmarking current frontier CUAs identifies significant vulnerabilities: Claude 3.7 Sonnet | CUA demonstrates an ASR of 42.9%, while Operator, the most secure CUA evaluated, still exhibits an ASR of 7.6%. Notably, CUAs often attempt to execute adversarial tasks with an Attempt Rate as high as 92.5%, although failing to complete them due to capability limitations. Nevertheless, we observe concerning ASRs of up to 50% in realistic end-to-end settings, with the recently released frontier Claude 4 Opus | CUA showing an alarming ASR of 48%, demonstrating that indirect prompt injection presents tangible risks for even advanced CUAs despite their capabilities and safeguards. Overall, RedTeamCUA provides an essential framework for advancing realistic, controlled, and systematic analysis of CUA vulnerabilities, highlighting the urgent need for robust defenses to indirect prompt injection prior to real-world deployment.
C2RUST-BENCH: A Minimized, Representative Dataset for C-to-Rust Transpilation Evaluation
Apr 21, 2025



Despite the effort in vulnerability detection over the last two decades, memory safety vulnerabilities continue to be a critical problem. Recent reports suggest that the key solution is to migrate to memory-safe languages. To this end, C-to-Rust transpilation becomes popular to resolve memory-safety issues in C programs. Recent works propose C-to-Rust transpilation frameworks; however, a comprehensive evaluation dataset is missing. Although one solution is to put together a large enough dataset, this increases the analysis time in automated frameworks as well as in manual efforts for some cases. In this work, we build a method to select functions from a large set to construct a minimized yet representative dataset to evaluate the C-to-Rust transpilation. We propose C2RUST-BENCH that contains 2,905 functions, which are representative of C-to-Rust transpilation, selected from 15,503 functions of real-world programs.
Binary Code Summarization: Benchmarking ChatGPT/GPT-4 and Other Large Language Models
Dec 15, 2023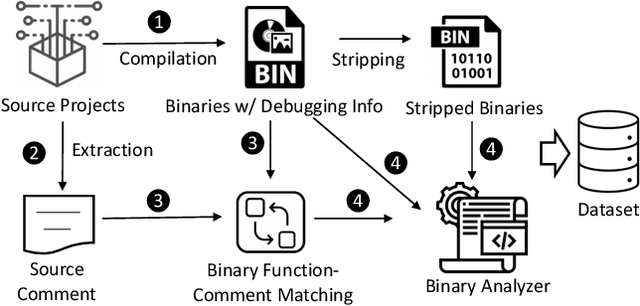


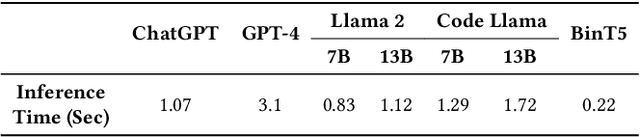
Binary code summarization, while invaluable for understanding code semantics, is challenging due to its labor-intensive nature. This study delves into the potential of large language models (LLMs) for binary code comprehension. To this end, we present BinSum, a comprehensive benchmark and dataset of over 557K binary functions and introduce a novel method for prompt synthesis and optimization. To more accurately gauge LLM performance, we also propose a new semantic similarity metric that surpasses traditional exact-match approaches. Our extensive evaluation of prominent LLMs, including ChatGPT, GPT-4, Llama 2, and Code Llama, reveals 10 pivotal insights. This evaluation generates 4 billion inference tokens, incurred a total expense of 11,418 US dollars and 873 NVIDIA A100 GPU hours. Our findings highlight both the transformative potential of LLMs in this field and the challenges yet to be overcome.