 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Code Summarization: Benchmarking ChatGPT/GPT-4 and Other Large Language Models
Paper and Code
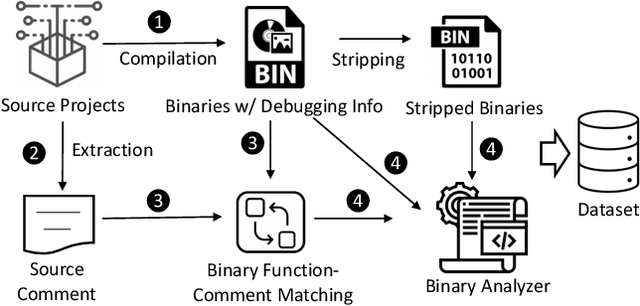


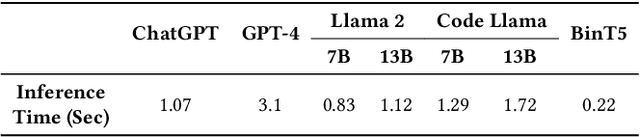
Binary code summarization, while invaluable for understanding code semantics, is challenging due to its labor-intensive nature. This study delves into the potential of large language models (LLMs) for binary code comprehension. To this end, we present BinSum, a comprehensive benchmark and dataset of over 557K binary functions and introduce a novel method for prompt synthesis and optimization. To more accurately gauge LLM performance, we also propose a new semantic similarity metric that surpasses traditional exact-match approaches. Our extensive evaluation of prominent LLMs, including ChatGPT, GPT-4, Llama 2, and Code Llama, reveals 10 pivotal insights. This evaluation generates 4 billion inference tokens, incurred a total expense of 11,418 US dollars and 873 NVIDIA A100 GPU hours. Our findings highlight both the transformative potential of LLMs in this field and the challenges yet to be overcome.