 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriTrail: Closed-Domain Hallucination Detection with Traceability
May 27, 2025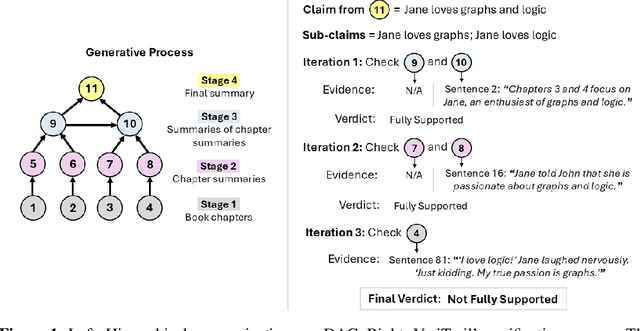
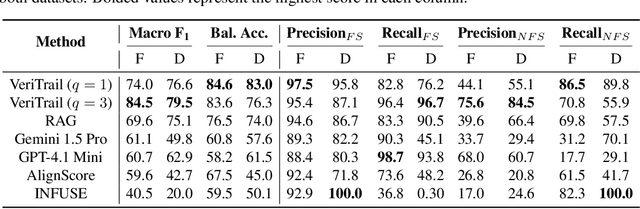
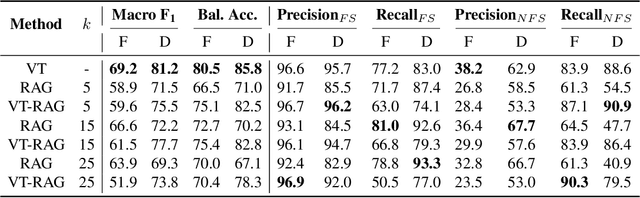
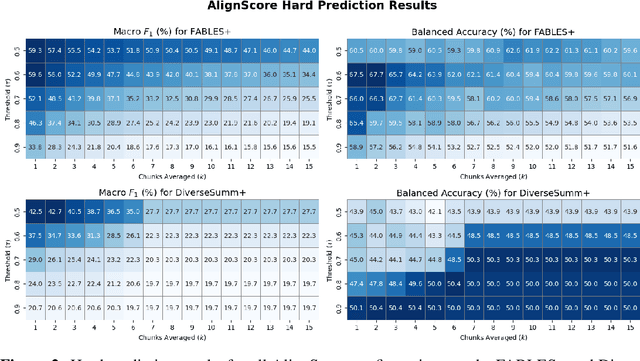
Even when instructed to adhere to source material, Language Models often generate unsubstantiated content - a phenomenon known as "closed-domain hallucination." This risk is amplified in processes with multiple generative steps (MGS), compared to processes with a single generative step (SGS). However, due to the greater complexity of MGS processes, we argue that detecting hallucinations in their final outputs is necessary but not sufficient: it is equally important to trace where hallucinated content was likely introduced and how faithful content may have been derived from the source through intermediate outputs. To address this need, we present VeriTrail, the first closed-domain hallucination detection method designed to provide traceability for both MGS and SGS processes. We also introduce the first datasets to include all intermediate outputs as well as human annotations of final outputs' faithfulness for their respective MGS processes. We demonstrate that VeriTrail outperforms baseline methods on both datasets.
Optimizing open-domain question answering with graph-based retrieval augmented generation
Mar 04, 2025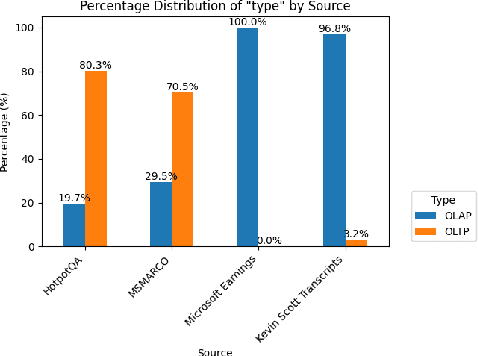
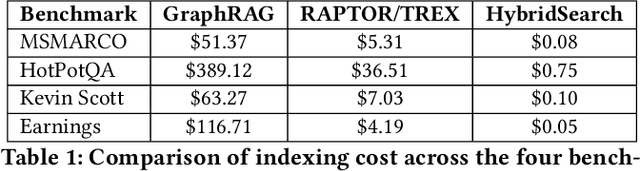
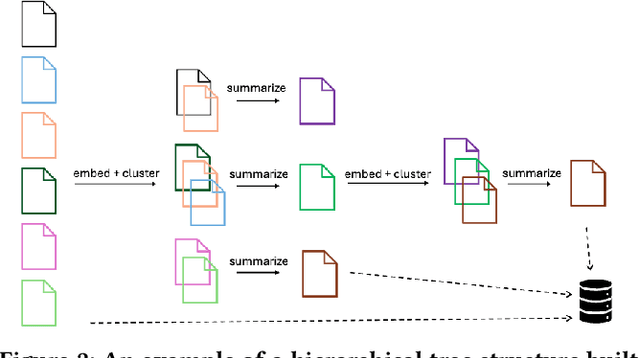
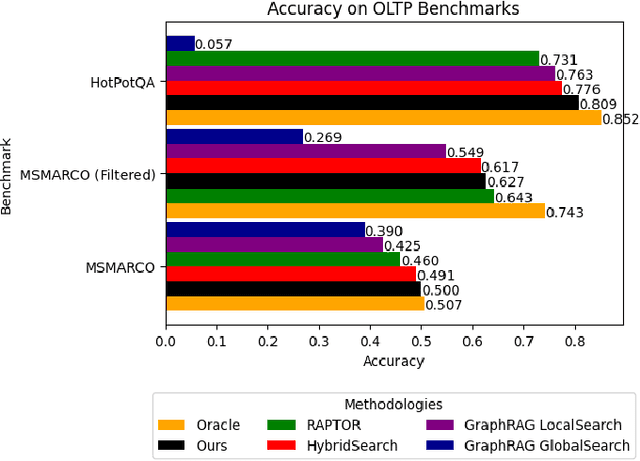
In this work, we benchmark various graph-based retrieval-augmented generation (RAG) systems across a broad spectrum of query types, including OLTP-style (fact-based) and OLAP-style (thematic) queries, to address the complex demands of open-domain question answering (QA). Traditional RAG methods often fall short in handling nuanced, multi-document synthesis tasks. By structuring knowledge as graphs, we can facilitate the retrieval of context that captures greater semantic depth and enhances language model operations. We explore graph-based RAG methodologies and introduce TREX, a novel, cost-effective alternative that combines graph-based and vector-based retrieval techniques. Our benchmarking across four diverse datasets highlights the strengths of different RAG methodologies, demonstrates TREX's ability to handle multiple open-domain QA types, and reveals the limitations of current evaluation methods. In a real-world technical support case study, we demonstrate how TREX solutions can surpass conventional vector-based RAG in efficiently synthesizing data from heterogeneous sources. Our findings underscore the potential of augmenting large language models with advanced retrieval and orchestration capabilities, advancing scalable, graph-based AI solutions.
Principal Graph Encoder Embedding and Principal Community Detection
Jan 24, 2025In this paper, we introduce the concept of principal communities and propose a principal graph encoder embedding method that concurrently detects these communities and achieves vertex embedding. Given a graph adjacency matrix with vertex labels, the method computes a sample community score for each community, ranking them to measure community importance and estimate a set of principal communities. The method then produces a vertex embedding by retaining only the dimensions corresponding to these principal communities. Theoretically, we define the population version of the encoder embedding and the community score based on a random Bernoulli graph distribution. We prove that the population principal graph encoder embedding preserves the conditional density of the vertex labels and that the population community score successfully distinguishes the principal communities. We conduct a variety of simulations to demonstrate the finite-sample accuracy in detecting ground-truth principal communities, as well as the advantages in embedding visualization and subsequent vertex classification. The method is further applied to a set of real-world graphs, showcasing its numerical advantages, including robustness to label noise and computational scalability.
Explaining Categorical Feature Interactions Using Graph Covariance and LLMs
Jan 24, 2025Modern datasets often consist of numerous samples with abundant features and associated timestamps. Analyzing such datasets to uncover underlying events typically requires complex statistical methods and substantial domain expertise. A notable example, and the primary data focus of this paper, is the global synthetic dataset from the Counter Trafficking Data Collaborative (CTDC) -- a global hub of human trafficking data containing over 200,000 anonymized records spanning from 2002 to 2022, with numerous categorical features for each record. In this paper, we propose a fast and scalable method for analyzing and extracting significant categorical feature interactions, and querying large language models (LLMs) to generate data-driven insights that explain these interactions. Our approach begins with a binarization step for categorical features using one-hot encoding, followed by the computation of graph covariance at each time. This graph covariance quantifies temporal changes in dependence structures within categorical data and is established as a consistent dependence measure under the Bernoulli distribution. We use this measure to identify significant feature pairs, such as those with the most frequent trends over time or those exhibiting sudden spikes in dependence at specific moments. These extracted feature pairs, along with their timestamps, are subsequently passed to an LLM tasked with generating potential explanations of the underlying events driving these dependence changes. The effectiveness of our method is demonstrated through extensive simulations, and its application to the CTDC dataset reveals meaningful feature pairs and potential data stories underlying the observed feature interactions.
Refined Graph Encoder Embedding via Self-Training and Latent Community Recovery
May 21, 2024This paper introduces a refined graph encoder embedding method, enhancing the original graph encoder embedding using linear transformation, self-training, and hidden community recovery within observed communities. We provide the theoretical rationale for the refinement procedure, demonstrating how and why our proposed method can effectively identify useful hidden communities via stochastic block models, and how the refinement method leads to improved vertex embedding and better decision boundaries for subsequent vertex classification. The efficacy of our approach is validated through a collection of simulated and real-world graph data.
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Apr 24, 2024The use of retrieval-augmented generation (RAG) to retrieve relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previously unseen document collections. However, RAG fails on global questions directed at an entire text corpus, such as "What are the main themes in the dataset?", since this is inherently a query-focused summarization (QFS) task, rather than an explicit retrieval task. Prior QFS methods, meanwhile, fail to scale to the quantities of text indexed by typical RAG systems. To combine the strengths of these contrasting methods, we propose a Graph RAG approach to question answering over private text corpora that scales with both the generality of user questions and the quantity of source text to be indexed. Our approach uses an LLM to build a graph-based text index in two stages: first to derive an entity knowledge graph from the source documents, then to pregenerate community summaries for all groups of closely-related entities. Given a question, each community summary is used to generate a partial response, before all partial responses are again summarized in a final response to the user. For a class of global sensemaking questions over datasets in the 1 million token range, we show that Graph RAG leads to substantial improvements over a na\"ive RAG baseline for both the comprehensiveness and diversity of generated answers. An open-source, Python-based implementation of both global and local Graph RAG approaches is forthcoming at https://aka.ms/graphrag.
Binary Code Summarization: Benchmarking ChatGPT/GPT-4 and Other Large Language Models
Dec 15, 2023


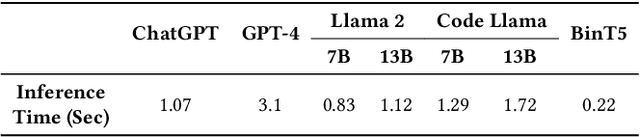
Binary code summarization, while invaluable for understanding code semantics, is challenging due to its labor-intensive nature. This study delves into the potential of large language models (LLMs) for binary code comprehension. To this end, we present BinSum, a comprehensive benchmark and dataset of over 557K binary functions and introduce a novel method for prompt synthesis and optimization. To more accurately gauge LLM performance, we also propose a new semantic similarity metric that surpasses traditional exact-match approaches. Our extensive evaluation of prominent LLMs, including ChatGPT, GPT-4, Llama 2, and Code Llama, reveals 10 pivotal insights. This evaluation generates 4 billion inference tokens, incurred a total expense of 11,418 US dollars and 873 NVIDIA A100 GPU hours. Our findings highlight both the transformative potential of LLMs in this field and the challenges yet to be overcome.
Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
Nov 28, 2023
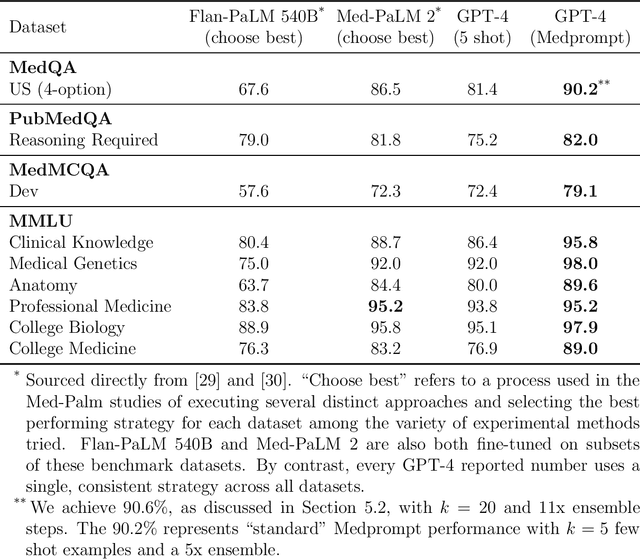


Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
Evaluating Cognitive Maps and Planning in Large Language Models with CogEval
Sep 25, 2023


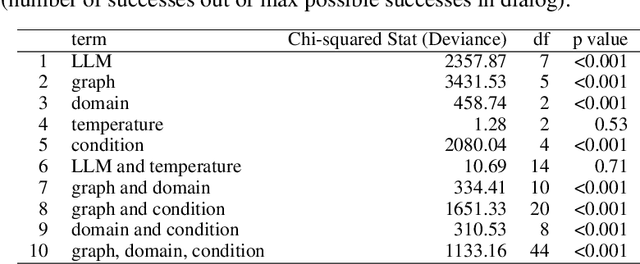
Recently an influx of studies claim emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions. First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and getting trapped in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.
Discovering Communication Pattern Shifts in Large-Scale Networks using Encoder Embedding and Vertex Dynamics
May 03, 2023The analysis of large-scale time-series network data, such as social media and email communications, remains a significant challenge for graph analysis methodology. In particular, the scalability of graph analysis is a critical issue hindering further progress in large-scale downstream inference. In this paper, we introduce a novel approach called "temporal encoder embedding" that can efficiently embed large amounts of graph data with linear complexity. We apply this method to an anonymized time-series communication network from a large organization spanning 2019-2020, consisting of over 100 thousand vertices and 80 million edges. Our method embeds the data within 10 seconds on a standard computer and enables the detection of communication pattern shifts for individual vertices, vertex communities, and the overall graph structure. Through supporting theory and synthesis studies, we demonstrate the theoretical soundness of our approach under random graph models and its numerical effectiveness through simulation studies.