 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Categorical Feature Interactions Using Graph Covariance and LLMs
Jan 24, 2025Modern datasets often consist of numerous samples with abundant features and associated timestamps. Analyzing such datasets to uncover underlying events typically requires complex statistical methods and substantial domain expertise. A notable example, and the primary data focus of this paper, is the global synthetic dataset from the Counter Trafficking Data Collaborative (CTDC) -- a global hub of human trafficking data containing over 200,000 anonymized records spanning from 2002 to 2022, with numerous categorical features for each record. In this paper, we propose a fast and scalable method for analyzing and extracting significant categorical feature interactions, and querying large language models (LLMs) to generate data-driven insights that explain these interactions. Our approach begins with a binarization step for categorical features using one-hot encoding, followed by the computation of graph covariance at each time. This graph covariance quantifies temporal changes in dependence structures within categorical data and is established as a consistent dependence measure under the Bernoulli distribution. We use this measure to identify significant feature pairs, such as those with the most frequent trends over time or those exhibiting sudden spikes in dependence at specific moments. These extracted feature pairs, along with their timestamps, are subsequently passed to an LLM tasked with generating potential explanations of the underlying events driving these dependence changes. The effectiveness of our method is demonstrated through extensive simulations, and its application to the CTDC dataset reveals meaningful feature pairs and potential data stories underlying the observed feature interactions.
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Apr 24, 2024The use of retrieval-augmented generation (RAG) to retrieve relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previously unseen document collections. However, RAG fails on global questions directed at an entire text corpus, such as "What are the main themes in the dataset?", since this is inherently a query-focused summarization (QFS) task, rather than an explicit retrieval task. Prior QFS methods, meanwhile, fail to scale to the quantities of text indexed by typical RAG systems. To combine the strengths of these contrasting methods, we propose a Graph RAG approach to question answering over private text corpora that scales with both the generality of user questions and the quantity of source text to be indexed. Our approach uses an LLM to build a graph-based text index in two stages: first to derive an entity knowledge graph from the source documents, then to pregenerate community summaries for all groups of closely-related entities. Given a question, each community summary is used to generate a partial response, before all partial responses are again summarized in a final response to the user. For a class of global sensemaking questions over datasets in the 1 million token range, we show that Graph RAG leads to substantial improvements over a na\"ive RAG baseline for both the comprehensiveness and diversity of generated answers. An open-source, Python-based implementation of both global and local Graph RAG approaches is forthcoming at https://aka.ms/graphrag.
Causally Constrained Data Synthesis for Private Data Release
May 27, 2021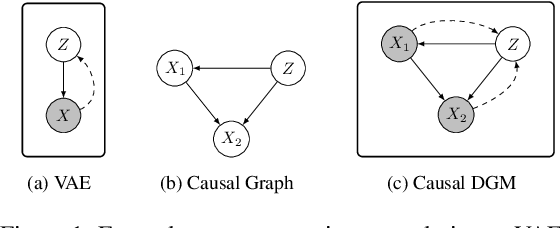
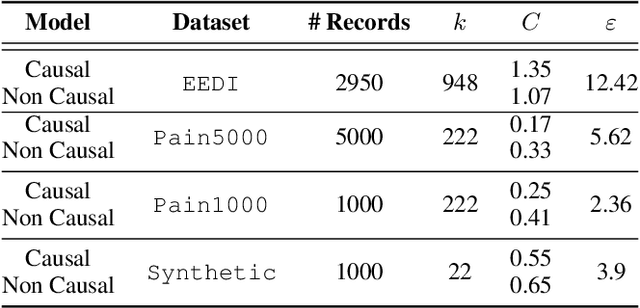
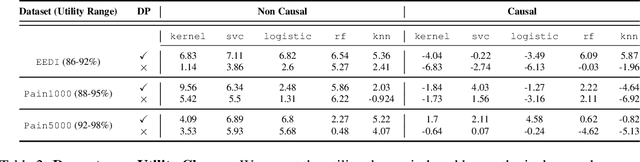
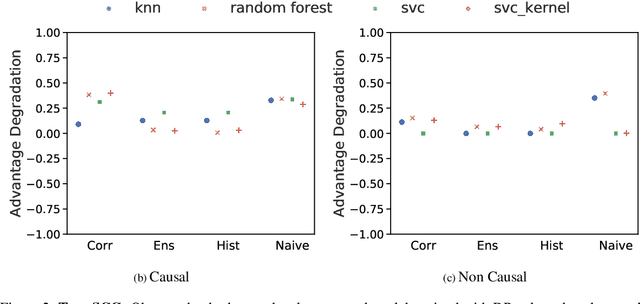
Making evidence based decisions requires data. However for real-world applications, the privacy of data is critical. Using synthetic data which reflects certain statistical properties of the original data preserves the privacy of the original data. To this end, prior works utilize differentially private data release mechanisms to provide formal privacy guarantees. However, such mechanisms have unacceptable privacy vs. utility trade-offs. We propose incorporating causal information into the training process to favorably modify the aforementioned trade-off. We theoretically prove that generative models trained with additional causal knowledge provide stronger differential privacy guarantees. Empirically, we evaluate our solution comparing different models based on variational auto-encoders (VAEs), and show that causal information improves resilience to membership inference, with improvements in downstream utility.