 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing open-domain question answering with graph-based retrieval augmented generation
Mar 04, 2025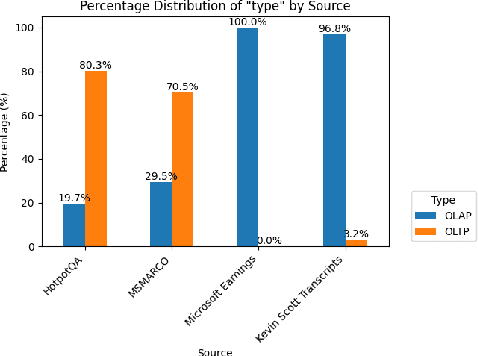
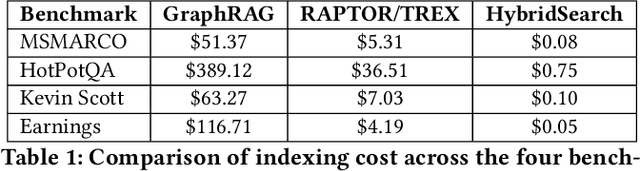
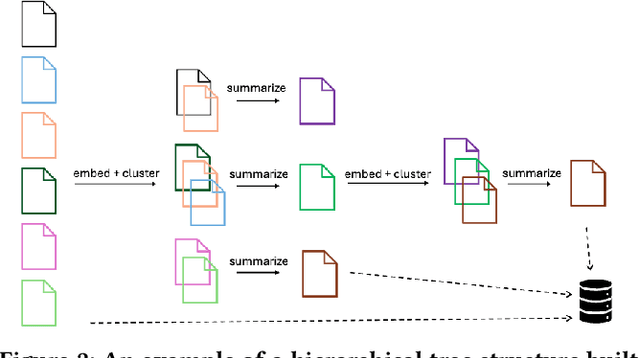
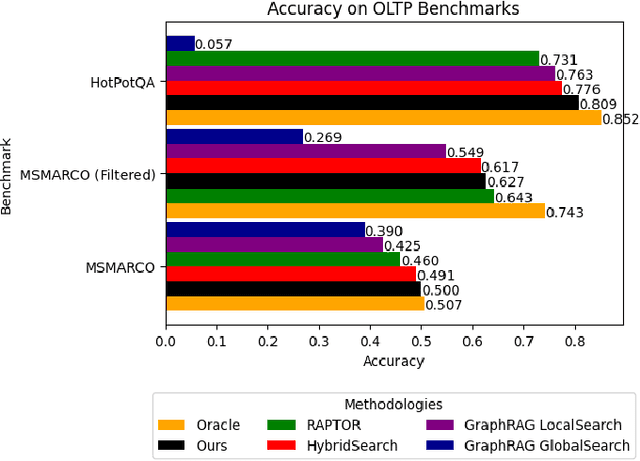
In this work, we benchmark various graph-based retrieval-augmented generation (RAG) systems across a broad spectrum of query types, including OLTP-style (fact-based) and OLAP-style (thematic) queries, to address the complex demands of open-domain question answering (QA). Traditional RAG methods often fall short in handling nuanced, multi-document synthesis tasks. By structuring knowledge as graphs, we can facilitate the retrieval of context that captures greater semantic depth and enhances language model operations. We explore graph-based RAG methodologies and introduce TREX, a novel, cost-effective alternative that combines graph-based and vector-based retrieval techniques. Our benchmarking across four diverse datasets highlights the strengths of different RAG methodologies, demonstrates TREX's ability to handle multiple open-domain QA types, and reveals the limitations of current evaluation methods. In a real-world technical support case study, we demonstrate how TREX solutions can surpass conventional vector-based RAG in efficiently synthesizing data from heterogeneous sources. Our findings underscore the potential of augmenting large language models with advanced retrieval and orchestration capabilities, advancing scalable, graph-based AI solutions.
Principal Graph Encoder Embedding and Principal Community Detection
Jan 24, 2025In this paper, we introduce the concept of principal communities and propose a principal graph encoder embedding method that concurrently detects these communities and achieves vertex embedding. Given a graph adjacency matrix with vertex labels, the method computes a sample community score for each community, ranking them to measure community importance and estimate a set of principal communities. The method then produces a vertex embedding by retaining only the dimensions corresponding to these principal communities. Theoretically, we define the population version of the encoder embedding and the community score based on a random Bernoulli graph distribution. We prove that the population principal graph encoder embedding preserves the conditional density of the vertex labels and that the population community score successfully distinguishes the principal communities. We conduct a variety of simulations to demonstrate the finite-sample accuracy in detecting ground-truth principal communities, as well as the advantages in embedding visualization and subsequent vertex classification. The method is further applied to a set of real-world graphs, showcasing its numerical advantages, including robustness to label noise and computational scalability.
Refined Graph Encoder Embedding via Self-Training and Latent Community Recovery
May 21, 2024This paper introduces a refined graph encoder embedding method, enhancing the original graph encoder embedding using linear transformation, self-training, and hidden community recovery within observed communities. We provide the theoretical rationale for the refinement procedure, demonstrating how and why our proposed method can effectively identify useful hidden communities via stochastic block models, and how the refinement method leads to improved vertex embedding and better decision boundaries for subsequent vertex classification. The efficacy of our approach is validated through a collection of simulated and real-world graph data.
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Apr 24, 2024The use of retrieval-augmented generation (RAG) to retrieve relevant information from an external knowledge source enables large language models (LLMs) to answer questions over private and/or previously unseen document collections. However, RAG fails on global questions directed at an entire text corpus, such as "What are the main themes in the dataset?", since this is inherently a query-focused summarization (QFS) task, rather than an explicit retrieval task. Prior QFS methods, meanwhile, fail to scale to the quantities of text indexed by typical RAG systems. To combine the strengths of these contrasting methods, we propose a Graph RAG approach to question answering over private text corpora that scales with both the generality of user questions and the quantity of source text to be indexed. Our approach uses an LLM to build a graph-based text index in two stages: first to derive an entity knowledge graph from the source documents, then to pregenerate community summaries for all groups of closely-related entities. Given a question, each community summary is used to generate a partial response, before all partial responses are again summarized in a final response to the user. For a class of global sensemaking questions over datasets in the 1 million token range, we show that Graph RAG leads to substantial improvements over a na\"ive RAG baseline for both the comprehensiveness and diversity of generated answers. An open-source, Python-based implementation of both global and local Graph RAG approaches is forthcoming at https://aka.ms/graphrag.
Discovering Communication Pattern Shifts in Large-Scale Networks using Encoder Embedding and Vertex Dynamics
May 03, 2023The analysis of large-scale time-series network data, such as social media and email communications, remains a significant challenge for graph analysis methodology. In particular, the scalability of graph analysis is a critical issue hindering further progress in large-scale downstream inference. In this paper, we introduce a novel approach called "temporal encoder embedding" that can efficiently embed large amounts of graph data with linear complexity. We apply this method to an anonymized time-series communication network from a large organization spanning 2019-2020, consisting of over 100 thousand vertices and 80 million edges. Our method embeds the data within 10 seconds on a standard computer and enables the detection of communication pattern shifts for individual vertices, vertex communities, and the overall graph structure. Through supporting theory and synthesis studies, we demonstrate the theoretical soundness of our approach under random graph models and its numerical effectiveness through simulation studies.
Synergistic Graph Fusion via Encoder Embedding
Mar 31, 2023In this paper, we introduce a novel approach to multi-graph embedding called graph fusion encoder embedding. The method is designed to work with multiple graphs that share a common vertex set. Under the supervised learning setting, we show that the resulting embedding exhibits a surprising yet highly desirable "synergistic effect": for sufficiently large vertex size, the vertex classification accuracy always benefits from additional graphs. We provide a mathematical proof of this effect under the stochastic block model, and identify the necessary and sufficient condition for asymptotically perfect classification. The simulations and real data experiments confirm the superiority of the proposed method, which consistently outperforms recent benchmark methods in classification.