 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing open-domain question answering with graph-based retrieval augmented generation
Mar 04, 2025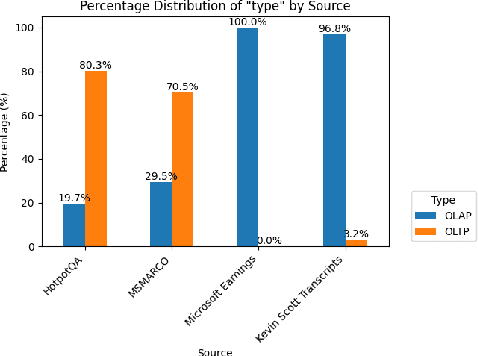
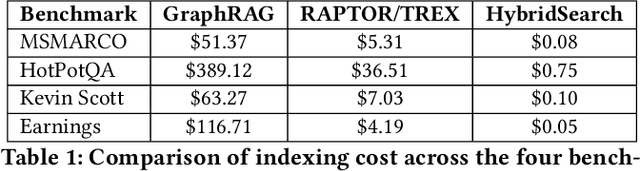
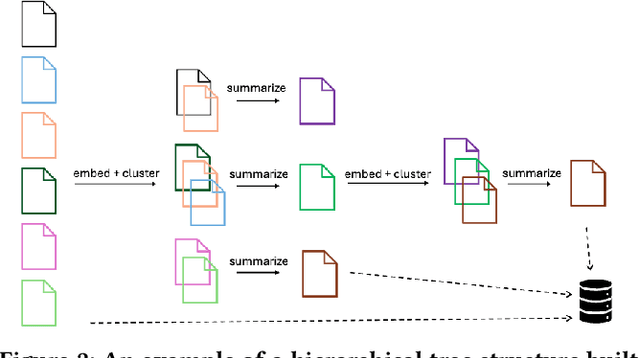
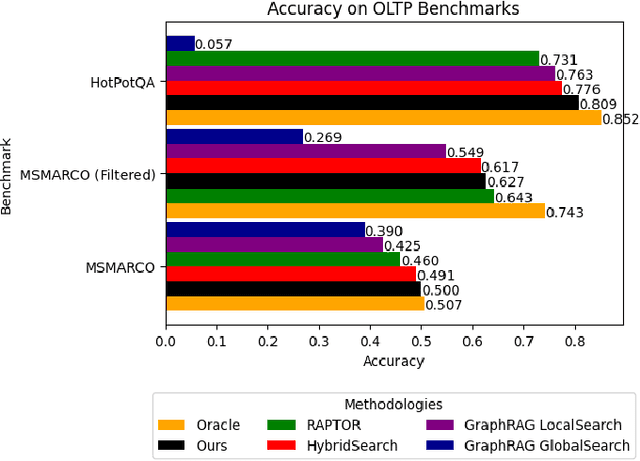
In this work, we benchmark various graph-based retrieval-augmented generation (RAG) systems across a broad spectrum of query types, including OLTP-style (fact-based) and OLAP-style (thematic) queries, to address the complex demands of open-domain question answering (QA). Traditional RAG methods often fall short in handling nuanced, multi-document synthesis tasks. By structuring knowledge as graphs, we can facilitate the retrieval of context that captures greater semantic depth and enhances language model operations. We explore graph-based RAG methodologies and introduce TREX, a novel, cost-effective alternative that combines graph-based and vector-based retrieval techniques. Our benchmarking across four diverse datasets highlights the strengths of different RAG methodologies, demonstrates TREX's ability to handle multiple open-domain QA types, and reveals the limitations of current evaluation methods. In a real-world technical support case study, we demonstrate how TREX solutions can surpass conventional vector-based RAG in efficiently synthesizing data from heterogeneous sources. Our findings underscore the potential of augmenting large language models with advanced retrieval and orchestration capabilities, advancing scalable, graph-based AI solutions.
Sibyl: Forecasting Time-Evolving Query Workloads
Jan 08, 2024Database systems often rely on historical query traces to perform workload-based performance tuning. However, real production workloads are time-evolving, making historical queries ineffective for optimizing future workloads. To address this challenge, we propose SIBYL, an end-to-end machine learning-based framework that accurately forecasts a sequence of future queries, with the entire query statements, in various prediction windows. Drawing insights from real-workloads, we propose template-based featurization techniques and develop a stacked-LSTM with an encoder-decoder architecture for accurate forecasting of query workloads. We also develop techniques to improve forecasting accuracy over large prediction windows and achieve high scalability over large workloads with high variability in arrival rates of queries. Finally, we propose techniques to handle workload drifts. Our evaluation on four real workloads demonstrates that SIBYL can forecast workloads with an $87.3\%$ median F1 score, and can result in $1.7\times$ and $1.3\times$ performance improvement when applied to materialized view selection and index selection applications, respectively.
MotherNet: A Foundational Hypernetwork for Tabular Classification
Dec 14, 2023The advent of Foundation Models is transforming machine learning across many modalities (e.g., language, images, videos) with prompt engineering replacing training in many settings. Recent work on tabular data (e.g., TabPFN) hints at a similar opportunity to build Foundation Models for classification for numerical data. In this paper, we go one step further and propose a hypernetwork architecture that we call MotherNet, trained on millions of classification tasks, that, once prompted with a never-seen-before training set generates the weights of a trained ``child'' neural-network. Like other Foundation Models, MotherNet replaces training on specific datasets with in-context learning through a single forward pass. In contrast to existing hypernetworks that were either task-specific or trained for relatively constraint multi-task settings, MotherNet is trained to generate networks to perform multiclass classification on arbitrary tabular datasets without any dataset specific gradient descent. The child network generated by MotherNet using in-context learning outperforms neural networks trained using gradient descent on small datasets, and is competitive with predictions by TabPFN and standard ML methods like Gradient Boosting. Unlike a direct application of transformer models like TabPFN, MotherNet generated networks are highly efficient at inference time. This methodology opens up a new approach to building predictive models on tabular data that is both efficient and robust, without any dataset-specific training.
The Tensor Data Platform: Towards an AI-centric Database System
Nov 04, 2022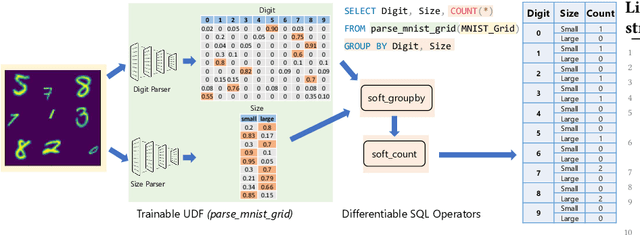
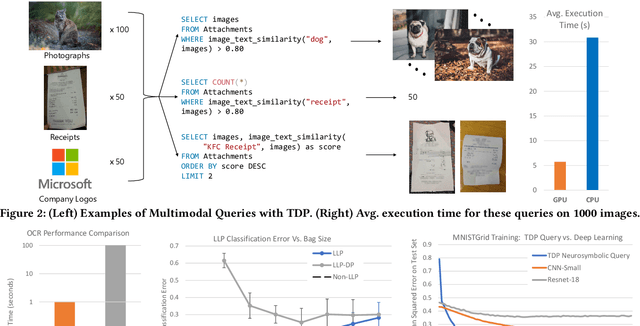
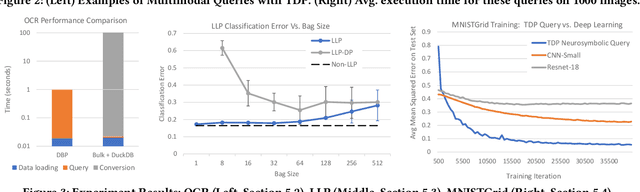
Database engines have historically absorbed many of the innovations in data processing, adding features to process graph data, XML, object oriented, and text among many others. In this paper, we make the case that it is time to do the same for AI -- but with a twist! While existing approaches have tried to achieve this by integrating databases with external ML tools, in this paper we claim that achieving a truly AI-centric database requires moving the DBMS engine, at its core, from a relational to a tensor abstraction. This allows us to: (1) support multi-modal data processing such as images, videos, audio, text as well as relational; (2) leverage the wellspring of innovation in HW and runtimes for tensor computation; and (3) exploit automatic differentiation to enable a novel class of "trainable" queries that can learn to perform a task. To support the above scenarios, we introduce TDP: a system that builds upon our prior work mapping relational queries to tensors. Thanks to a tighter integration with the tensor runtime, TDP is able to provide a broader coverage of new emerging scenarios requiring access to multi-modal data and automatic differentiation.
Query Processing on Tensor Computation Runtimes
Mar 03, 2022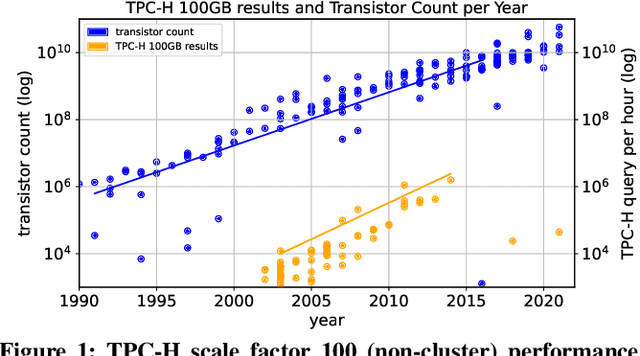

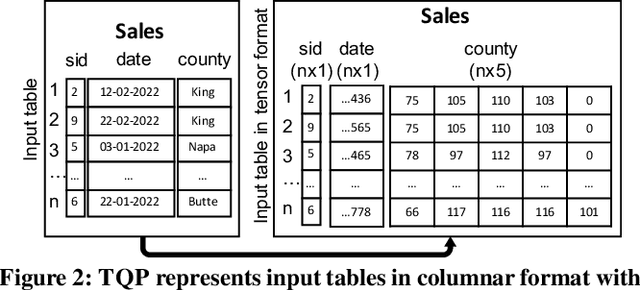
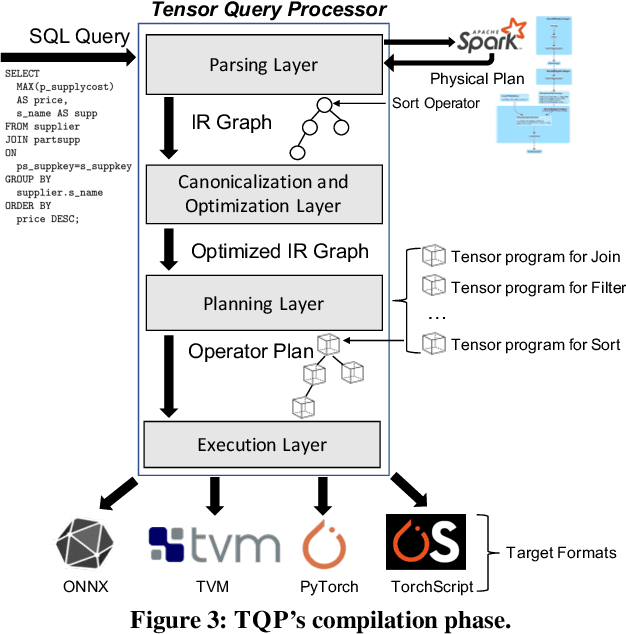
The huge demand for computation in artificial intelligence (AI) is driving unparalleled investments in new hardware and software systems for AI. This leads to an explosion in the number of specialized hardware devices, which are now part of the offerings of major cloud providers. Meanwhile, by hiding the low-level complexity through a tensor-based interface, tensor computation runtimes (TCRs) such as PyTorch allow data scientists to efficiently exploit the exciting capabilities offered by the new hardware. In this paper, we explore how databases can ride the wave of innovation happening in the AI space. Specifically, we present Tensor Query Processor (TQP): a SQL query processor leveraging the tensor interface of TCRs. TQP is able to efficiently run the full TPC-H benchmark by implementing novel algorithms for executing relational operators on the specialized tensor routines provided by TCRs. Meanwhile, TQP can target various hardware while only requiring a fraction of the usual development effort. Experiments show that TQP can improve query execution time by up to 20x over CPU-only systems, and up to 5x over specialized GPU solutions. Finally, TQP can accelerate queries mixing ML predictions and SQL end-to-end, and deliver up to 5x speedup over CPU baselines.
A Tensor Compiler for Unified Machine Learning Prediction Serving
Oct 19, 2020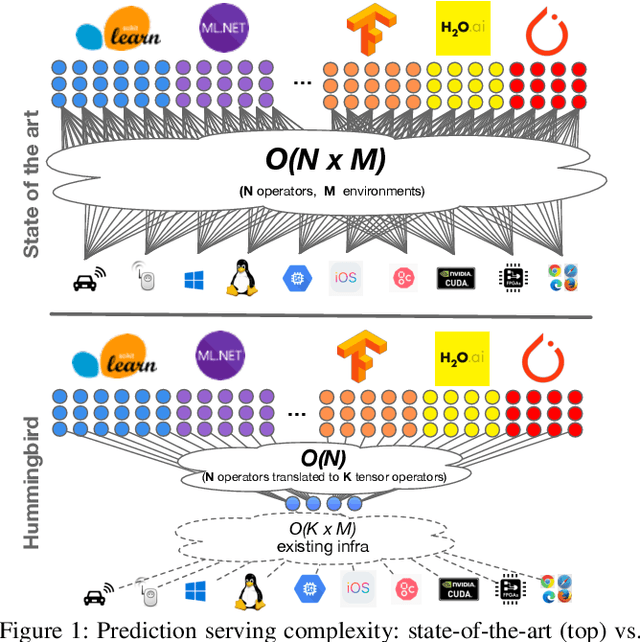

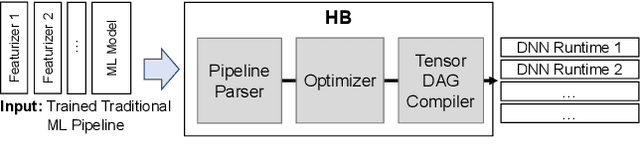

Machine Learning (ML) adoption in the enterprise requires simpler and more efficient software infrastructure---the bespoke solutions typical in large web companies are simply untenable. Model scoring, the process of obtaining predictions from a trained model over new data, is a primary contributor to infrastructure complexity and cost as models are trained once but used many times. In this paper we propose HUMMINGBIRD, a novel approach to model scoring, which compiles featurization operators and traditional ML models (e.g., decision trees) into a small set of tensor operations. This approach inherently reduces infrastructure complexity and directly leverages existing investments in Neural Network compilers and runtimes to generate efficient computations for both CPU and hardware accelerators. Our performance results are intriguing: despite replacing imperative computations (e.g., tree traversals) with tensor computation abstractions, HUMMINGBIRD is competitive and often outperforms hand-crafted kernels on micro-benchmarks on both CPU and GPU, while enabling seamless end-to-end acceleration of ML pipelines. We have released HUMMINGBIRD as open source.
Seagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020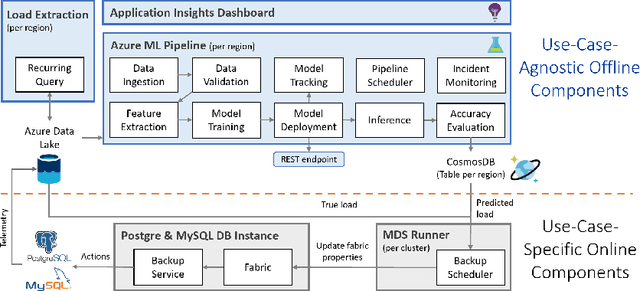
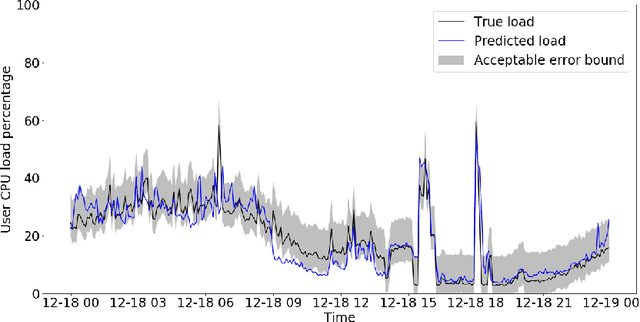
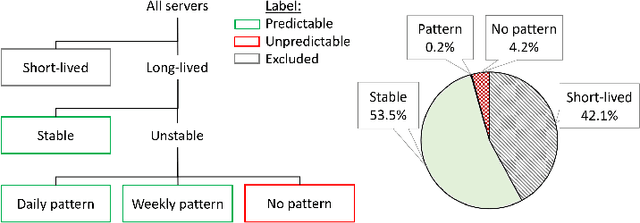
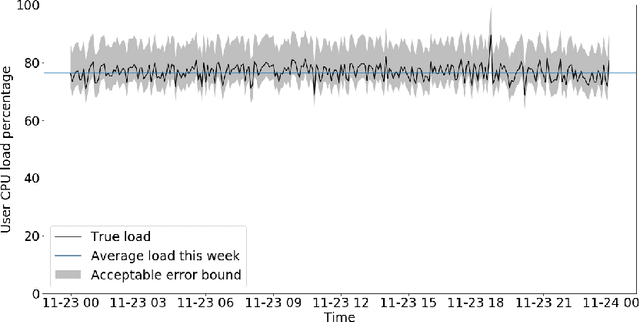
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.
MLOS: An Infrastructure for Automated Software Performance Engineering
Jun 04, 2020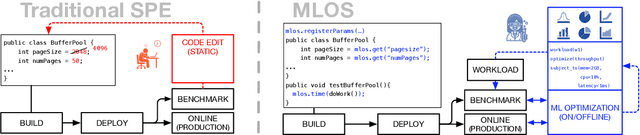
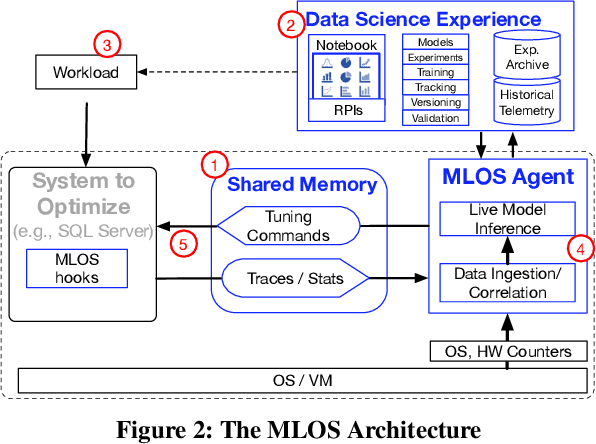
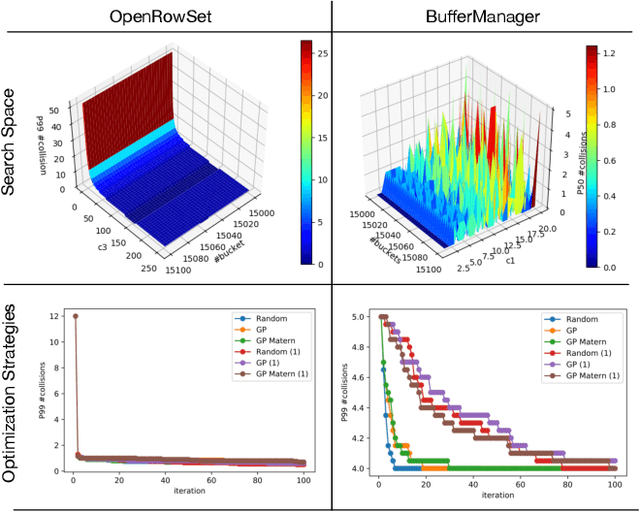
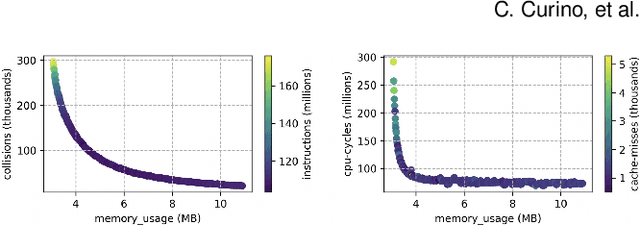
Developing modern systems software is a complex task that combines business logic programming and Software Performance Engineering (SPE). The later is an experimental and labor-intensive activity focused on optimizing the system for a given hardware, software, and workload (hw/sw/wl) context. Today's SPE is performed during build/release phases by specialized teams, and cursed by: 1) lack of standardized and automated tools, 2) significant repeated work as hw/sw/wl context changes, 3) fragility induced by a "one-size-fit-all" tuning (where improvements on one workload or component may impact others). The net result: despite costly investments, system software is often outside its optimal operating point - anecdotally leaving 30% to 40% of performance on the table. The recent developments in Data Science (DS) hints at an opportunity: combining DS tooling and methodologies with a new developer experience to transform the practice of SPE. In this paper we present: MLOS, an ML-powered infrastructure and methodology to democratize and automate Software Performance Engineering. MLOS enables continuous, instance-level, robust, and trackable systems optimization. MLOS is being developed and employed within Microsoft to optimize SQL Server performance. Early results indicated that component-level optimizations can lead to 20%-90% improvements when custom-tuning for a specific hw/sw/wl, hinting at a significant opportunity. However, several research challenges remain that will require community involvement. To this end, we are in the process of open-sourcing the MLOS core infrastructure, and we are engaging with academic institutions to create an educational program around Software 2.0 and MLOS ideas.
Data Science through the looking glass and what we found there
Dec 19, 2019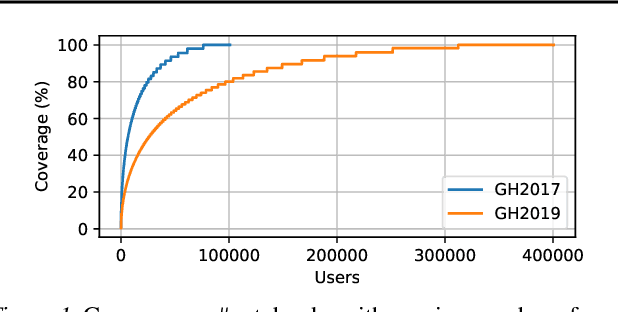
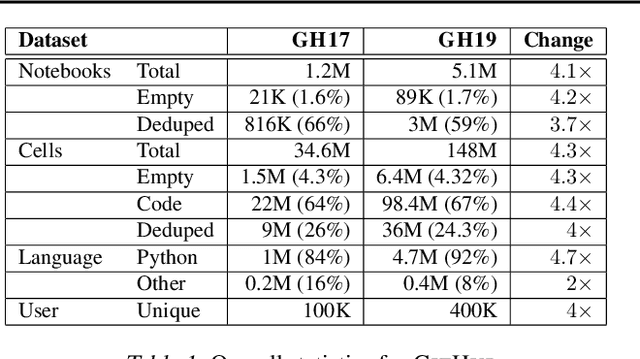
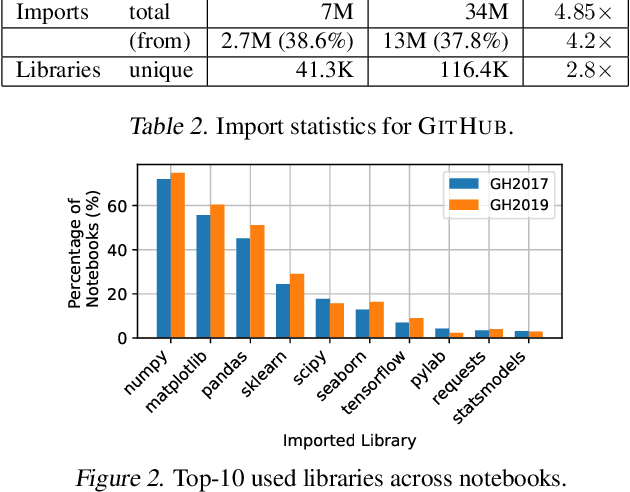
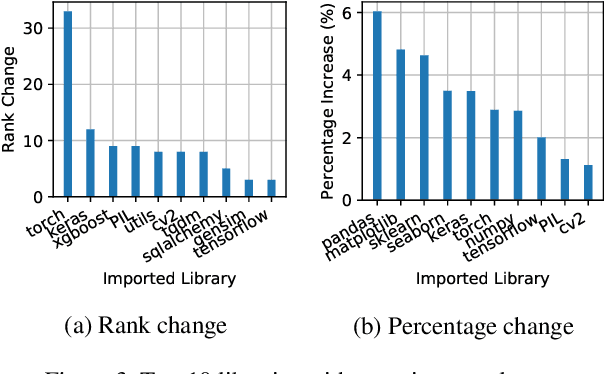
The recent success of machine learning (ML) has led to an explosive growth both in terms of new systems and algorithms built in industry and academia, and new applications built by an ever-growing community of data science (DS) practitioners. This quickly shifting panorama of technologies and applications is challenging for builders and practitioners alike to follow. In this paper, we set out to capture this panorama through a wide-angle lens, by performing the largest analysis of DS projects to date, focusing on questions that can help determine investments on either side. Specifically, we download and analyze: (a) over 6M Python notebooks publicly available on GITHUB, (b) over 2M enterprise DS pipelines developed within COMPANYX, and (c) the source code and metadata of over 900 releases from 12 important DS libraries. The analysis we perform ranges from coarse-grained statistical characterizations to analysis of library imports, pipelines, and comparative studies across datasets and time. We report a large number of measurements for our readers to interpret, and dare to draw a few (actionable, yet subjective) conclusions on (a) what systems builders should focus on to better serve practitioners, and (b) what technologies should practitioners bet on given current trends. We plan to automate this analysis and release associated tools and results periodically.
Extending Relational Query Processing with ML Inference
Nov 01, 2019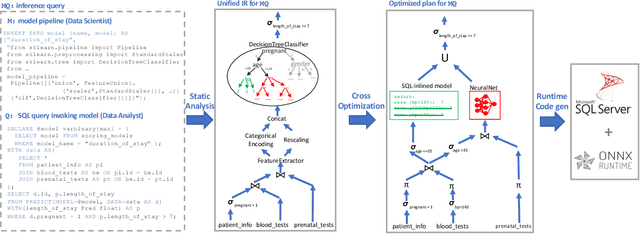

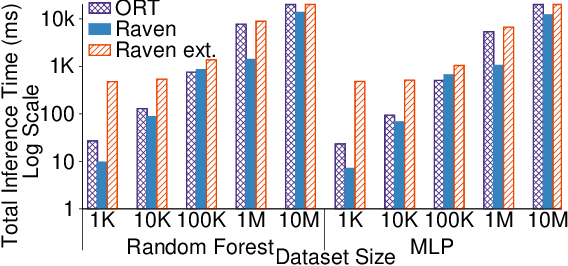
The broadening adoption of machine learning in the enterprise is increasing the pressure for strict governance and cost-effective performance, in particular for the common and consequential steps of model storage and inference. The RDBMS provides a natural starting point, given its mature infrastructure for fast data access and processing, along with support for enterprise features (e.g., encryption, auditing, high-availability). To take advantage of all of the above, we need to address a key concern: Can in-RDBMS scoring of ML models match (outperform?) the performance of dedicated frameworks? We answer the above positively by building Raven, a system that leverages native integration of ML runtimes (i.e., ONNX Runtime) deep within SQL Server, and a unified intermediate representation (IR) to enable advanced cross-optimizations between ML and DB operators. In this optimization space, we discover the most exciting research opportunities that combine DB/Compiler/ML thinking. Our initial evaluation on real data demonstrates performance gains of up to 5.5x from the native integration of ML in SQL Server, and up to 24x from cross-optimizations--we will demonstrate Raven live during the conference talk.