 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Eval Judge: Towards a General Agentic Framework for Task Completion Evaluation
Aug 07, 2025



The increasing adoption of foundation models as agents across diverse domains necessitates a robust evaluation framework. Current methods, such as LLM-as-a-Judge, focus only on final outputs, overlooking the step-by-step reasoning that drives agentic decision-making. Meanwhile, existing Agent-as-a-Judge systems, where one agent evaluates another's task completion, are typically designed for narrow, domain-specific settings. To address this gap, we propose a generalizable, modular framework for evaluating agent task completion independent of the task domain. The framework emulates human-like evaluation by decomposing tasks into sub-tasks and validating each step using available information, such as the agent's output and reasoning. Each module contributes to a specific aspect of the evaluation process, and their outputs are aggregated to produce a final verdict on task completion. We validate our framework by evaluating the Magentic-One Actor Agent on two benchmarks, GAIA and BigCodeBench. Our Judge Agent predicts task success with closer agreement to human evaluations, achieving 4.76% and 10.52% higher alignment accuracy, respectively, compared to the GPT-4o based LLM-as-a-Judge baseline. This demonstrates the potential of our proposed general-purpose evaluation framework.
Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting
Aug 18, 2024



Hand-crafting high quality prompts to optimize the performance of language models is a complicated and labor-intensive process. Furthermore, when migrating to newer, smaller, or weaker models (possibly due to latency or cost gains), prompts need to be updated to re-optimize the task performance. We propose Concept Distillation (CD), an automatic prompt optimization technique for enhancing weaker models on complex tasks. CD involves: (1) collecting mistakes made by weak models with a base prompt (initialization), (2) using a strong model to generate reasons for these mistakes and create rules/concepts for weak models (induction), and (3) filtering these rules based on validation set performance and integrating them into the base prompt (deduction/verification). We evaluated CD on NL2Code and mathematical reasoning tasks, observing significant performance boosts for small and weaker language models. Notably, Mistral-7B's accuracy on Multi-Arith increased by 20%, and Phi-3-mini-3.8B's accuracy on HumanEval rose by 34%. Compared to other automated methods, CD offers an effective, cost-efficient strategy for improving weak models' performance on complex tasks and enables seamless workload migration across different language models without compromising performance.
SLATE: A Sequence Labeling Approach for Task Extraction from Free-form Inked Content
Nov 17, 2022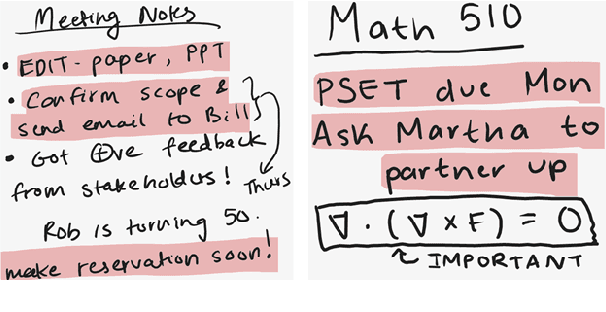
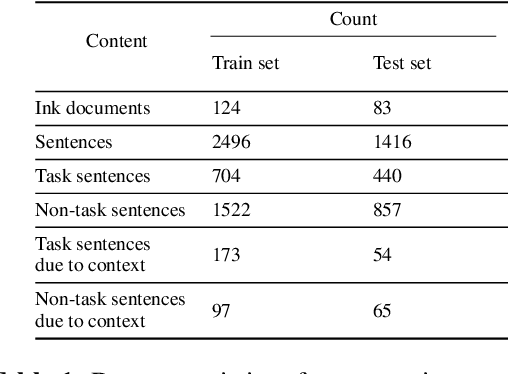
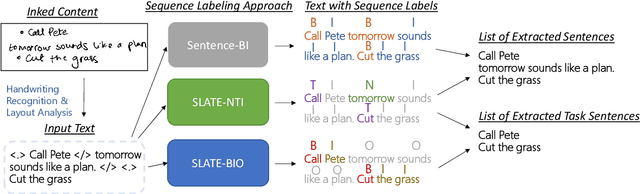
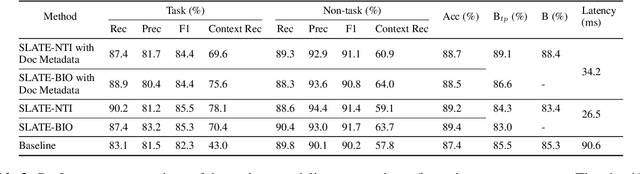
We present SLATE, a sequence labeling approach for extracting tasks from free-form content such as digitally handwritten (or "inked") notes on a virtual whiteboard. Our approach allows us to create a single, low-latency model to simultaneously perform sentence segmentation and classification of these sentences into task/non-task sentences. SLATE greatly outperforms a baseline two-model (sentence segmentation followed by classification model) approach, achieving a task F1 score of 84.4%, a sentence segmentation (boundary similarity) score of 88.4% and three times lower latency compared to the baseline. Furthermore, we provide insights into tackling challenges of performing NLP on the inking domain. We release both our code and dataset for this novel task.
Semi-Supervised Few-Shot Intent Classification and Slot Filling
Sep 17, 2021
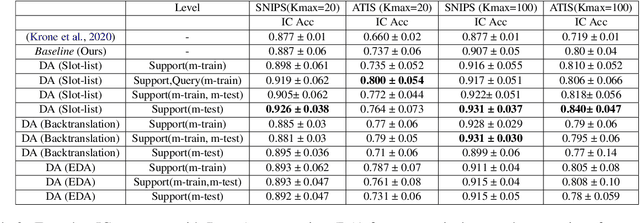
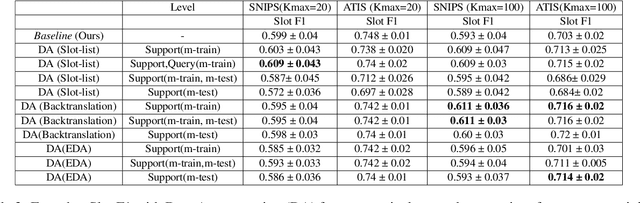

Intent classification (IC) and slot filling (SF) are two fundamental tasks in modern Natural Language Understanding (NLU) systems. Collecting and annotating large amounts of data to train deep learning models for such systems is not scalable. This problem can be addressed by learning from few examples using fast supervised meta-learning techniques such as prototypical networks. In this work, we systematically investigate how contrastive learning and unsupervised data augmentation methods can benefit these existing supervised meta-learning pipelines for jointly modelled IC/SF tasks. Through extensive experiments across standard IC/SF benchmarks (SNIPS and ATIS), we show that our proposed semi-supervised approaches outperform standard supervised meta-learning methods: contrastive losses in conjunction with prototypical networks consistently outperform the existing state-of-the-art for both IC and SF tasks, while data augmentation strategies primarily improve few-shot IC by a significant margin.
Seagull: An Infrastructure for Load Prediction and Optimized Resource Allocation
Oct 16, 2020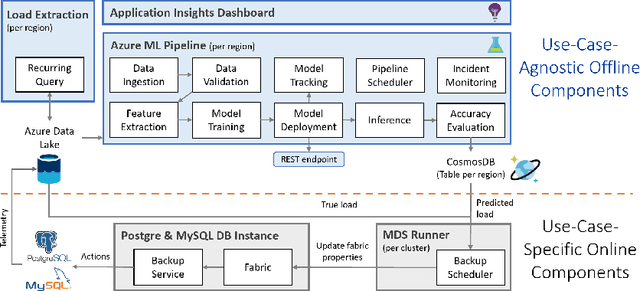
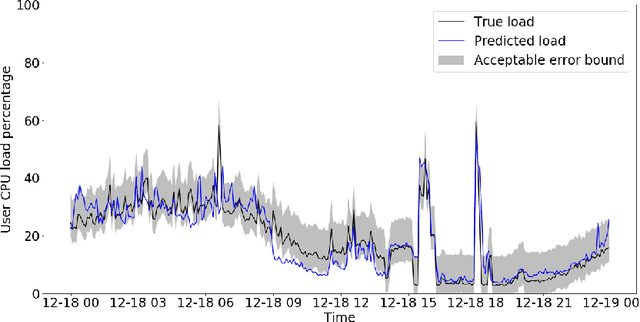
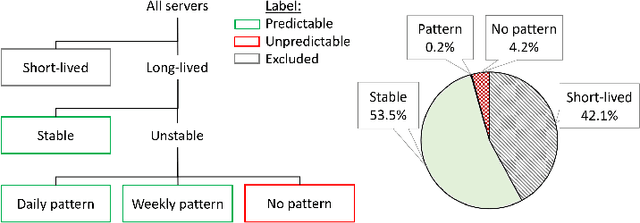
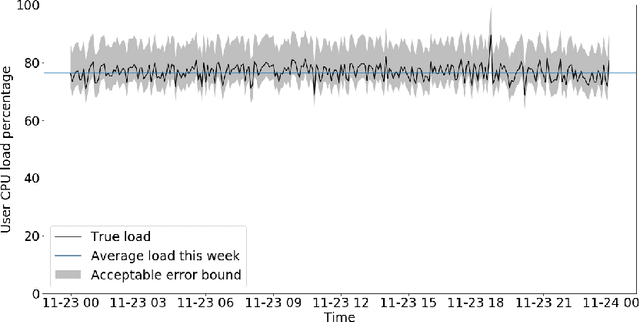
Microsoft Azure is dedicated to guarantee high quality of service to its customers, in particular, during periods of high customer activity, while controlling cost. We employ a Data Science (DS) driven solution to predict user load and leverage these predictions to optimize resource allocation. To this end, we built the Seagull infrastructure that processes per-server telemetry, validates the data, trains and deploys ML models. The models are used to predict customer load per server (24h into the future), and optimize service operations. Seagull continually re-evaluates accuracy of predictions, fallback to previously known good models and triggers alerts as appropriate. We deployed this infrastructure in production for PostgreSQL and MySQL servers across all Azure regions, and applied it to the problem of scheduling server backups during low-load time. This minimizes interference with user-induced load and improves customer experience.