 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Node Representation Interpretation through Relation Coherence
Nov 01, 2024Understanding node representations in graph-based models is crucial for uncovering biases ,diagnosing errors, and building trust in model decisions. However, previous work on explainable AI for node representations has primarily emphasized explanations (reasons for model predictions) rather than interpretations (mapping representations to understandable concepts). Furthermore, the limited research that focuses on interpretation lacks validation, and thus the reliability of such methods is unclear. We address this gap by proposing a novel interpretation method-Node Coherence Rate for Representation Interpretation (NCI)-which quantifies how well different node relations are captured in node representations. We also propose a novel method (IME) to evaluate the accuracy of different interpretation methods. Our experimental results demonstrate that NCI reduces the error of the previous best approach by an average of 39%. We then apply NCI to derive insights about the node representations produced by several graph-based methods and assess their quality in unsupervised settings.
Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting
Aug 18, 2024



Hand-crafting high quality prompts to optimize the performance of language models is a complicated and labor-intensive process. Furthermore, when migrating to newer, smaller, or weaker models (possibly due to latency or cost gains), prompts need to be updated to re-optimize the task performance. We propose Concept Distillation (CD), an automatic prompt optimization technique for enhancing weaker models on complex tasks. CD involves: (1) collecting mistakes made by weak models with a base prompt (initialization), (2) using a strong model to generate reasons for these mistakes and create rules/concepts for weak models (induction), and (3) filtering these rules based on validation set performance and integrating them into the base prompt (deduction/verification). We evaluated CD on NL2Code and mathematical reasoning tasks, observing significant performance boosts for small and weaker language models. Notably, Mistral-7B's accuracy on Multi-Arith increased by 20%, and Phi-3-mini-3.8B's accuracy on HumanEval rose by 34%. Compared to other automated methods, CD offers an effective, cost-efficient strategy for improving weak models' performance on complex tasks and enables seamless workload migration across different language models without compromising performance.
ConvGenVisMo: Evaluation of Conversational Generative Vision Models
May 28, 2023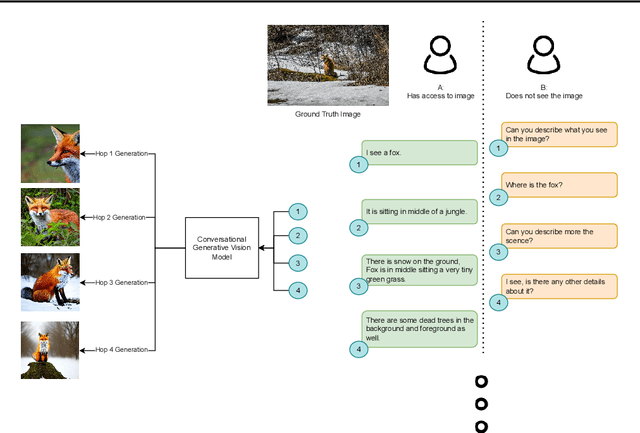
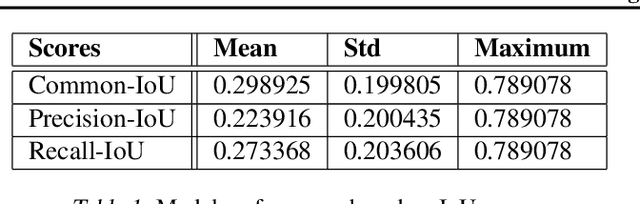

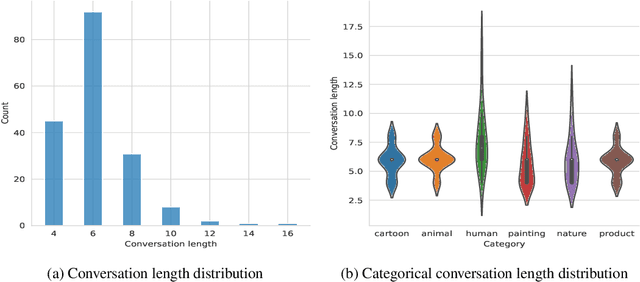
Conversational generative vision models (CGVMs) like Visual ChatGPT (Wu et al., 2023) have recently emerged from the synthesis of computer vision and natural language processing techniques. These models enable more natural and interactive communication between humans and machines, because they can understand verbal inputs from users and generate responses in natural language along with visual outputs. To make informed decisions about the usage and deployment of these models, it is important to analyze their performance through a suitable evaluation framework on realistic datasets. In this paper, we present ConvGenVisMo, a framework for the novel task of evaluating CGVMs. ConvGenVisMo introduces a new benchmark evaluation dataset for this task, and also provides a suite of existing and new automated evaluation metrics to evaluate the outputs. All ConvGenVisMo assets, including the dataset and the evaluation code, will be made available publicly on GitHub.
Generating Emotionally Aligned Responses in Dialogues using Affect Control Theory
Apr 16, 2020
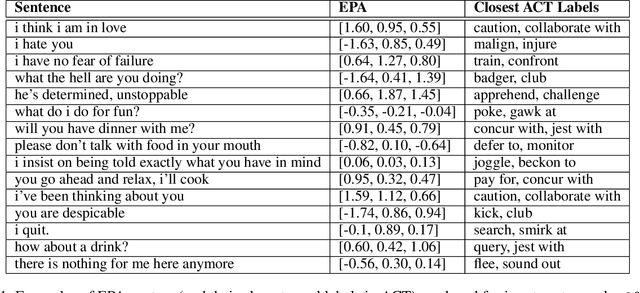
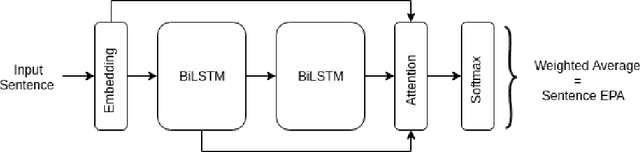

State-of-the-art neural dialogue systems excel at syntactic and semantic modelling of language, but often have a hard time establishing emotional alignment with the human interactant during a conversation. In this work, we bring Affect Control Theory (ACT), a socio-mathematical model of emotions for human-human interactions, to the neural dialogue generation setting. ACT makes predictions about how humans respond to emotional stimuli in social situations. Due to this property, ACT and its derivative probabilistic models have been successfully deployed in several applications of Human-Computer Interaction, including empathetic tutoring systems, assistive healthcare devices and two-person social dilemma games. We investigate how ACT can be used to develop affect-aware neural conversational agents, which produce emotionally aligned responses to prompts and take into consideration the affective identities of the interactants.
Progressive Memory Banks for Incremental Domain Adaptation
Nov 01, 2018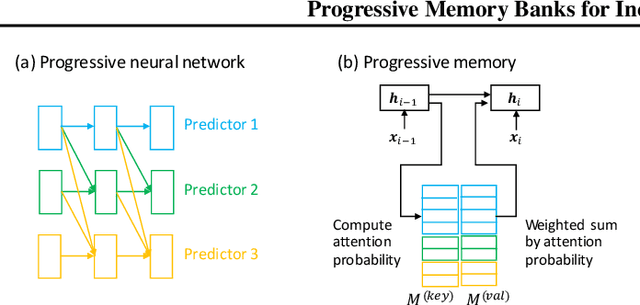
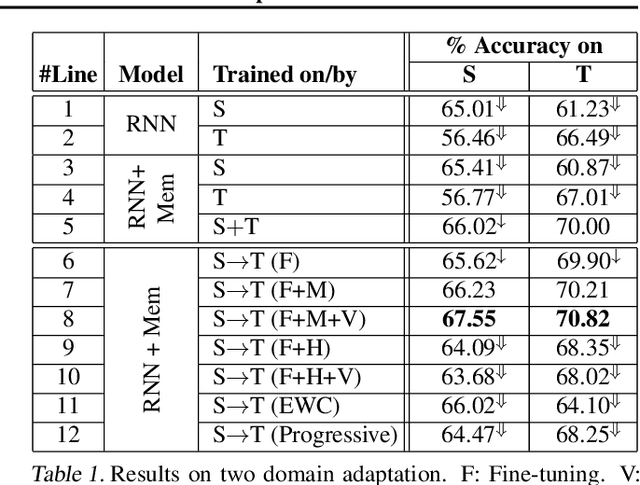
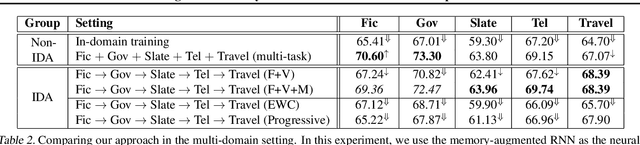
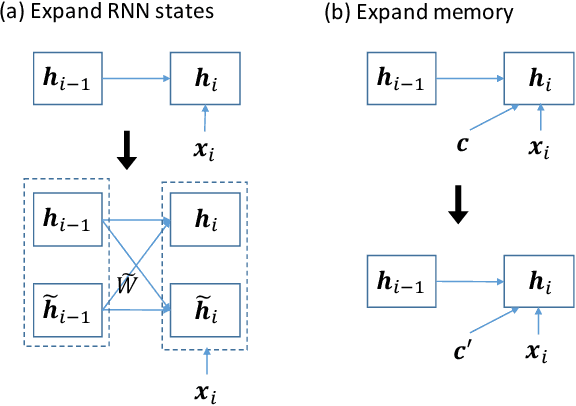
This paper addresses the problem of incremental domain adaptation (IDA). We assume each domain comes one after another, and that we could only access data in the current domain. The goal of IDA is to build a unified model performing well on all the domains that we have encountered. We propose to augment a recurrent neural network (RNN) with a directly parameterized memory bank, which is retrieved by an attention mechanism at each step of RNN transition. The memory bank provides a natural way of IDA: when adapting our model to a new domain, we progressively add new slots to the memory bank, which increases the number of parameters, and thus the model capacity. We learn the new memory slots and fine-tune existing parameters by back-propagation. Experimental results show that our approach achieves significantly better performance than fine-tuning alone, which suffers from the catastrophic forgetting problem. Compared with expanding hidden states, our approach is more robust for old domains, shown by both empirical and theoretical results. Our model also outperforms previous work of IDA including elastic weight consolidation (EWC) and the progressive neural network.
Affective Neural Response Generation
Sep 12, 2017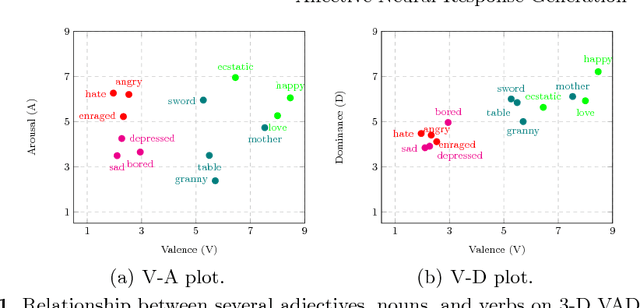
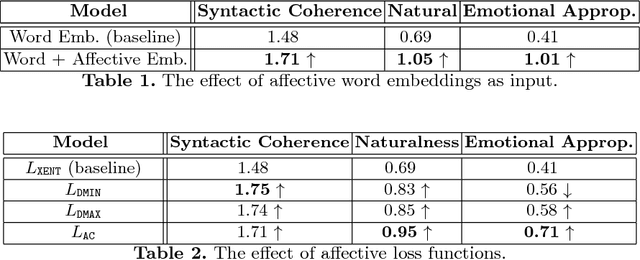
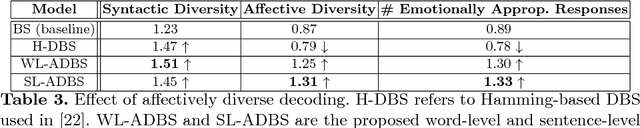
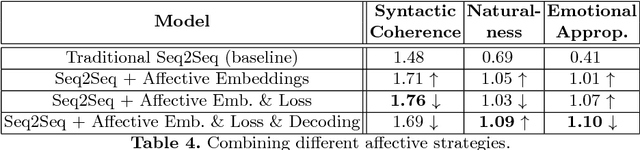
Existing neural conversational models process natural language primarily on a lexico-syntactic level, thereby ignoring one of the most crucial components of human-to-human dialogue: its affective content. We take a step in this direction by proposing three novel ways to incorporate affective/emotional aspects into long short term memory (LSTM) encoder-decoder neural conversation models: (1) affective word embeddings, which are cognitively engineered, (2) affect-based objective functions that augment the standard cross-entropy loss, and (3) affectively diverse beam search for decoding. Experiments show that these techniques improve the open-domain conversational prowess of encoder-decoder networks by enabling them to produce emotionally rich responses that are more interesting and natural.
Deep Active Learning for Dialogue Generation
Jun 16, 2017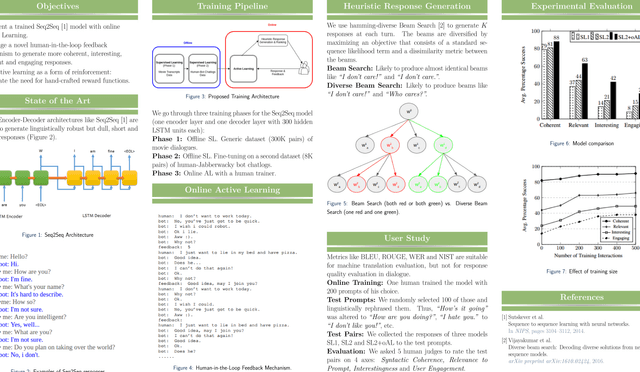
We propose an online, end-to-end, neural generative conversational model for open-domain dialogue. It is trained using a unique combination of offline two-phase supervised learning and online human-in-the-loop active learning. While most existing research proposes offline supervision or hand-crafted reward functions for online reinforcement, we devise a novel interactive learning mechanism based on hamming-diverse beam search for response generation and one-character user-feedback at each step. Experiments show that our model inherently promotes the generation of semantically relevant and interesting responses, and can be used to train agents with customized personas, moods and conversational styles.
Automatic Extraction of Causal Relations from Natural Language Texts: A Comprehensive Survey
May 25, 2016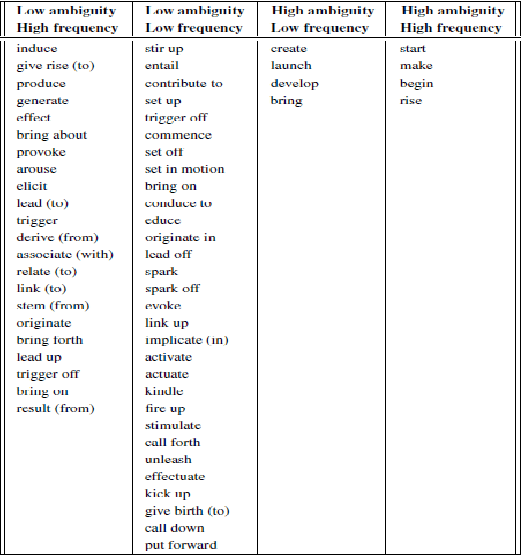
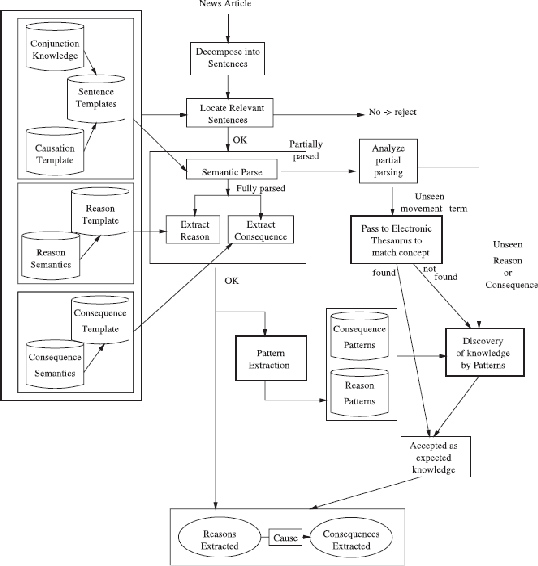

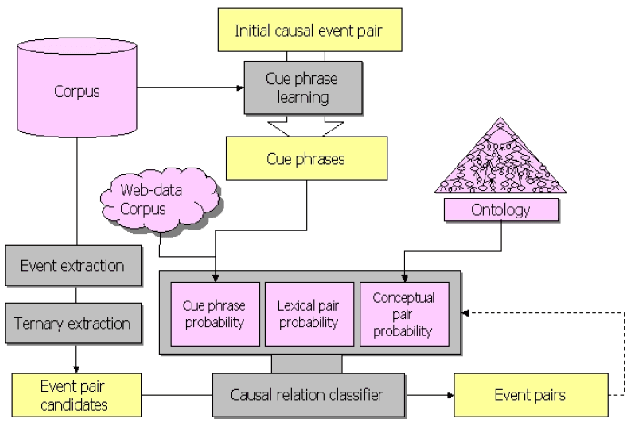
Automatic extraction of cause-effect relationships from natural language texts is a challenging open problem in Artificial Intelligence. Most of the early attempts at its solution used manually constructed linguistic and syntactic rules on small and domain-specific data sets. However, with the advent of big data, the availability of affordable computing power and the recent popularization of machine learning, the paradigm to tackle this problem has slowly shifted. Machines are now expected to learn generic causal extraction rules from labelled data with minimal supervision, in a domain independent-manner. In this paper, we provide a comprehensive survey of causal relation extraction techniques from both paradigms, and analyse their relative strengths and weaknesses, with recommendations for future work.
Yelp Dataset Challenge: Review Rating Prediction
May 17, 2016
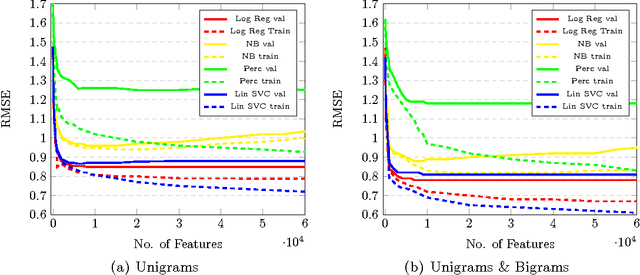
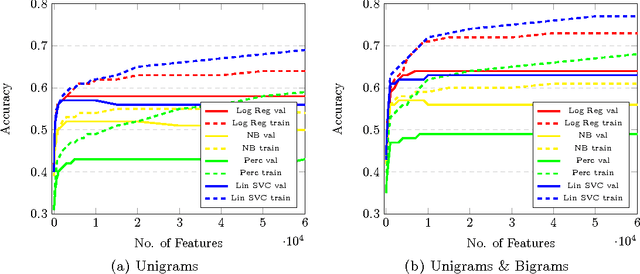
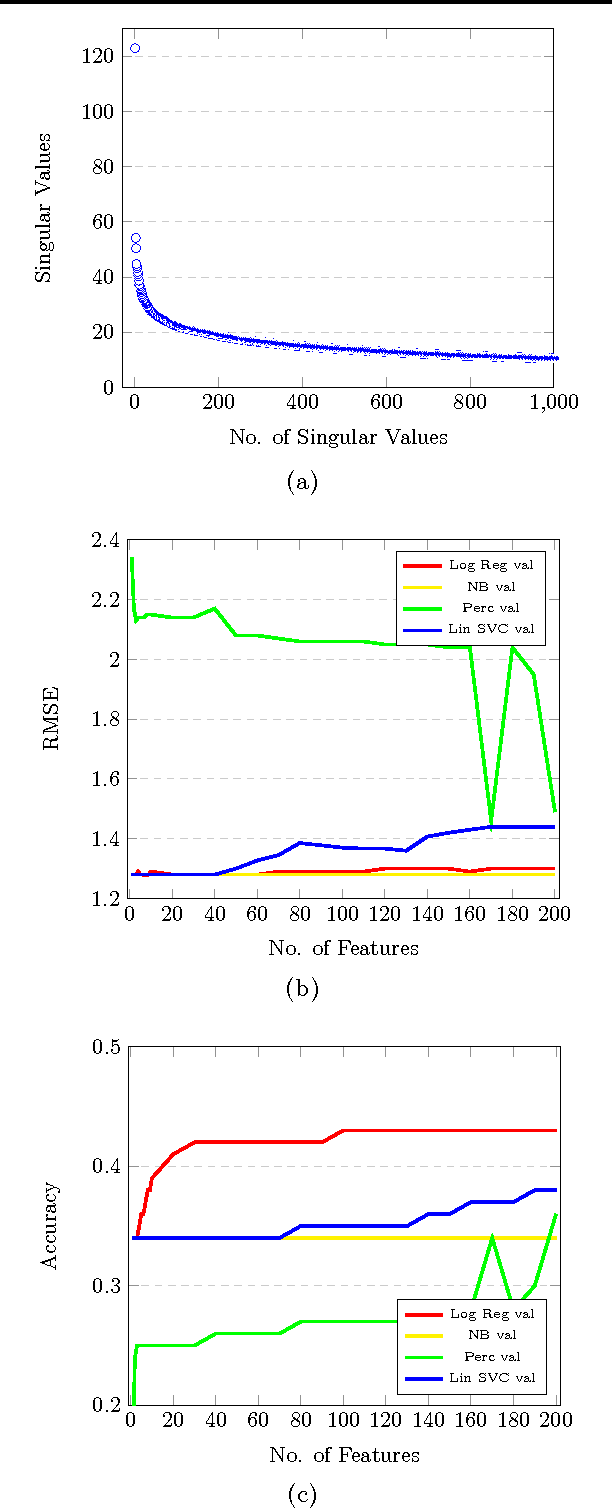
Review websites, such as TripAdvisor and Yelp, allow users to post online reviews for various businesses, products and services, and have been recently shown to have a significant influence on consumer shopping behaviour. An online review typically consists of free-form text and a star rating out of 5. The problem of predicting a user's star rating for a product, given the user's text review for that product, is called Review Rating Prediction and has lately become a popular, albeit hard, problem in machine learning. In this paper, we treat Review Rating Prediction as a multi-class classification problem, and build sixteen different prediction models by combining four feature extraction methods, (i) unigrams, (ii) bigrams, (iii) trigrams and (iv) Latent Semantic Indexing, with four machine learning algorithms, (i) logistic regression, (ii) Naive Bayes classification, (iii) perceptrons, and (iv) linear Support Vector Classification. We analyse the performance of each of these sixteen models to come up with the best model for predicting the ratings from reviews. We use the dataset provided by Yelp for training and testing the models.