 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvGenVisMo: Evaluation of Conversational Generative Vision Models
May 28, 2023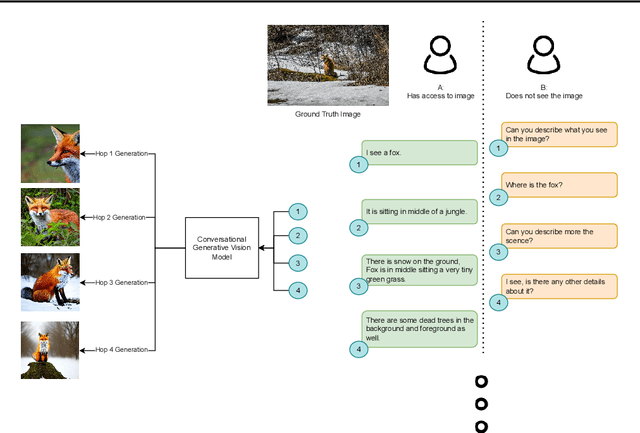
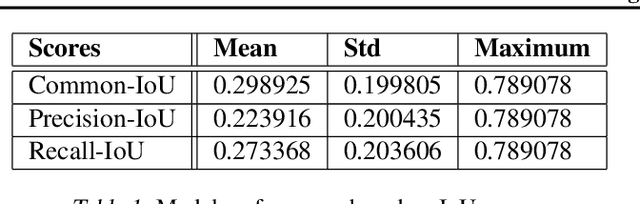

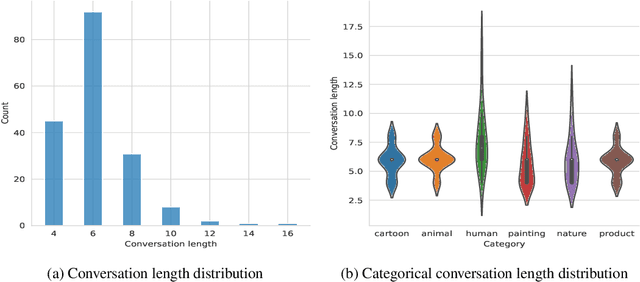
Conversational generative vision models (CGVMs) like Visual ChatGPT (Wu et al., 2023) have recently emerged from the synthesis of computer vision and natural language processing techniques. These models enable more natural and interactive communication between humans and machines, because they can understand verbal inputs from users and generate responses in natural language along with visual outputs. To make informed decisions about the usage and deployment of these models, it is important to analyze their performance through a suitable evaluation framework on realistic datasets. In this paper, we present ConvGenVisMo, a framework for the novel task of evaluating CGVMs. ConvGenVisMo introduces a new benchmark evaluation dataset for this task, and also provides a suite of existing and new automated evaluation metrics to evaluate the outputs. All ConvGenVisMo assets, including the dataset and the evaluation code, will be made available publicly on GitHub.
Automating Speedrun Routing: Overview and Vision
Jun 02, 2021Speedrunning in general means to play a video game fast, i.e. using all means at one's disposal to achieve a given goal in the least amount of time possible. To do so, a speedrun must be planned in advance, or routed, as it is referred to by the community. This paper focuses on discovering challenges and defining models needed when trying to approach the problem of routing algorithmically. It provides an overview of relevant speedrunning literature, extracting vital information and formulating criticism. Important categorizations are pointed out and a nomenclature is build to support professional discussion. Different concepts of graph representations are presented and their potential is discussed with regard to solving the speedrun routing optimization problem. Visions both for problem modeling as well as solving are presented and assessed regarding suitability and expected challenges. This results in a vision of potential solutions and what will be addressed in the future.
Multitask Learning for Grapheme-to-Phoneme Conversion of Anglicisms in German Speech Recognition
May 26, 2021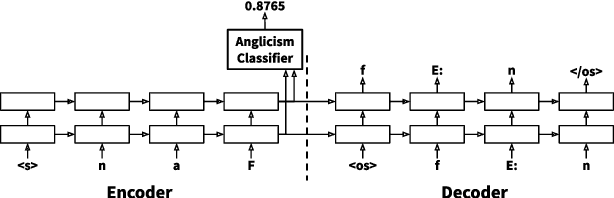

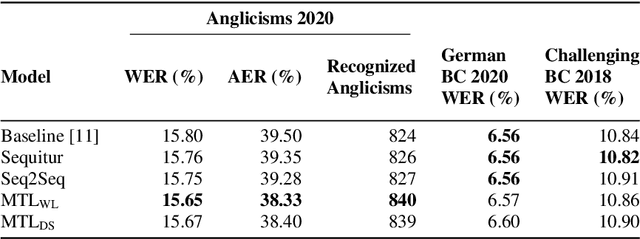

Loanwords, such as Anglicisms, are a challenge in German speech recognition. Due to their irregular pronunciation compared to native German words, automatically generated pronunciation dictionaries often include faulty phoneme sequences for Anglicisms. In this work, we propose a multitask sequence-to-sequence approach for grapheme-to-phoneme conversion to improve the phonetization of Anglicisms. We extended a grapheme-to-phoneme model with a classifier to distinguish Anglicisms from native German words. With this approach, the model learns to generate pronunciations differently depending on the classification result. We used our model to create supplementary Anglicism pronunciation dictionaries that are added to an existing German speech recognition model. Tested on a dedicated Anglicism evaluation set, we improved the recognition of Anglicisms compared to a baseline model, reducing the word error rate by 1 % and the Anglicism error rate by 3 %. We show that multitask learning can help solving the challenge of loanwords in German speech recognition.