 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvGenVisMo: Evaluation of Conversational Generative Vision Models
Paper and Code
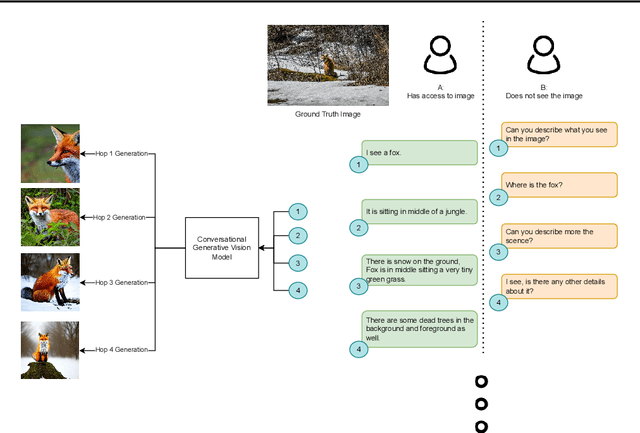
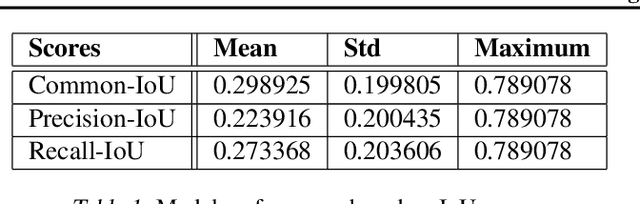

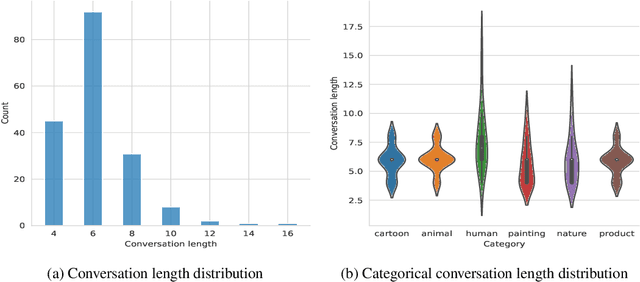
Conversational generative vision models (CGVMs) like Visual ChatGPT (Wu et al., 2023) have recently emerged from the synthesis of computer vision and natural language processing techniques. These models enable more natural and interactive communication between humans and machines, because they can understand verbal inputs from users and generate responses in natural language along with visual outputs. To make informed decisions about the usage and deployment of these models, it is important to analyze their performance through a suitable evaluation framework on realistic datasets. In this paper, we present ConvGenVisMo, a framework for the novel task of evaluating CGVMs. ConvGenVisMo introduces a new benchmark evaluation dataset for this task, and also provides a suite of existing and new automated evaluation metrics to evaluate the outputs. All ConvGenVisMo assets, including the dataset and the evaluation code, will be made available publicly on GitHub.