 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Language Learning through Technology: Introducing a New English-Azerbaijani (Arabic Script) Parallel Corpus
Jul 06, 2024This paper introduces a pioneering English-Azerbaijani (Arabic Script) parallel corpus, designed to bridge the technological gap in language learning and machine translation (MT) for under-resourced languages. Consisting of 548,000 parallel sentences and approximately 9 million words per language, this dataset is derived from diverse sources such as news articles and holy texts, aiming to enhance natural language processing (NLP) applications and language education technology. This corpus marks a significant step forward in the realm of linguistic resources, particularly for Turkic languages, which have lagged in the neural machine translation (NMT) revolution. By presenting the first comprehensive case study for the English-Azerbaijani (Arabic Script) language pair, this work underscores the transformative potential of NMT in low-resource contexts. The development and utilization of this corpus not only facilitate the advancement of machine translation systems tailored for specific linguistic needs but also promote inclusive language learning through technology. The findings demonstrate the corpus's effectiveness in training deep learning MT systems and underscore its role as an essential asset for researchers and educators aiming to foster bilingual education and multilingual communication. This research covers the way for future explorations into NMT applications for languages lacking substantial digital resources, thereby enhancing global language education frameworks. The Python package of our code is available at https://pypi.org/project/chevir-kartalol/, and we also have a website accessible at https://translate.kartalol.com/.
ConvGenVisMo: Evaluation of Conversational Generative Vision Models
May 28, 2023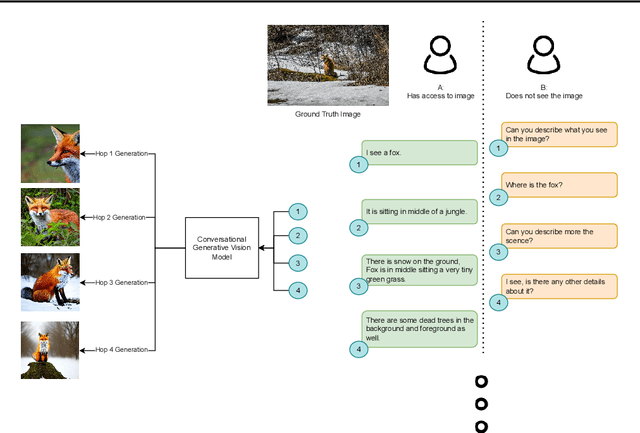
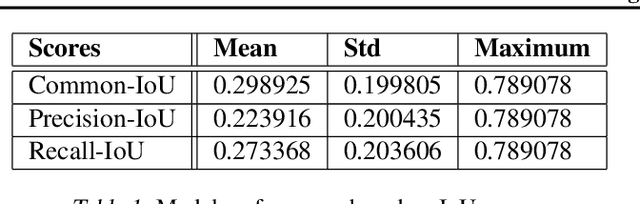

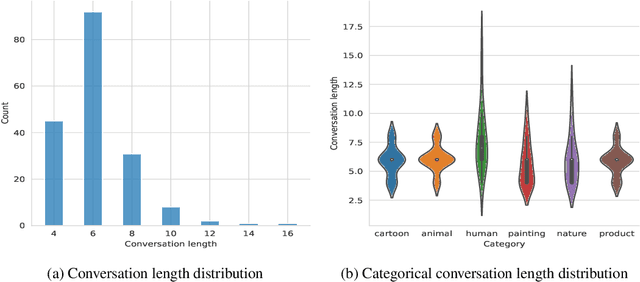
Conversational generative vision models (CGVMs) like Visual ChatGPT (Wu et al., 2023) have recently emerged from the synthesis of computer vision and natural language processing techniques. These models enable more natural and interactive communication between humans and machines, because they can understand verbal inputs from users and generate responses in natural language along with visual outputs. To make informed decisions about the usage and deployment of these models, it is important to analyze their performance through a suitable evaluation framework on realistic datasets. In this paper, we present ConvGenVisMo, a framework for the novel task of evaluating CGVMs. ConvGenVisMo introduces a new benchmark evaluation dataset for this task, and also provides a suite of existing and new automated evaluation metrics to evaluate the outputs. All ConvGenVisMo assets, including the dataset and the evaluation code, will be made available publicly on GitHub.
The state-of-the-art in text-based automatic personality prediction
Oct 04, 2021
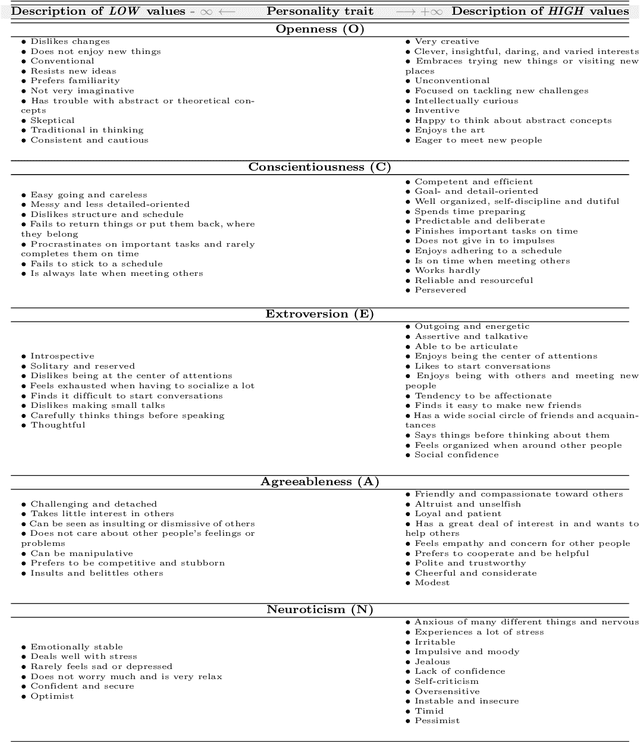
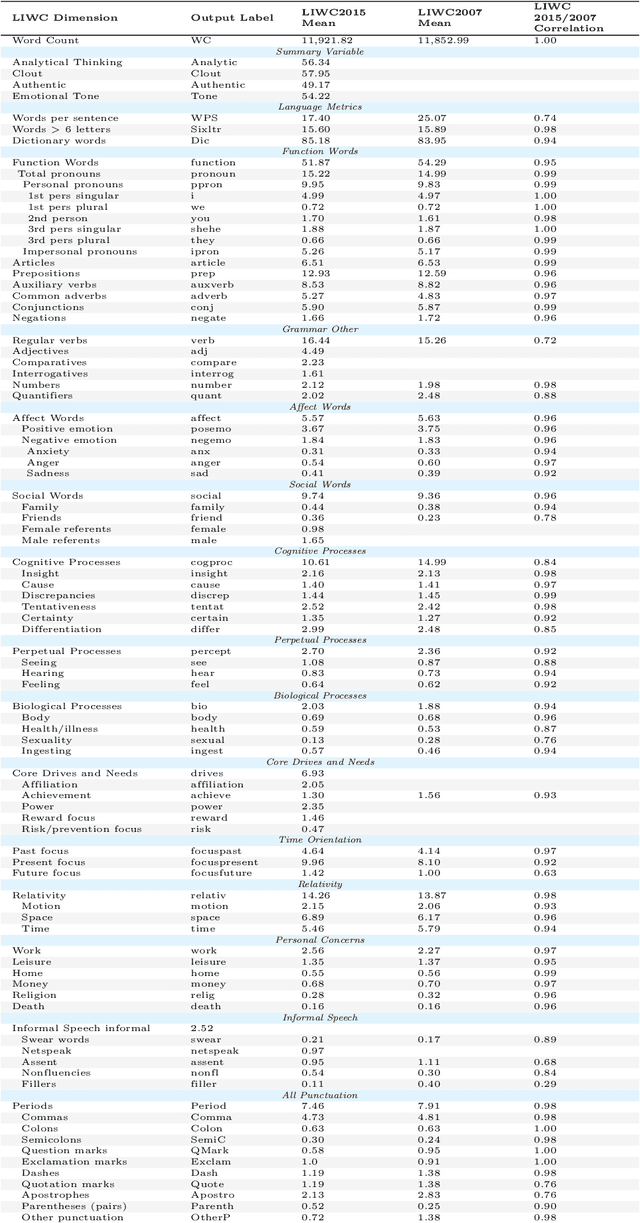
Personality detection is an old topic in psychology and Automatic Personality Prediction (or Perception) (APP) is the automated (computationally) forecasting of the personality on different types of human generated/exchanged contents (such as text, speech, image, video). The principal objective of this study is to offer a shallow (overall) review of natural language processing approaches on APP since 2010. With the advent of deep learning and following it transfer-learning and pre-trained model in NLP, APP research area has been a hot topic, so in this review, methods are categorized into three; pre-trained independent, pre-trained model based, multimodal approaches. Also, to achieve a comprehensive comparison, reported results are informed by datasets.
Phraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
Jun 09, 2021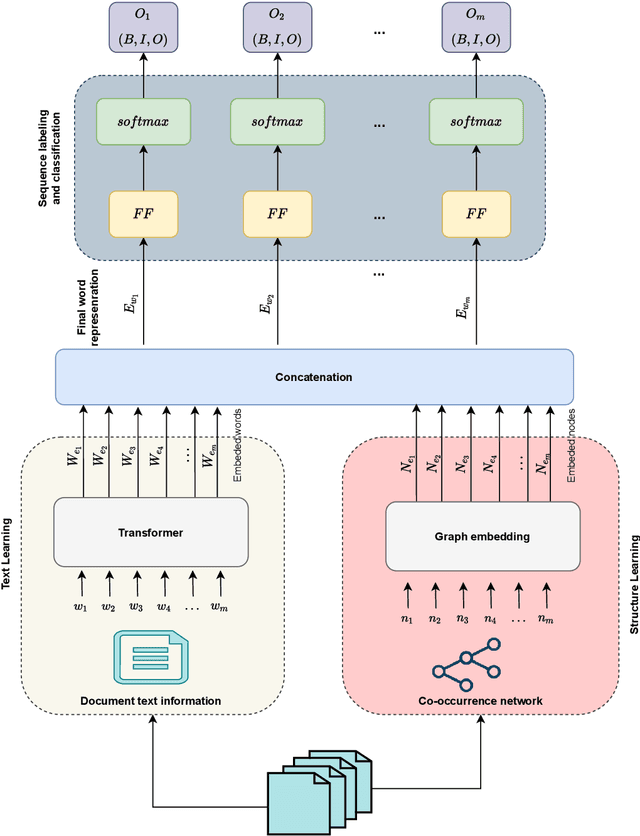
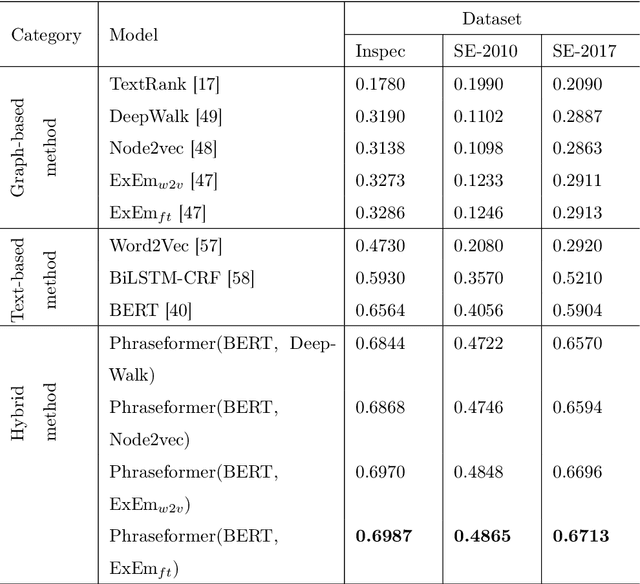
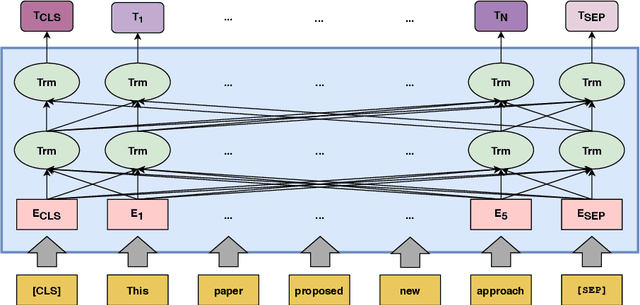
Background: Keyword extraction is a popular research topic in the field of natural language processing. Keywords are terms that describe the most relevant information in a document. The main problem that researchers are facing is how to efficiently and accurately extract the core keywords from a document. However, previous keyword extraction approaches have utilized the text and graph features, there is the lack of models that can properly learn and combine these features in a best way. Methods: In this paper, we develop a multimodal Key-phrase extraction approach, namely Phraseformer, using transformer and graph embedding techniques. In Phraseformer, each keyword candidate is presented by a vector which is the concatenation of the text and structure learning representations. Phraseformer takes the advantages of recent researches such as BERT and ExEm to preserve both representations. Also, the Phraseformer treats the key-phrase extraction task as a sequence labeling problem solved using classification task. Results: We analyze the performance of Phraseformer on three datasets including Inspec, SemEval2010 and SemEval 2017 by F1-score. Also, we investigate the performance of different classifiers on Phraseformer method over Inspec dataset. Experimental results demonstrate the effectiveness of Phraseformer method over the three datasets used. Additionally, the Random Forest classifier gain the highest F1-score among all classifiers. Conclusions: Due to the fact that the combination of BERT and ExEm is more meaningful and can better represent the semantic of words. Hence, Phraseformer significantly outperforms single-modality methods.
BLM-17m: A Large-Scale Dataset for Black Lives Matter Topic Detection on Twitter
May 04, 2021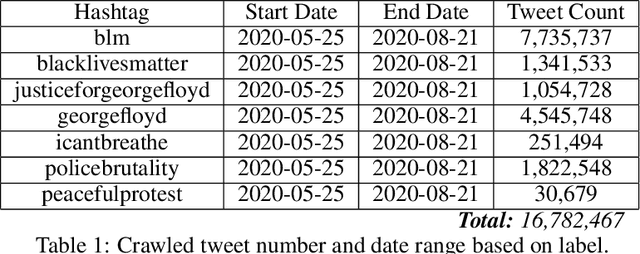
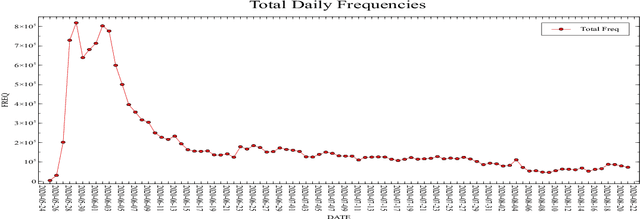
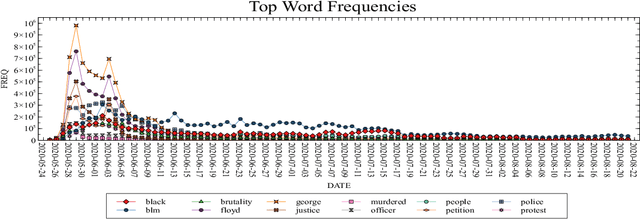
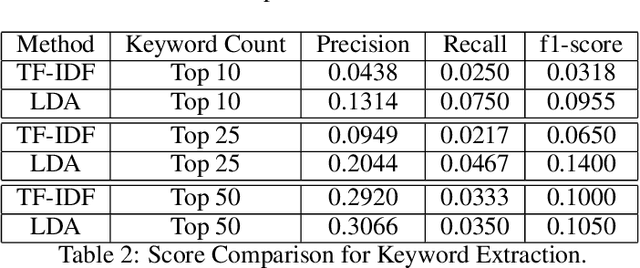
Protection of human rights is one of the most important problems of our world. In this paper, our aim is to provide a dataset which covers one of the most significant human rights contradiction in recent months affected the whole world, George Floyd incident. We propose a labeled dataset for topic detection that contains 17 million tweets. These Tweets are collected from 25 May 2020 to 21 August 2020 that covers 89 days from start of this incident. We labeled the dataset by monitoring most trending news topics from global and local newspapers. Apart from that, we present two baselines, TF-IDF and LDA. We evaluated the results of these two methods with three different k values for metrics of precision, recall and f1-score. The collected dataset is available at https://github.com/MeysamAsgariC/BLMT.
ComStreamClust: A communicative text clustering approach to topic detection in streaming data
Oct 11, 2020
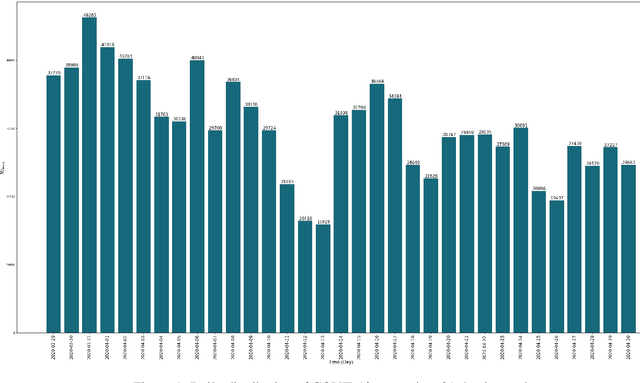

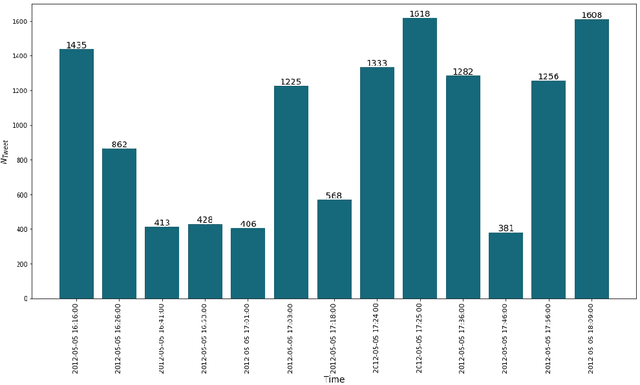
Topic detection is the task of determining and tracking hot topics in social media. Twitter is arguably the most popular platform for people to share their ideas with others about different issues. One such prevalent issue is the COVID-19 pandemic. Detecting and tracking topics on these kinds of issues would help governments and healthcare companies deal with this phenomenon. In this paper, we propose a novel communicative clustering approach, so-called ComStreamClust for clustering sub-topics inside a broader topic, e.g. COVID-19. The proposed approach was evaluated on two datasets: the COVID-19 and the FA CUP. The results obtained from ComStreamClust approve the effectiveness of the proposed approach when compared to existing methods such as LDA.
Covid-Transformer: Detecting COVID-19 Trending Topics on Twitter Using Universal Sentence Encoder
Sep 19, 2020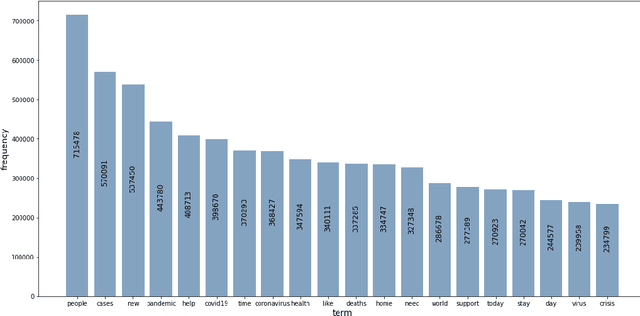
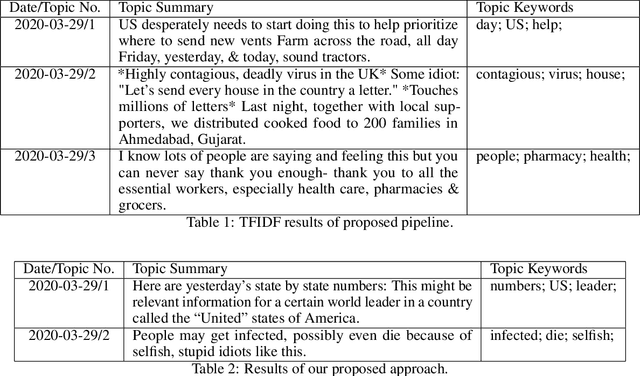

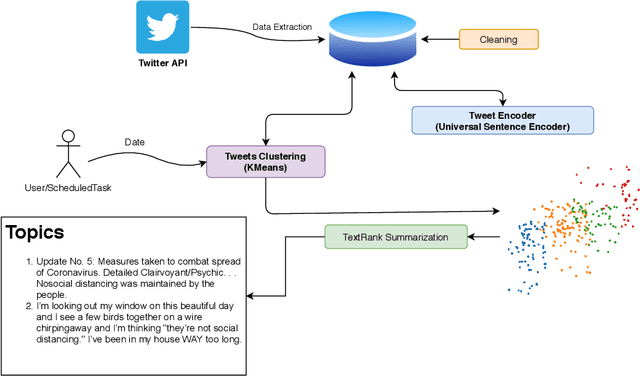
The novel corona-virus disease (also known as COVID-19) has led to a pandemic, impacting more than 200 countries across the globe. With its global impact, COVID-19 has become a major concern of people almost everywhere, and therefore there are a large number of tweets coming out from every corner of the world, about COVID-19 related topics. In this work, we try to analyze the tweets and detect the trending topics and major concerns of people on Twitter, which can enable us to better understand the situation, and devise better planning. More specifically we propose a model based on the universal sentence encoder to detect the main topics of Tweets in recent months. We used universal sentence encoder in order to derive the semantic representation and the similarity of tweets. We then used the sentence similarity and their embeddings, and feed them to K-means clustering algorithm to group similar tweets (in semantic sense). After that, the cluster summary is obtained using a text summarization algorithm based on deep learning, which can uncover the underlying topics of each cluster. Through experimental results, we show that our model can detect very informative topics, by processing a large number of tweets on sentence level (which can preserve the overall meaning of the tweets). Since this framework has no restriction on specific data distribution, it can be used to detect trending topics from any other social media and any other context rather than COVID-19. Experimental results show superiority of our proposed approach to other baselines, including TF-IDF, and latent Dirichlet allocation (LDA).
TopicBERT: A Transformer transfer learning based memory-graph approach for multimodal streaming social media topic detection
Aug 16, 2020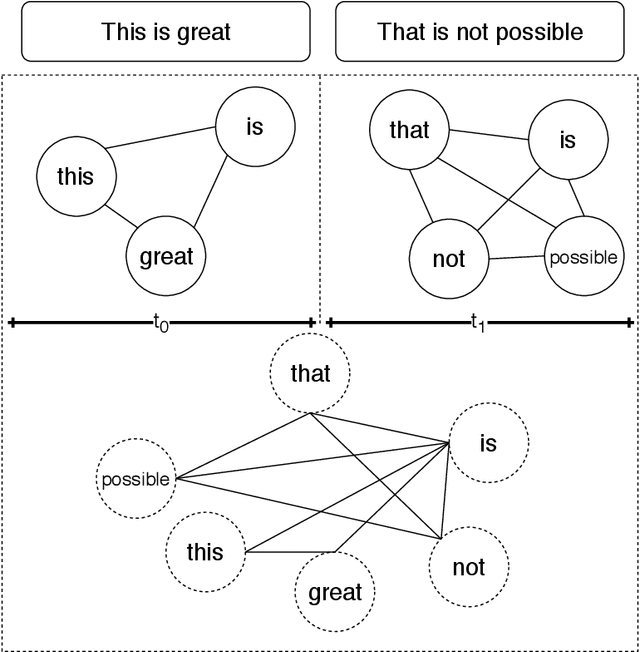

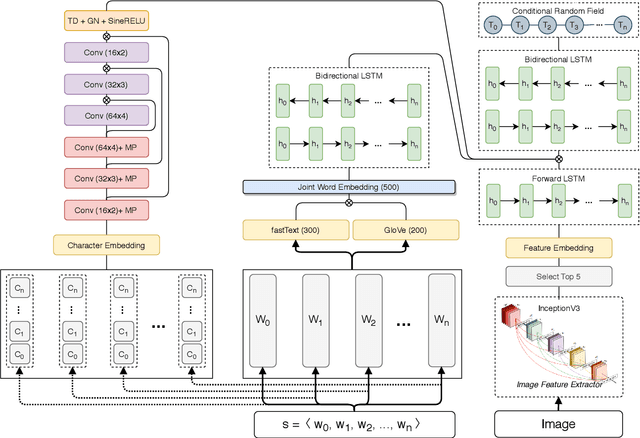

Real time nature of social networks with bursty short messages and their respective large data scale spread among vast variety of topics are research interest of many researchers. These properties of social networks which are known as 5'Vs of big data has led to many unique and enlightenment algorithms and techniques applied to large social networking datasets and data streams. Many of these researches are based on detection and tracking of hot topics and trending social media events that help revealing many unanswered questions. These algorithms and in some cases software products mostly rely on the nature of the language itself. Although, other techniques such as unsupervised data mining methods are language independent but many requirements for a comprehensive solution are not met. Many research issues such as noisy sentences that adverse grammar and new online user invented words are challenging maintenance of a good social network topic detection and tracking methodology; The semantic relationship between words and in most cases, synonyms are also ignored by many of these researches. In this research, we use Transformers combined with an incremental community detection algorithm. Transformer in one hand, provides the semantic relation between words in different contexts. On the other hand, the proposed graph mining technique enhances the resulting topics with aid of simple structural rules. Named entity recognition from multimodal data, image and text, labels the named entities with entity type and the extracted topics are tuned using them. All operations of proposed system has been applied with big social data perspective under NoSQL technologies. In order to present a working and systematic solution, we combined MongoDB with Neo4j as two major database systems of our work. The proposed system shows higher precision and recall compared to other methods in three different datasets.
Multimodal price prediction
Jul 09, 2020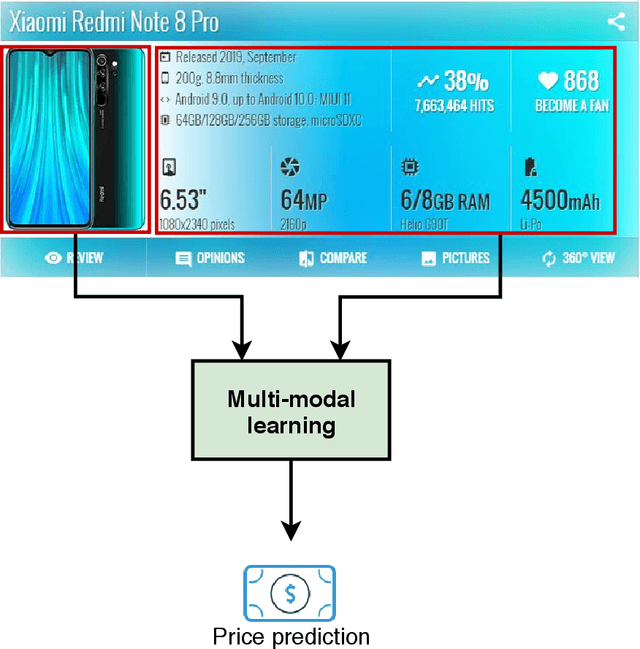

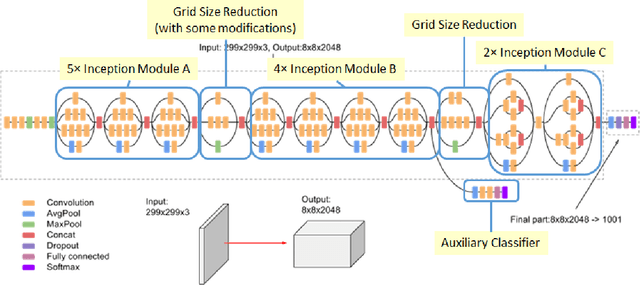
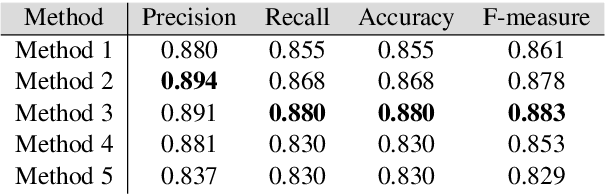
Valorization is one of the most heated discussions in the business community, and commodities valorization is one subset in this task. Features of a product is an essential characteristic in valorization and features are categorized into two classes: graphical and non-graphical. Nowadays, the value of products is measured by price. The goal of this research is to achieve an arrangement to predict the price of a product based on specifications of that. We propose five deep learning models to predict the price range of a product, one unimodal and four multimodal systems. The multimodal methods predict based on the image and non-graphical specification of product. As a platform to evaluate the methods, a cellphones dataset has been gathered from GSMArena. In proposed methods, convolutional neural network is an infrastructure. The experimental results show 88.3% F1-score in the best method.
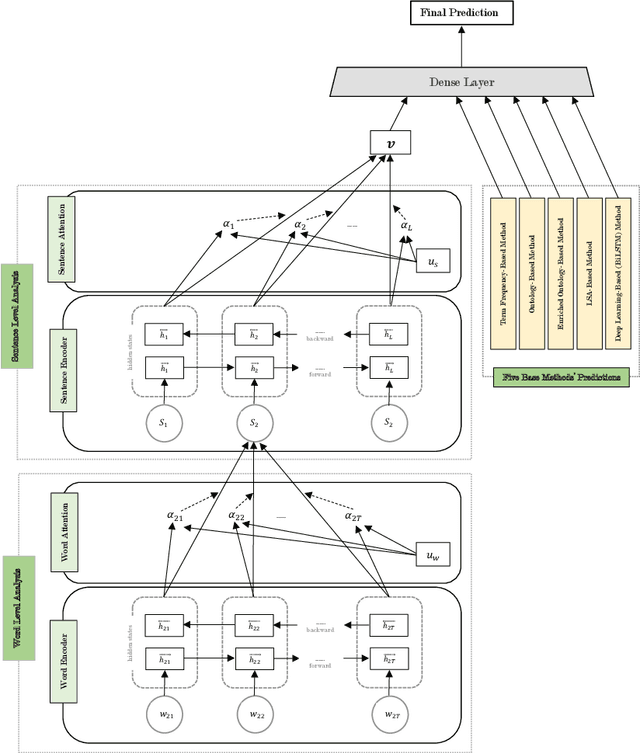
Automatic Personality Prediction; an Enhanced Method Using Ensemble Modeling
Jul 09, 2020
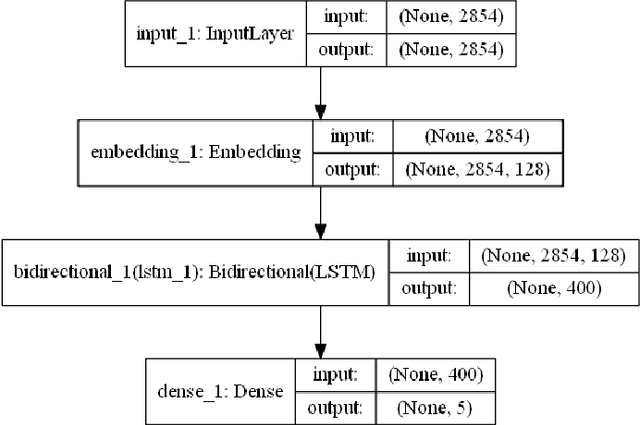
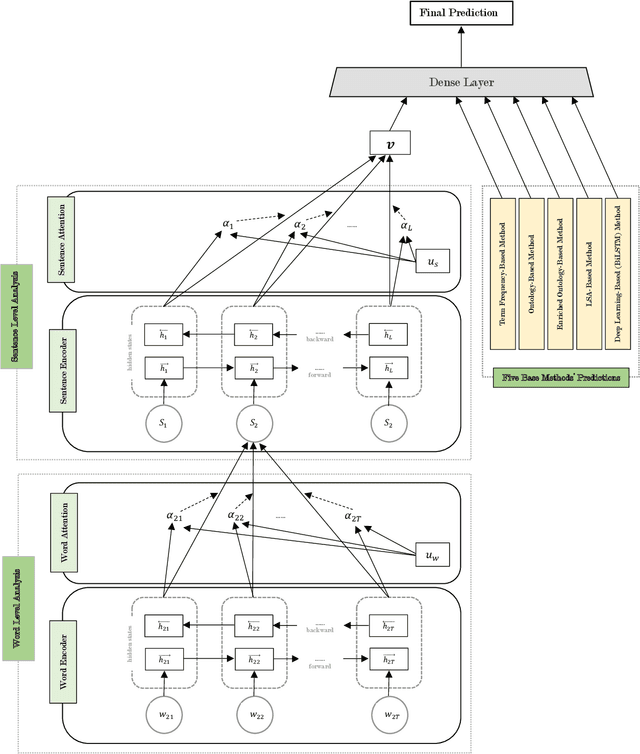
Human personality is significantly represented by those words which he/she uses in his/her speech or writing. As a consequence of spreading the information infrastructures (specifically the Internet and social media), human communications have reformed notably from face to face communication. Generally, Automatic Personality Prediction (or Perception) (APP) is the automated forecasting of the personality on different types of human generated/exchanged contents (like text, speech, image, video, etc.). The major objective of this study is to enhance the accuracy of APP from the text. To this end, we suggest five new APP methods including term frequency vector-based, ontology-based, enriched ontology-based, latent semantic analysis (LSA)-based, and deep learning-based (BiLSTM) methods. These methods as the base ones, contribute to each other to enhance the APP accuracy through ensemble modeling (stacking) based on a hierarchical attention network (HAN) as the meta-model. The results show that ensemble modeling enhances the accuracy of APP.