 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Powered Hybrid Intrusion Detection Framework for Cloud Security Using Novel Metaheuristic Optimization
Jan 03, 2026Cybersecurity poses considerable problems to Cloud Computing (CC), especially regarding Intrusion Detection Systems (IDSs), facing difficulties with skewed datasets and suboptimal classification model performance. This study presents the Hybrid Intrusion Detection System (HyIDS), an innovative IDS that employs the Energy Valley Optimizer (EVO) for Feature Selection (FS). Additionally, it introduces a novel technique for enhancing the cybersecurity of cloud computing through the integration of machine learning methodologies with the EVO Algorithm. The Energy Valley Optimizer (EVO) effectively diminished features in the CIC-DDoS2019 dataset from 88 to 38 and in the CSE-CIC-IDS2018 data from 80 to 43, significantly enhancing computing efficiency. HyIDS incorporates four Machine Learning (ML) models: Support Vector Machine (SVM), Random Forest (RF), Decision Tree (D_Tree), and K-Nearest Neighbors (KNN). The proposed HyIDS was assessed utilizing two real-world intrusion datasets, CIC-DDoS2019 and CSE-CIC-IDS2018, both distinguished by considerable class imbalances. The CIC-DDoS2019 dataset has a significant imbalance between DDoS assault samples and legal traffic, while the CSE-CIC-IDS2018 dataset primarily comprises benign traffic with insufficient representation of attack types, complicating the detection of minority attacks. A downsampling technique was employed to balance the datasets, hence improving detection efficacy for both benign and malicious traffic. Twenty-four trials were done, revealing substantial enhancements in categorization accuracy, precision, and recall. Our suggested D_TreeEVO model attained an accuracy rate of 99.13% and an F1 score of 98.94% on the CIC-DDoS2019 dataset, and an accuracy rate of 99.78% and an F1 score of 99.70% on the CSE-CIC-IDS2018 data. These data demonstrate that EVO significantly improves cybersecurity in Cloud Computing (CC).
Persian topic detection based on Human Word association and graph embedding
Feb 20, 2023In this paper, we propose a framework to detect topics in social media based on Human Word Association. Identifying topics discussed in these media has become a critical and significant challenge. Most of the work done in this area is in English, but much has been done in the Persian language, especially microblogs written in Persian. Also, the existing works focused more on exploring frequent patterns or semantic relationships and ignored the structural methods of language. In this paper, a topic detection framework using HWA, a method for Human Word Association, is proposed. This method uses the concept of imitation of mental ability for word association. This method also calculates the Associative Gravity Force that shows how words are related. Using this parameter, a graph can be generated. The topics can be extracted by embedding this graph and using clustering methods. This approach has been applied to a Persian language dataset collected from Telegram. Several experimental studies have been performed to evaluate the proposed framework's performance. Experimental results show that this approach works better than other topic detection methods.
A Human Word Association based model for topic detection in social networks
Jan 30, 2023With the widespread use of social networks, detecting the topics discussed in these networks has become a significant challenge. The current works are mainly based on frequent pattern mining or semantic relations, and the language structure is not considered. The meaning of language structural methods is to discover the relationship between words and how humans understand them. Therefore, this paper uses the Concept of the Imitation of the Mental Ability of Word Association to propose a topic detection framework in social networks. This framework is based on the Human Word Association method. The performance of this method is evaluated on the FA-CUP dataset. It is a benchmark dataset in the field of topic detection. The results show that the proposed method is a good improvement compared to other methods, based on the Topic-recall and the keyword F1 measure. Also, most of the previous works in the field of topic detection are limited to the English language, and the Persian language, especially microblogs written in this language, is considered a low-resource language. Therefore, a data set of Telegram posts in the Farsi language has been collected. Applying the proposed method to this dataset also shows that this method works better than other topic detection methods.
Unsupervised Broadcast News Summarization; a comparative study on Maximal Marginal Relevance (MMR) and Latent Semantic Analysis (LSA)
Jan 05, 2023
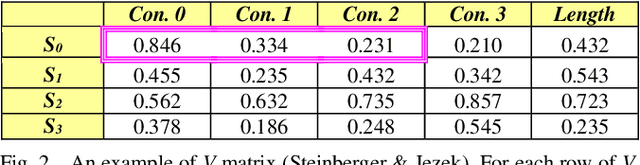
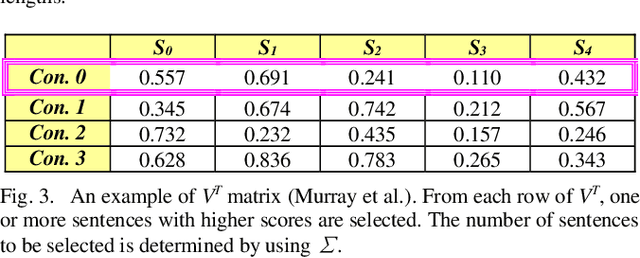
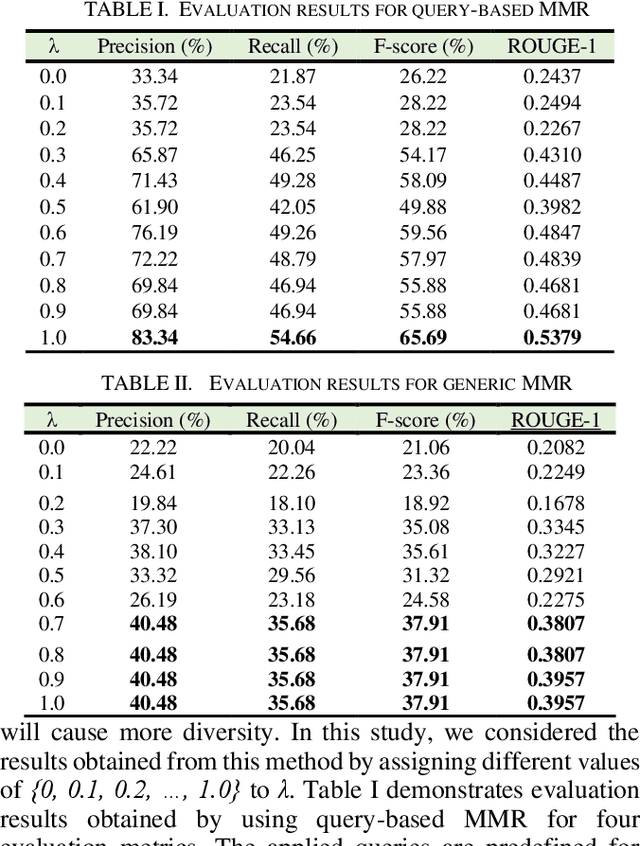
The methods of automatic speech summarization are classified into two groups: supervised and unsupervised methods. Supervised methods are based on a set of features, while unsupervised methods perform summarization based on a set of rules. Latent Semantic Analysis (LSA) and Maximal Marginal Relevance (MMR) are considered the most important and well-known unsupervised methods in automatic speech summarization. This study set out to investigate the performance of two aforementioned unsupervised methods in transcriptions of Persian broadcast news summarization. The results show that in generic summarization, LSA outperforms MMR, and in query-based summarization, MMR outperforms LSA in broadcast news summarization.
A Comprehensive Review of Visual-Textual Sentiment Analysis from Social Media Networks
Jul 05, 2022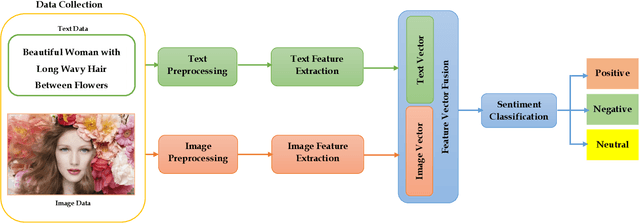
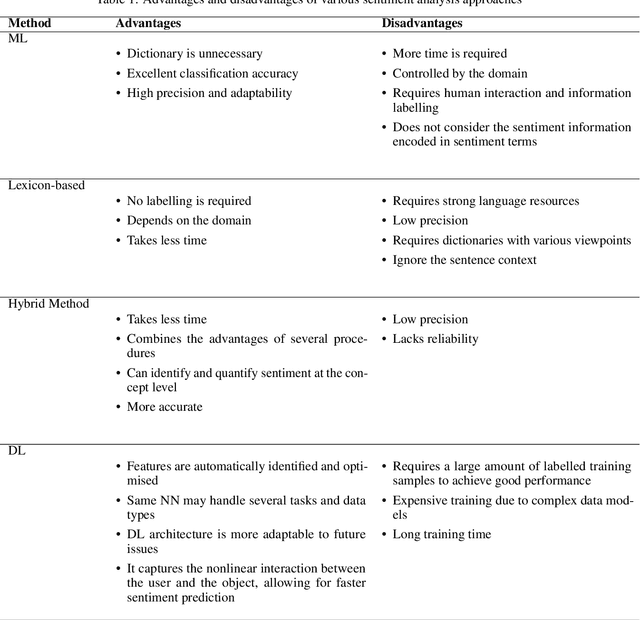
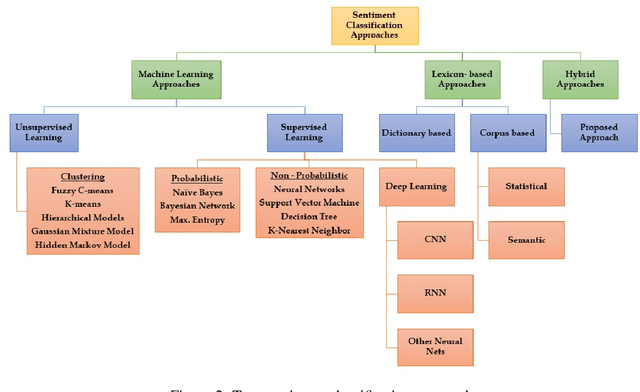
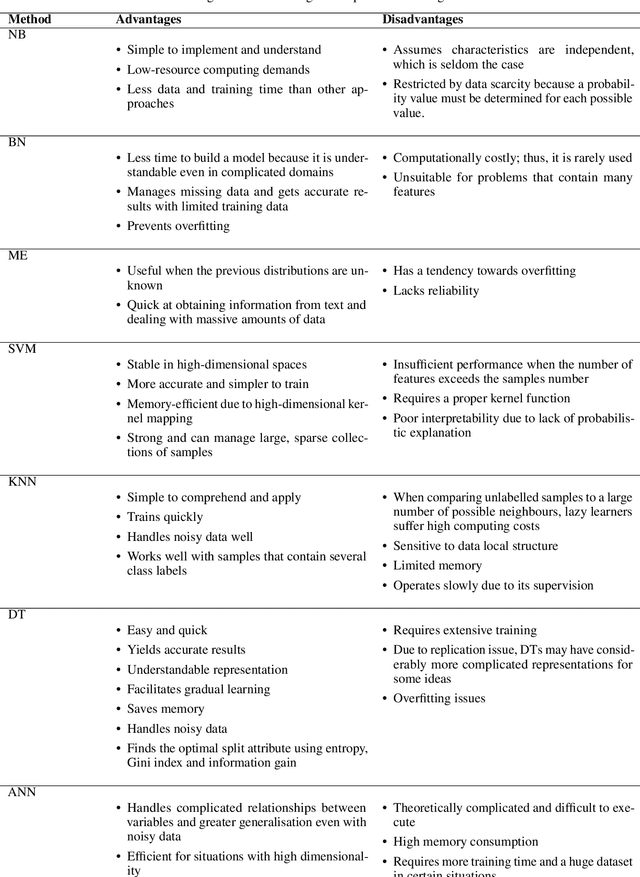
Social media networks have become a significant aspect of people's lives, serving as a platform for their ideas, opinions and emotions. Consequently, automated sentiment analysis (SA) is critical for recognising people's feelings in ways that other information sources cannot. The analysis of these feelings revealed various applications, including brand evaluations, YouTube film reviews and healthcare applications. As social media continues to develop, people post a massive amount of information in different forms, including text, photos, audio and video. Thus, traditional SA algorithms have become limited, as they do not consider the expressiveness of other modalities. By including such characteristics from various material sources, these multimodal data streams provide new opportunities for optimising the expected results beyond text-based SA. Our study focuses on the forefront field of multimodal SA, which examines visual and textual data posted on social media networks. Many people are more likely to utilise this information to express themselves on these platforms. To serve as a resource for academics in this rapidly growing field, we introduce a comprehensive overview of textual and visual SA, including data pre-processing, feature extraction techniques, sentiment benchmark datasets, and the efficacy of multiple classification methodologies suited to each field. We also provide a brief introduction of the most frequently utilised data fusion strategies and a summary of existing research on visual-textual SA. Finally, we highlight the most significant challenges and investigate several important sentiment applications.
Text-Based Automatic Personality Prediction Using KGrAt-Net; A Knowledge Graph Attention Network Classifier
May 27, 2022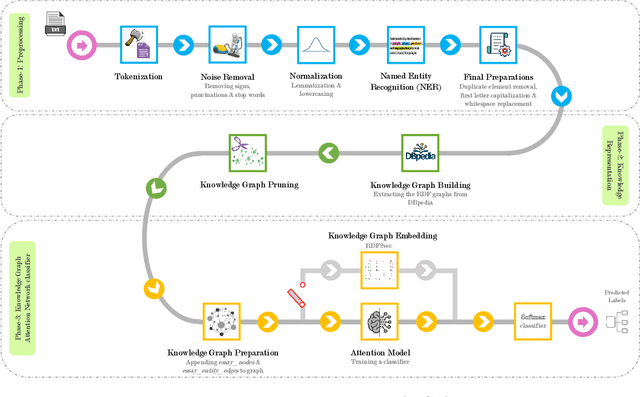

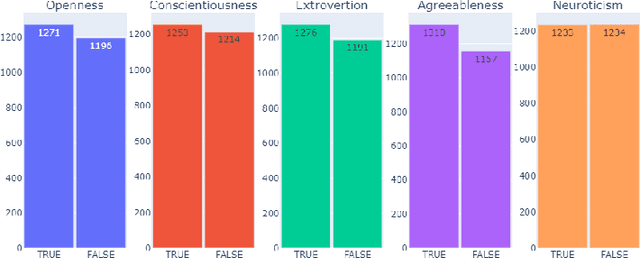
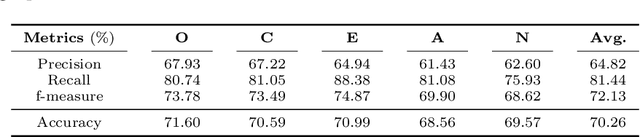
Nowadays, a tremendous amount of human communications take place on the Internet-based communication infrastructures, like social networks, email, forums, organizational communication platforms, etc. Indeed, the automatic prediction or assessment of individuals' personalities through their written or exchanged text would be advantageous to ameliorate the relationships among them. To this end, this paper aims to propose KGrAt-Net which is a Knowledge Graph Attention Network text classifier. For the first time, it applies the knowledge graph attention network to perform Automatic Personality Prediction (APP), according to the Big Five personality traits. After performing some preprocessing activities, first, it tries to acquire a knowingful representation of the knowledge behind the concepts in the input text through building its equivalent knowledge graph. A knowledge graph is a graph-based data model that formally represents the semantics of the existing concepts in the input text and models the knowledge behind them. Then, applying the attention mechanism, it efforts to pay attention to the most relevant parts of the graph to predict the personality traits of the input text. The results demonstrated that KGrAt-Net considerably improved the personality prediction accuracies. Furthermore, KGrAt-Net also uses the knowledge graphs' embeddings to enrich the classification, which makes it even more accurate in APP.
Knowledge Graph-Enabled Text-Based Automatic Personality Prediction
Mar 17, 2022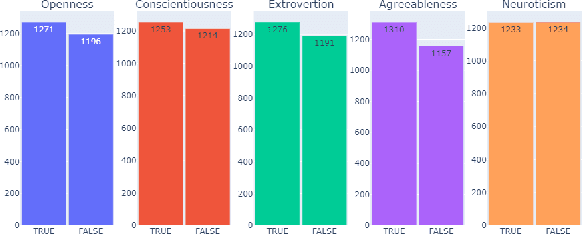

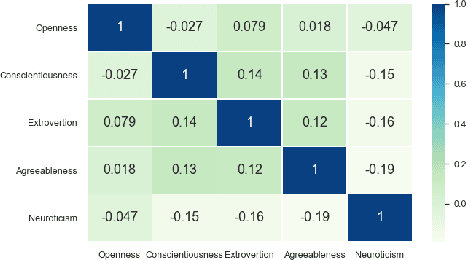

How people think, feel, and behave, primarily is a representation of their personality characteristics. By being conscious of personality characteristics of individuals whom we are dealing with or decided to deal with, one can competently ameliorate the relationship, regardless of its type. With the rise of Internet-based communication infrastructures (social networks, forums, etc.), a considerable amount of human communications take place there. The most prominent tool in such communications, is the language in written and spoken form that adroitly encodes all those essential personality characteristics of individuals. Text-based Automatic Personality Prediction (APP) is the automated forecasting of the personality of individuals based on the generated/exchanged text contents. This paper presents a novel knowledge graph-enabled approach to text-based APP that relies on the Big Five personality traits. To this end, given a text a knowledge graph which is a set of interlinked descriptions of concepts, was built through matching the input text's concepts with DBpedia knowledge base entries. Then, due to achieving more powerful representation the graph was enriched with the DBpedia ontology, NRC Emotion Intensity Lexicon, and MRC psycholinguistic database information. Afterwards, the knowledge graph which is now a knowledgeable alternative for the input text was embedded to yield an embedding matrix. Finally, to perform personality predictions the resulting embedding matrix was fed to four suggested deep learning models independently, which are based on convolutional neural network (CNN), simple recurrent neural network (RNN), long short term memory (LSTM) and bidirectional long short term memory (BiLSTM). The results indicated a considerable improvements in prediction accuracies in all of the suggested classifiers.
Resource recommender system performance improvement by exploring similar tags and detecting tags communities
Jan 10, 2022

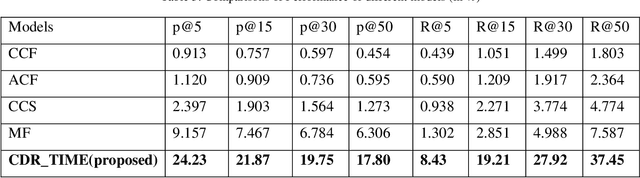
Many researchers have used tag information to improve the performance of recommendation techniques in recommender systems. Examining the tags of users will help to get their interests and leads to more accuracy in the recommendations. Since user-defined tags are chosen freely and without any restrictions, problems arise in determining their exact meaning and the similarity of tags. On the other hand, using thesauruses and ontologies to find the meaning of tags is not very efficient due to their free definition by users and the use of different languages in many data sets. Therefore, this article uses the mathematical and statistical methods to determine lexical similarity and co-occurrence tags solution to assign semantic similarity. On the other hand, due to the change of users' interests over time this article have considered the time of tag assignments in co-occurrence tags for determined similarity of tags. Then the graph is created based on these similarities. For modeling the interests of the users, the communities of tags are determined by using community detection methods. So recommendations based on the communities of tags and similarity between resources are done. The performance of the proposed method has been done using two criteria of precision and recall based on evaluations with "Delicious" dataset. The evaluation results show that, the precision and recall of the proposed method have significantly improved, compared to the other methods.
The state-of-the-art in text-based automatic personality prediction
Oct 04, 2021
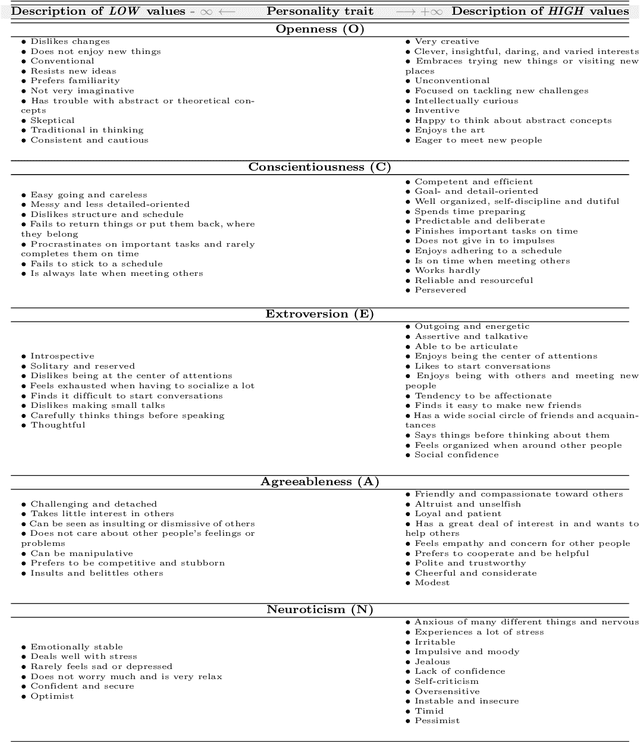
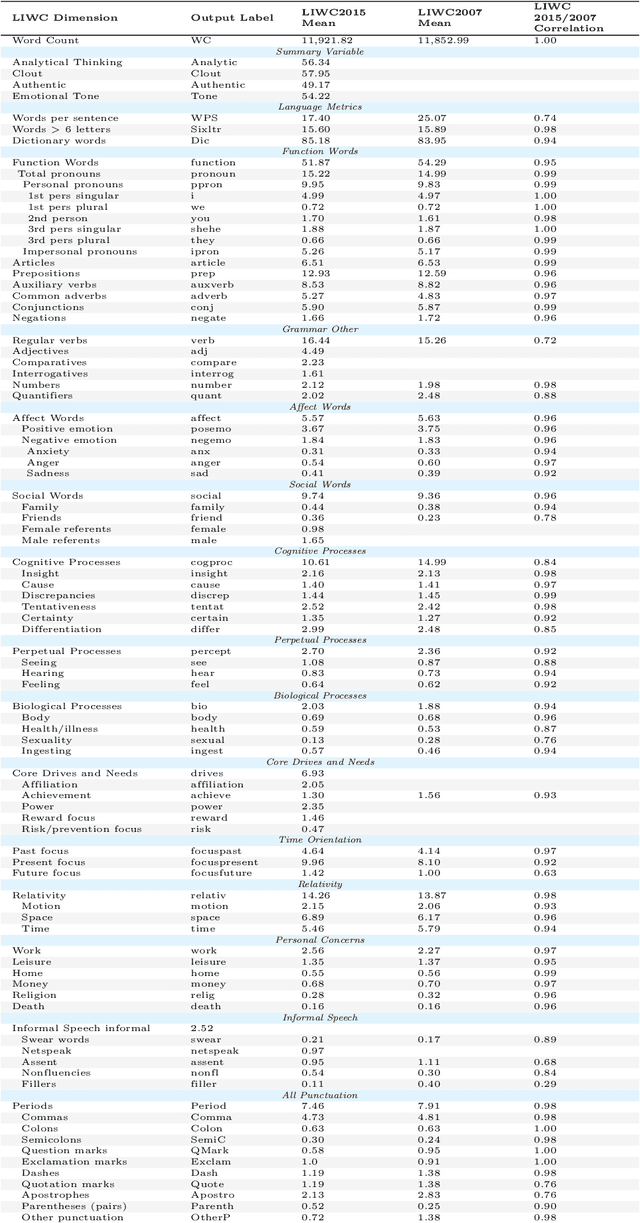
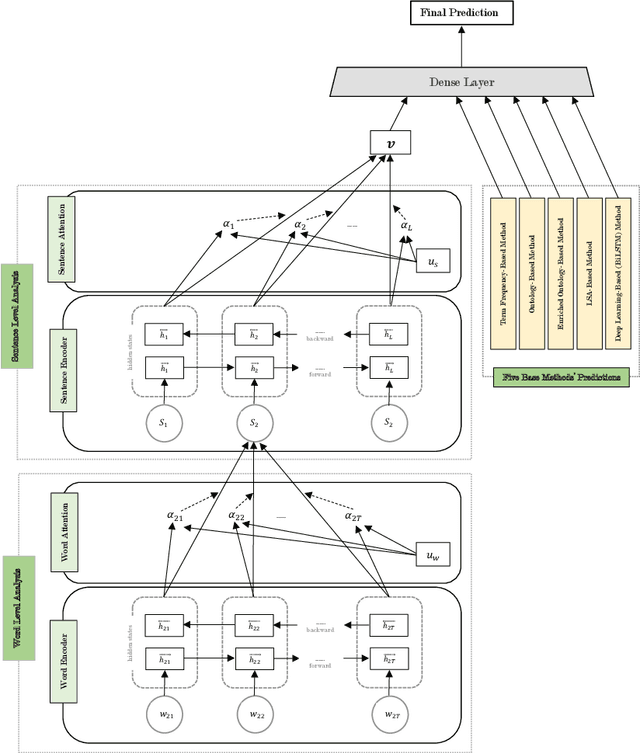
Personality detection is an old topic in psychology and Automatic Personality Prediction (or Perception) (APP) is the automated (computationally) forecasting of the personality on different types of human generated/exchanged contents (such as text, speech, image, video). The principal objective of this study is to offer a shallow (overall) review of natural language processing approaches on APP since 2010. With the advent of deep learning and following it transfer-learning and pre-trained model in NLP, APP research area has been a hot topic, so in this review, methods are categorized into three; pre-trained independent, pre-trained model based, multimodal approaches. Also, to achieve a comprehensive comparison, reported results are informed by datasets.
Phraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
Jun 09, 2021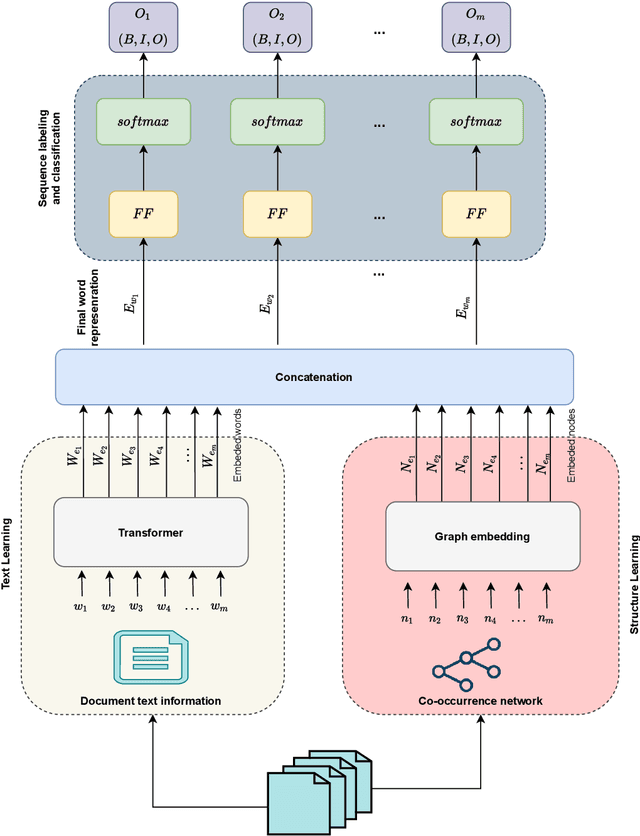
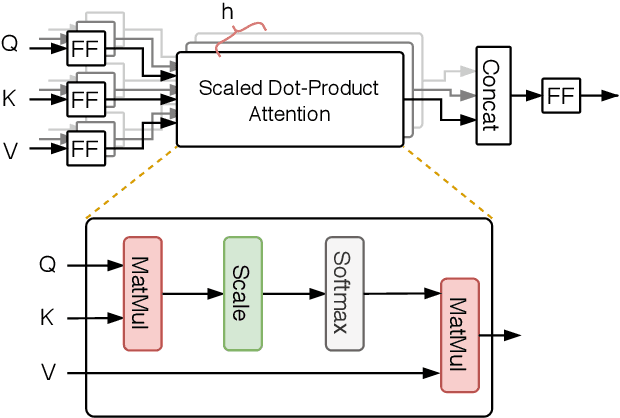
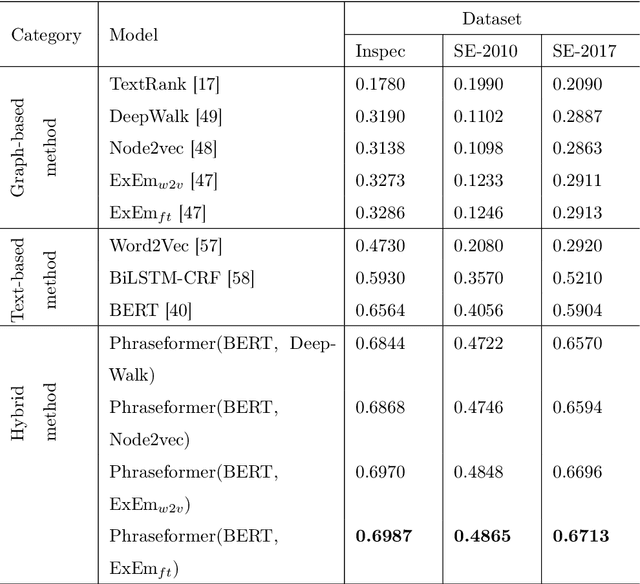
Background: Keyword extraction is a popular research topic in the field of natural language processing. Keywords are terms that describe the most relevant information in a document. The main problem that researchers are facing is how to efficiently and accurately extract the core keywords from a document. However, previous keyword extraction approaches have utilized the text and graph features, there is the lack of models that can properly learn and combine these features in a best way. Methods: In this paper, we develop a multimodal Key-phrase extraction approach, namely Phraseformer, using transformer and graph embedding techniques. In Phraseformer, each keyword candidate is presented by a vector which is the concatenation of the text and structure learning representations. Phraseformer takes the advantages of recent researches such as BERT and ExEm to preserve both representations. Also, the Phraseformer treats the key-phrase extraction task as a sequence labeling problem solved using classification task. Results: We analyze the performance of Phraseformer on three datasets including Inspec, SemEval2010 and SemEval 2017 by F1-score. Also, we investigate the performance of different classifiers on Phraseformer method over Inspec dataset. Experimental results demonstrate the effectiveness of Phraseformer method over the three datasets used. Additionally, the Random Forest classifier gain the highest F1-score among all classifiers. Conclusions: Due to the fact that the combination of BERT and ExEm is more meaningful and can better represent the semantic of words. Hence, Phraseformer significantly outperforms single-modality methods.