 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe state-of-the-art in text-based automatic personality prediction
Oct 04, 2021
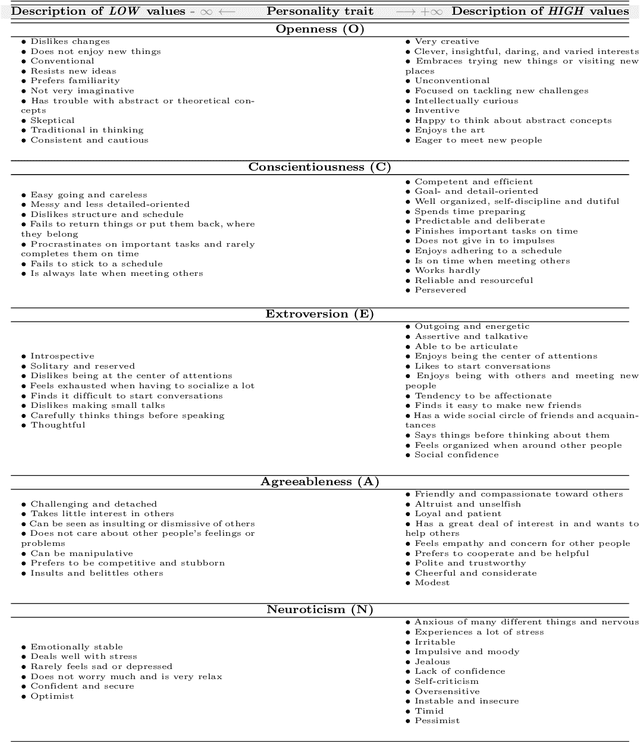
Personality detection is an old topic in psychology and Automatic Personality Prediction (or Perception) (APP) is the automated (computationally) forecasting of the personality on different types of human generated/exchanged contents (such as text, speech, image, video). The principal objective of this study is to offer a shallow (overall) review of natural language processing approaches on APP since 2010. With the advent of deep learning and following it transfer-learning and pre-trained model in NLP, APP research area has been a hot topic, so in this review, methods are categorized into three; pre-trained independent, pre-trained model based, multimodal approaches. Also, to achieve a comprehensive comparison, reported results are informed by datasets.
Phraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
Jun 09, 2021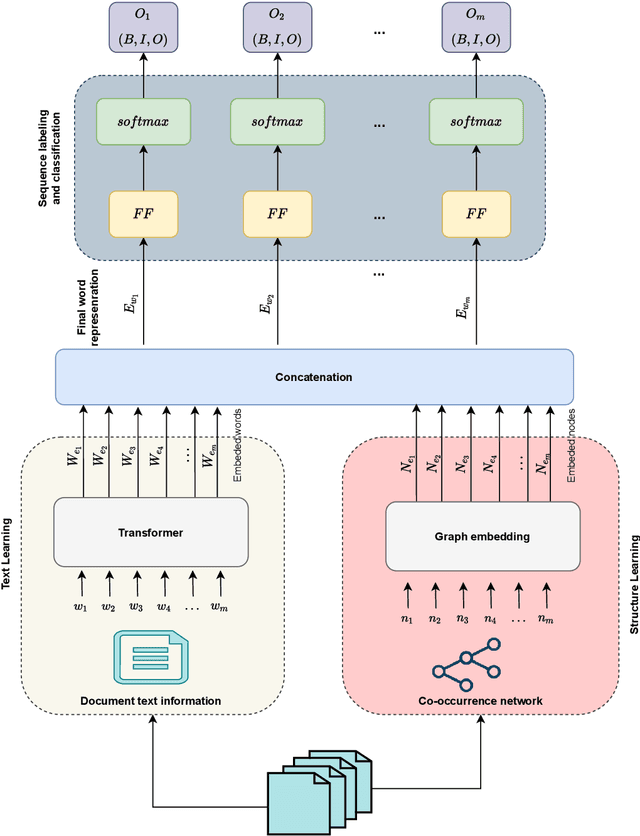
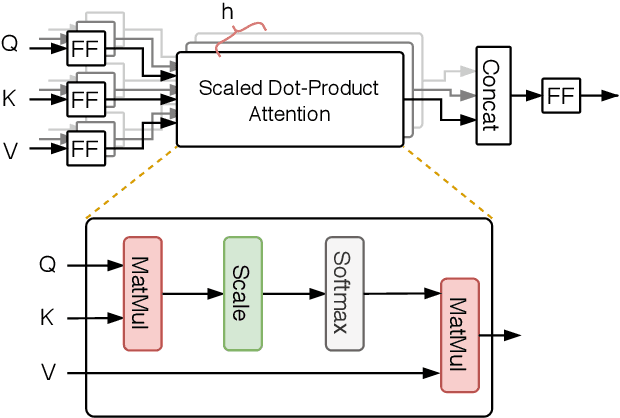
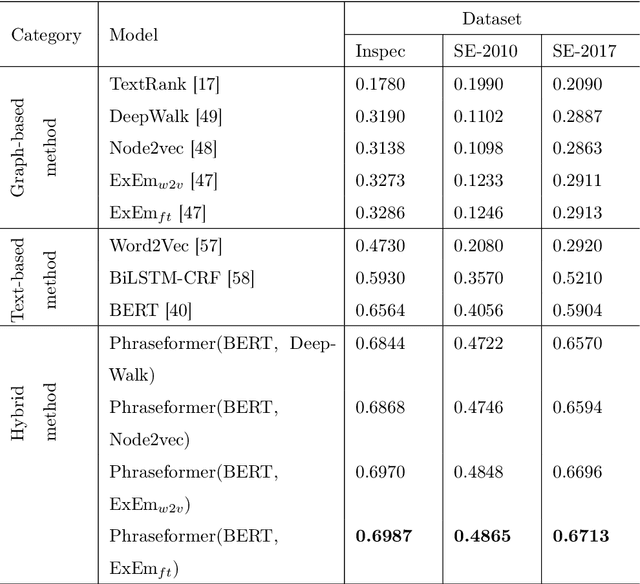
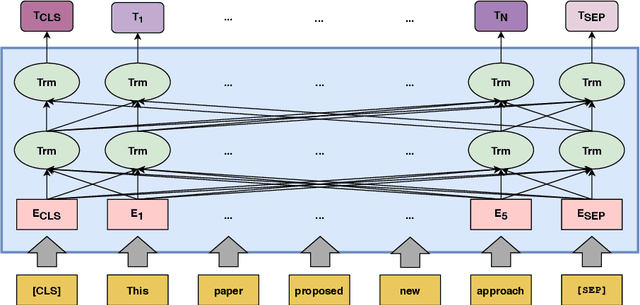
Background: Keyword extraction is a popular research topic in the field of natural language processing. Keywords are terms that describe the most relevant information in a document. The main problem that researchers are facing is how to efficiently and accurately extract the core keywords from a document. However, previous keyword extraction approaches have utilized the text and graph features, there is the lack of models that can properly learn and combine these features in a best way. Methods: In this paper, we develop a multimodal Key-phrase extraction approach, namely Phraseformer, using transformer and graph embedding techniques. In Phraseformer, each keyword candidate is presented by a vector which is the concatenation of the text and structure learning representations. Phraseformer takes the advantages of recent researches such as BERT and ExEm to preserve both representations. Also, the Phraseformer treats the key-phrase extraction task as a sequence labeling problem solved using classification task. Results: We analyze the performance of Phraseformer on three datasets including Inspec, SemEval2010 and SemEval 2017 by F1-score. Also, we investigate the performance of different classifiers on Phraseformer method over Inspec dataset. Experimental results demonstrate the effectiveness of Phraseformer method over the three datasets used. Additionally, the Random Forest classifier gain the highest F1-score among all classifiers. Conclusions: Due to the fact that the combination of BERT and ExEm is more meaningful and can better represent the semantic of words. Hence, Phraseformer significantly outperforms single-modality methods.
Multimodal price prediction
Jul 09, 2020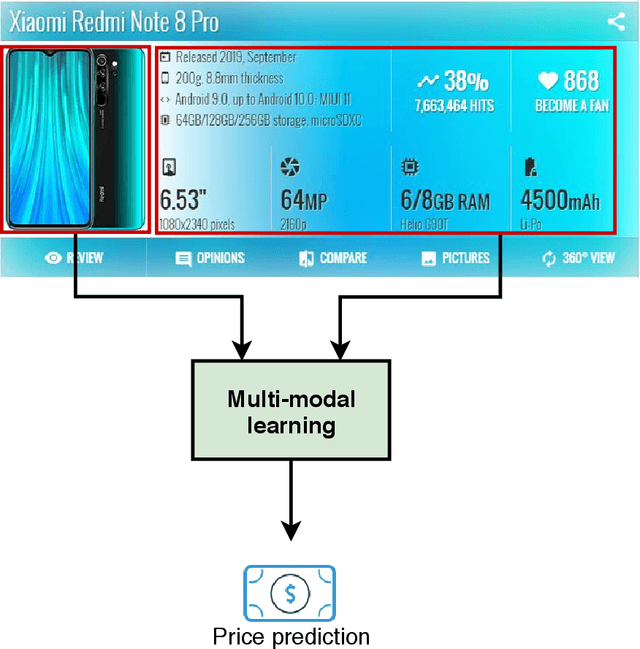

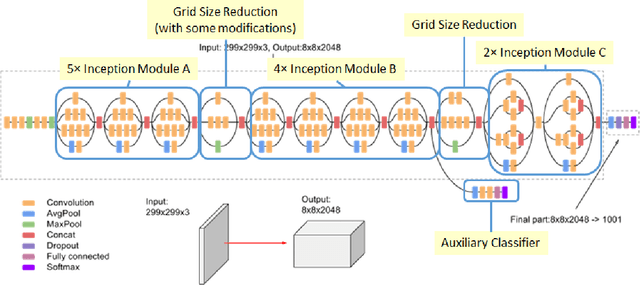
Valorization is one of the most heated discussions in the business community, and commodities valorization is one subset in this task. Features of a product is an essential characteristic in valorization and features are categorized into two classes: graphical and non-graphical. Nowadays, the value of products is measured by price. The goal of this research is to achieve an arrangement to predict the price of a product based on specifications of that. We propose five deep learning models to predict the price range of a product, one unimodal and four multimodal systems. The multimodal methods predict based on the image and non-graphical specification of product. As a platform to evaluate the methods, a cellphones dataset has been gathered from GSMArena. In proposed methods, convolutional neural network is an infrastructure. The experimental results show 88.3% F1-score in the best method.
Automatic Personality Prediction; an Enhanced Method Using Ensemble Modeling
Jul 09, 2020
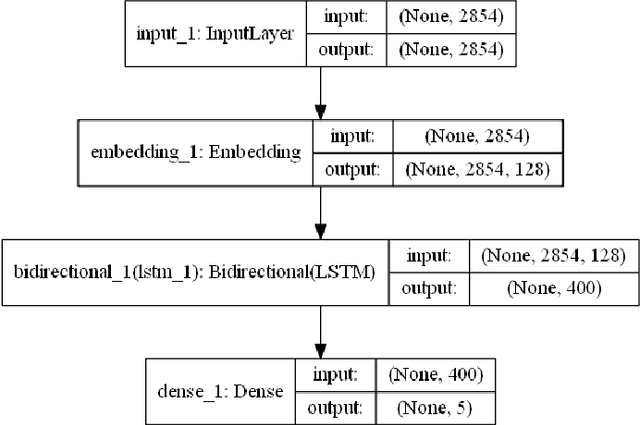
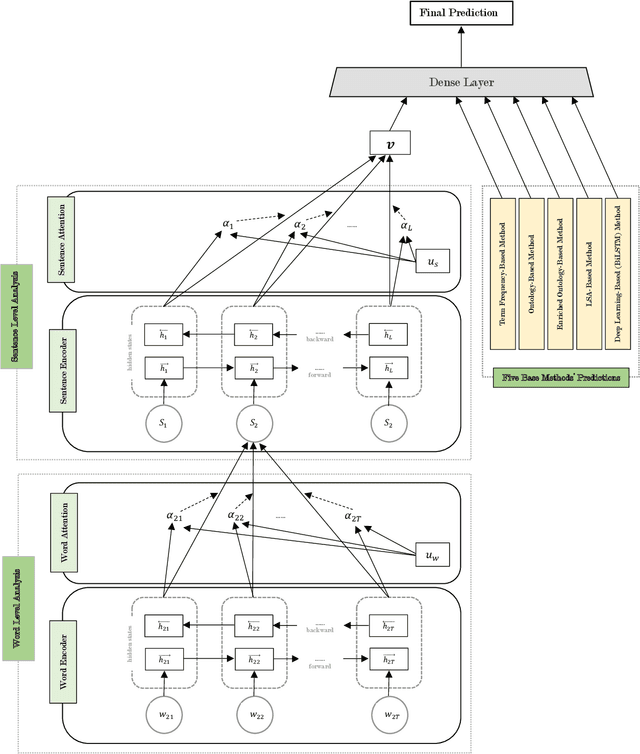
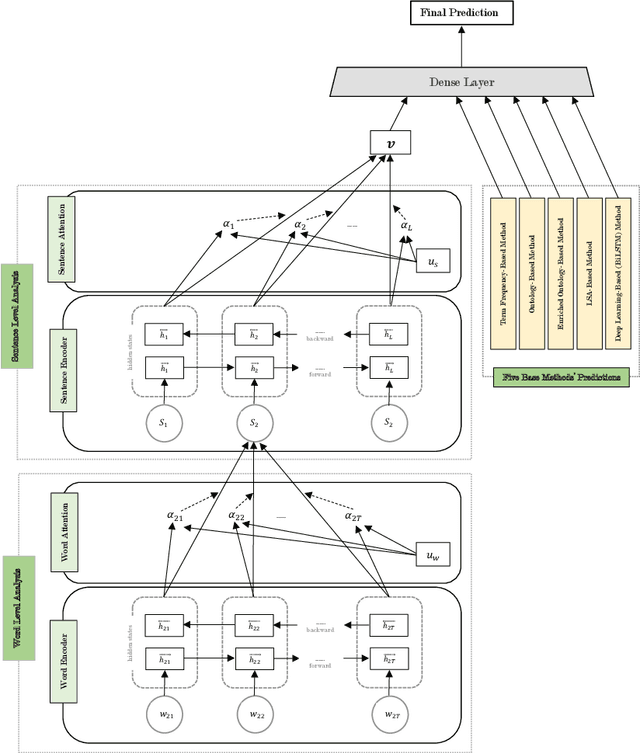
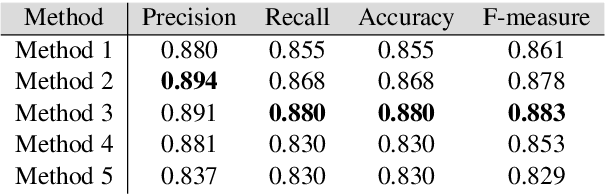
Human personality is significantly represented by those words which he/she uses in his/her speech or writing. As a consequence of spreading the information infrastructures (specifically the Internet and social media), human communications have reformed notably from face to face communication. Generally, Automatic Personality Prediction (or Perception) (APP) is the automated forecasting of the personality on different types of human generated/exchanged contents (like text, speech, image, video, etc.). The major objective of this study is to enhance the accuracy of APP from the text. To this end, we suggest five new APP methods including term frequency vector-based, ontology-based, enriched ontology-based, latent semantic analysis (LSA)-based, and deep learning-based (BiLSTM) methods. These methods as the base ones, contribute to each other to enhance the APP accuracy through ensemble modeling (stacking) based on a hierarchical attention network (HAN) as the meta-model. The results show that ensemble modeling enhances the accuracy of APP.
A Model to Measure the Spread Power of Rumors
Feb 27, 2020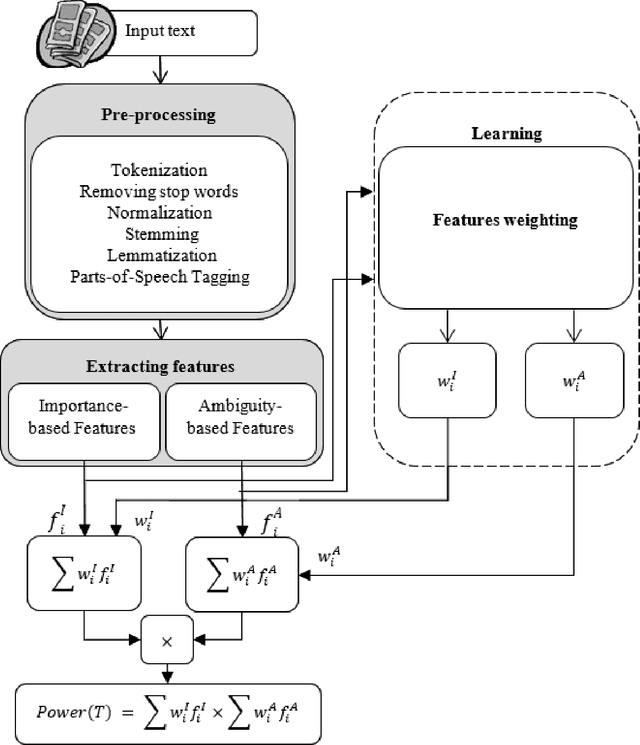
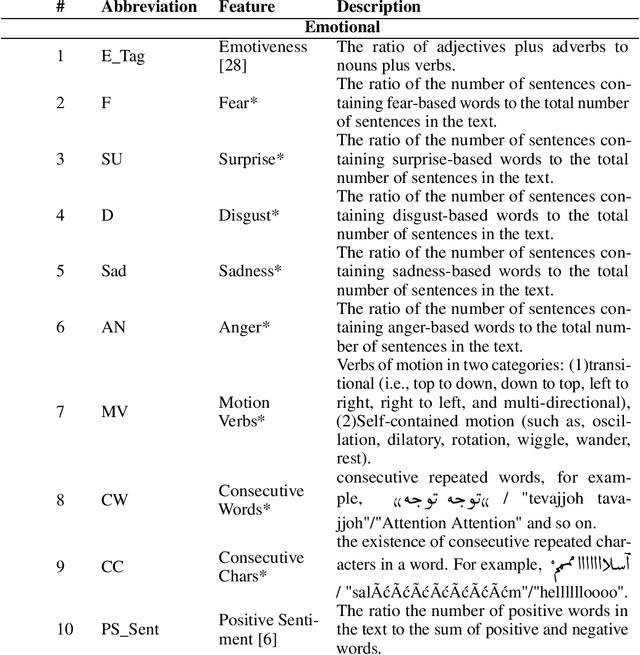
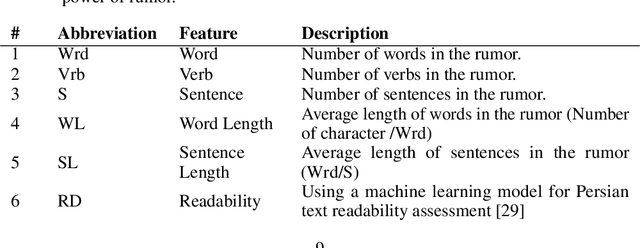

Nowadays, a significant portion of daily interacted posts in social media are infected by rumors. This study investigates the problem of rumor analysis in different areas from other researches. It tackles the unaddressed problem related to calculating the Spread Power of Rumor (SPR) for the first time and seeks to examine the spread power as the function of multi-contextual features. For this purpose, the theory of Allport and Postman will be adopted. In which it claims that there are two key factors determinant to the spread power of rumors, namely importance and ambiguity. The proposed Rumor Spread Power Measurement Model (RSPMM) computes SPR by utilizing a textual-based approach, which entails contextual features to compute the spread power of the rumors in two categories: False Rumor (FR) and True Rumor (TR). Totally 51 contextual features are introduced to measure SPR and their impact on classification are investigated, then 42 features in two categories "importance" (28 features) and "ambiguity" (14 features) are selected to compute SPR. The proposed RSPMM is verified on two labelled datasets, which are collected from Twitter and Telegram. The results show that (i) the proposed new features are effective and efficient to discriminate between FRs and TRs. (ii) the proposed RSPMM approach focused only on contextual features while existing techniques are based on Structure and Content features, but RSPMM achieves considerably outstanding results (F-measure=83%). (iii) The result of T-Test shows that SPR criteria can significantly distinguish between FR and TR, besides it can be useful as a new method to verify the trueness of rumors.