 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Based Automatic Personality Prediction Using KGrAt-Net; A Knowledge Graph Attention Network Classifier
May 27, 2022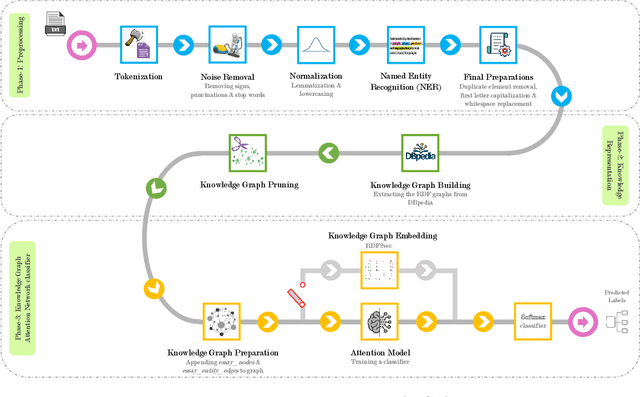

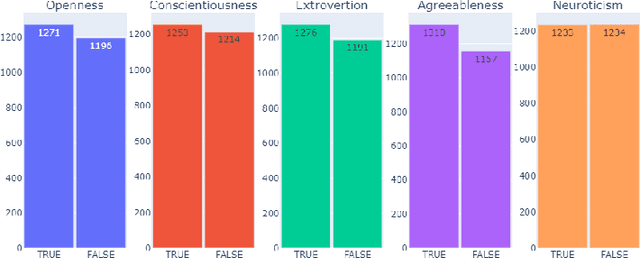
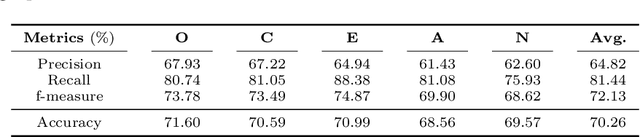
Nowadays, a tremendous amount of human communications take place on the Internet-based communication infrastructures, like social networks, email, forums, organizational communication platforms, etc. Indeed, the automatic prediction or assessment of individuals' personalities through their written or exchanged text would be advantageous to ameliorate the relationships among them. To this end, this paper aims to propose KGrAt-Net which is a Knowledge Graph Attention Network text classifier. For the first time, it applies the knowledge graph attention network to perform Automatic Personality Prediction (APP), according to the Big Five personality traits. After performing some preprocessing activities, first, it tries to acquire a knowingful representation of the knowledge behind the concepts in the input text through building its equivalent knowledge graph. A knowledge graph is a graph-based data model that formally represents the semantics of the existing concepts in the input text and models the knowledge behind them. Then, applying the attention mechanism, it efforts to pay attention to the most relevant parts of the graph to predict the personality traits of the input text. The results demonstrated that KGrAt-Net considerably improved the personality prediction accuracies. Furthermore, KGrAt-Net also uses the knowledge graphs' embeddings to enrich the classification, which makes it even more accurate in APP.
Knowledge Graph-Enabled Text-Based Automatic Personality Prediction
Mar 17, 2022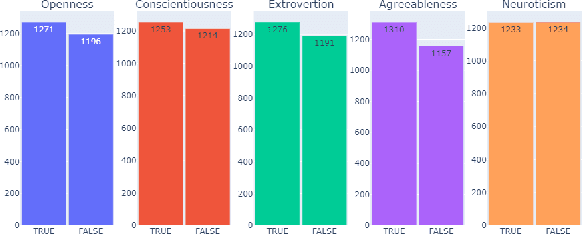

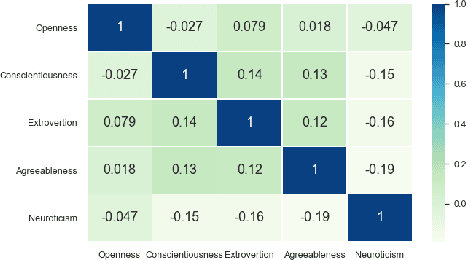

How people think, feel, and behave, primarily is a representation of their personality characteristics. By being conscious of personality characteristics of individuals whom we are dealing with or decided to deal with, one can competently ameliorate the relationship, regardless of its type. With the rise of Internet-based communication infrastructures (social networks, forums, etc.), a considerable amount of human communications take place there. The most prominent tool in such communications, is the language in written and spoken form that adroitly encodes all those essential personality characteristics of individuals. Text-based Automatic Personality Prediction (APP) is the automated forecasting of the personality of individuals based on the generated/exchanged text contents. This paper presents a novel knowledge graph-enabled approach to text-based APP that relies on the Big Five personality traits. To this end, given a text a knowledge graph which is a set of interlinked descriptions of concepts, was built through matching the input text's concepts with DBpedia knowledge base entries. Then, due to achieving more powerful representation the graph was enriched with the DBpedia ontology, NRC Emotion Intensity Lexicon, and MRC psycholinguistic database information. Afterwards, the knowledge graph which is now a knowledgeable alternative for the input text was embedded to yield an embedding matrix. Finally, to perform personality predictions the resulting embedding matrix was fed to four suggested deep learning models independently, which are based on convolutional neural network (CNN), simple recurrent neural network (RNN), long short term memory (LSTM) and bidirectional long short term memory (BiLSTM). The results indicated a considerable improvements in prediction accuracies in all of the suggested classifiers.
Resource recommender system performance improvement by exploring similar tags and detecting tags communities
Jan 10, 2022

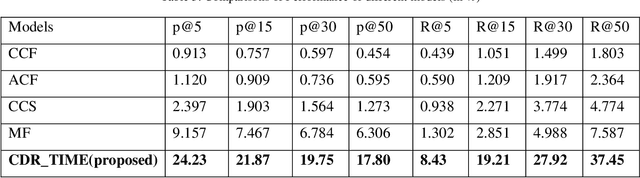
Many researchers have used tag information to improve the performance of recommendation techniques in recommender systems. Examining the tags of users will help to get their interests and leads to more accuracy in the recommendations. Since user-defined tags are chosen freely and without any restrictions, problems arise in determining their exact meaning and the similarity of tags. On the other hand, using thesauruses and ontologies to find the meaning of tags is not very efficient due to their free definition by users and the use of different languages in many data sets. Therefore, this article uses the mathematical and statistical methods to determine lexical similarity and co-occurrence tags solution to assign semantic similarity. On the other hand, due to the change of users' interests over time this article have considered the time of tag assignments in co-occurrence tags for determined similarity of tags. Then the graph is created based on these similarities. For modeling the interests of the users, the communities of tags are determined by using community detection methods. So recommendations based on the communities of tags and similarity between resources are done. The performance of the proposed method has been done using two criteria of precision and recall based on evaluations with "Delicious" dataset. The evaluation results show that, the precision and recall of the proposed method have significantly improved, compared to the other methods.
Phraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
Jun 09, 2021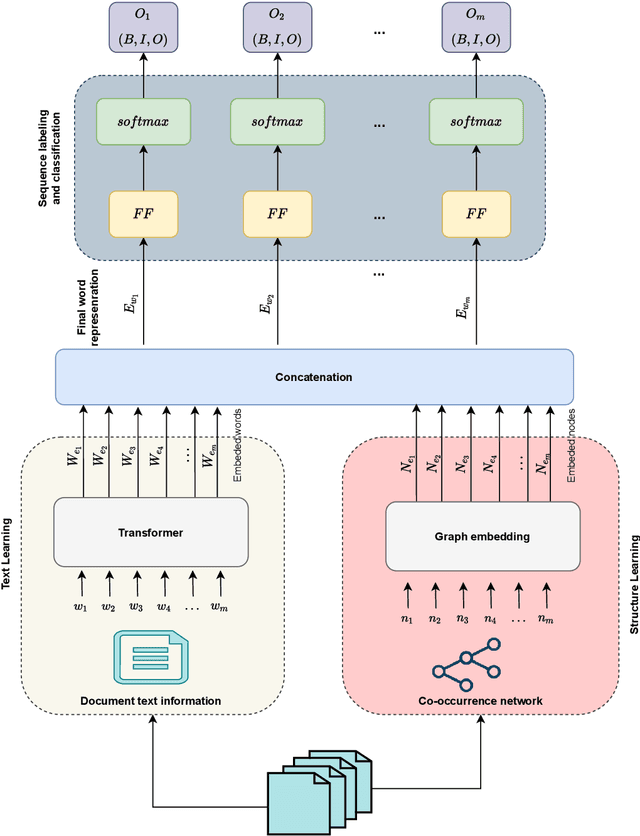
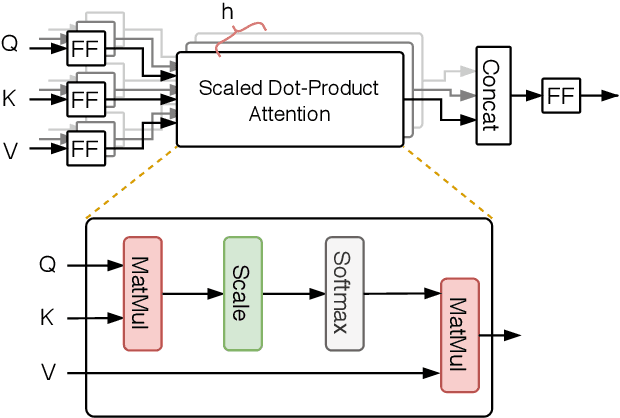
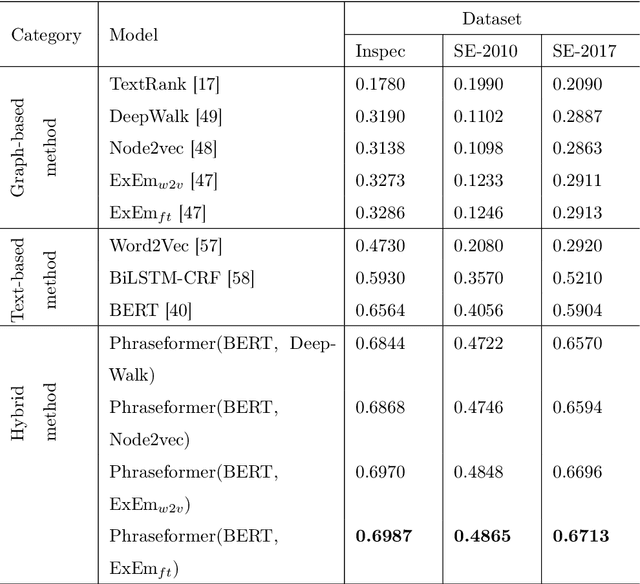
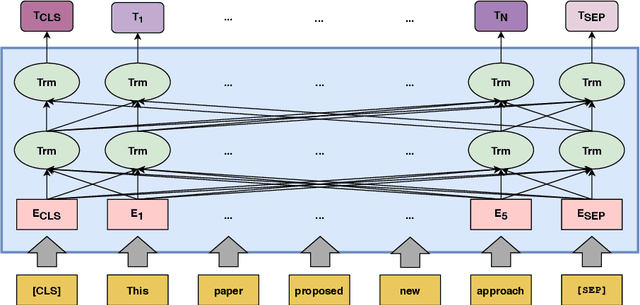
Background: Keyword extraction is a popular research topic in the field of natural language processing. Keywords are terms that describe the most relevant information in a document. The main problem that researchers are facing is how to efficiently and accurately extract the core keywords from a document. However, previous keyword extraction approaches have utilized the text and graph features, there is the lack of models that can properly learn and combine these features in a best way. Methods: In this paper, we develop a multimodal Key-phrase extraction approach, namely Phraseformer, using transformer and graph embedding techniques. In Phraseformer, each keyword candidate is presented by a vector which is the concatenation of the text and structure learning representations. Phraseformer takes the advantages of recent researches such as BERT and ExEm to preserve both representations. Also, the Phraseformer treats the key-phrase extraction task as a sequence labeling problem solved using classification task. Results: We analyze the performance of Phraseformer on three datasets including Inspec, SemEval2010 and SemEval 2017 by F1-score. Also, we investigate the performance of different classifiers on Phraseformer method over Inspec dataset. Experimental results demonstrate the effectiveness of Phraseformer method over the three datasets used. Additionally, the Random Forest classifier gain the highest F1-score among all classifiers. Conclusions: Due to the fact that the combination of BERT and ExEm is more meaningful and can better represent the semantic of words. Hence, Phraseformer significantly outperforms single-modality methods.
TopicBERT: A Transformer transfer learning based memory-graph approach for multimodal streaming social media topic detection
Aug 16, 2020

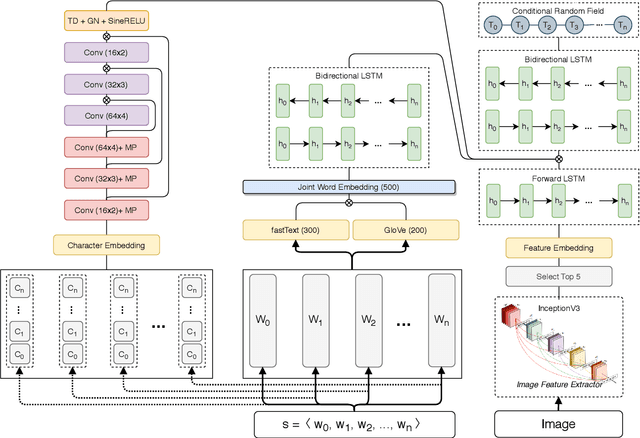

Real time nature of social networks with bursty short messages and their respective large data scale spread among vast variety of topics are research interest of many researchers. These properties of social networks which are known as 5'Vs of big data has led to many unique and enlightenment algorithms and techniques applied to large social networking datasets and data streams. Many of these researches are based on detection and tracking of hot topics and trending social media events that help revealing many unanswered questions. These algorithms and in some cases software products mostly rely on the nature of the language itself. Although, other techniques such as unsupervised data mining methods are language independent but many requirements for a comprehensive solution are not met. Many research issues such as noisy sentences that adverse grammar and new online user invented words are challenging maintenance of a good social network topic detection and tracking methodology; The semantic relationship between words and in most cases, synonyms are also ignored by many of these researches. In this research, we use Transformers combined with an incremental community detection algorithm. Transformer in one hand, provides the semantic relation between words in different contexts. On the other hand, the proposed graph mining technique enhances the resulting topics with aid of simple structural rules. Named entity recognition from multimodal data, image and text, labels the named entities with entity type and the extracted topics are tuned using them. All operations of proposed system has been applied with big social data perspective under NoSQL technologies. In order to present a working and systematic solution, we combined MongoDB with Neo4j as two major database systems of our work. The proposed system shows higher precision and recall compared to other methods in three different datasets.
Automatic Personality Prediction; an Enhanced Method Using Ensemble Modeling
Jul 09, 2020
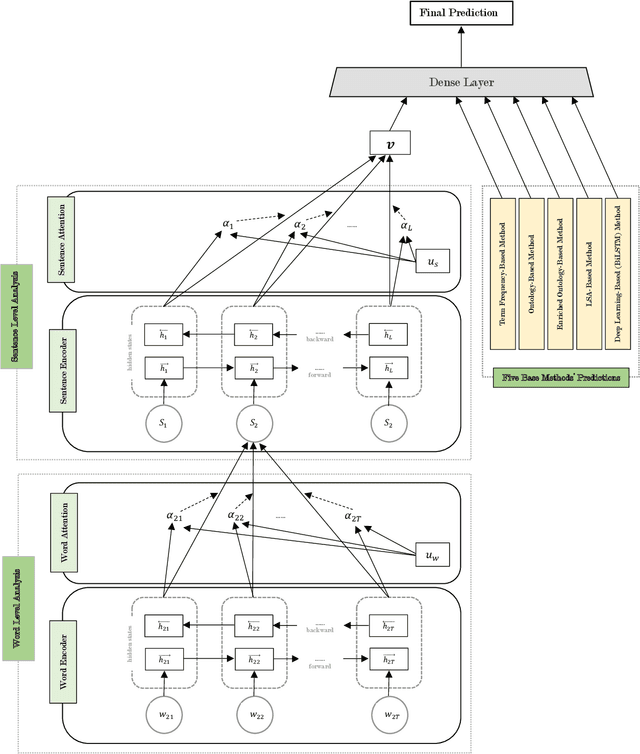
Human personality is significantly represented by those words which he/she uses in his/her speech or writing. As a consequence of spreading the information infrastructures (specifically the Internet and social media), human communications have reformed notably from face to face communication. Generally, Automatic Personality Prediction (or Perception) (APP) is the automated forecasting of the personality on different types of human generated/exchanged contents (like text, speech, image, video, etc.). The major objective of this study is to enhance the accuracy of APP from the text. To this end, we suggest five new APP methods including term frequency vector-based, ontology-based, enriched ontology-based, latent semantic analysis (LSA)-based, and deep learning-based (BiLSTM) methods. These methods as the base ones, contribute to each other to enhance the APP accuracy through ensemble modeling (stacking) based on a hierarchical attention network (HAN) as the meta-model. The results show that ensemble modeling enhances the accuracy of APP.
A Model to Measure the Spread Power of Rumors
Feb 27, 2020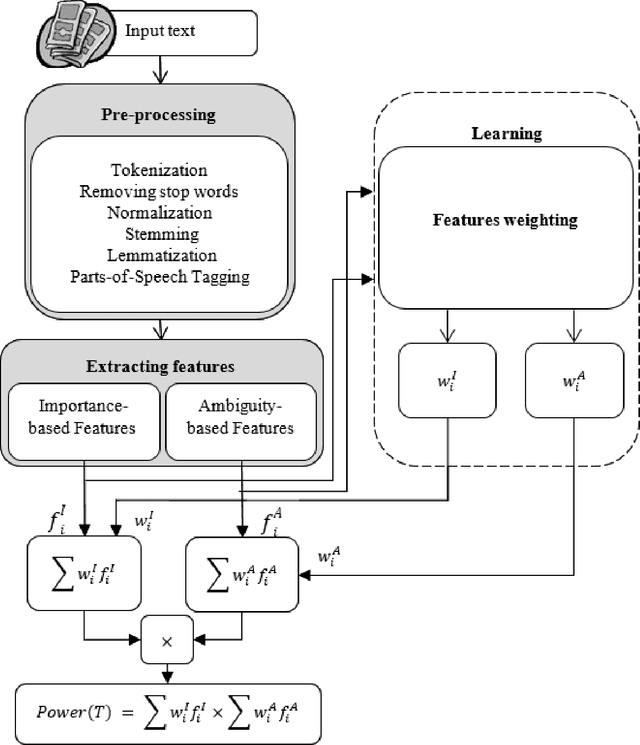
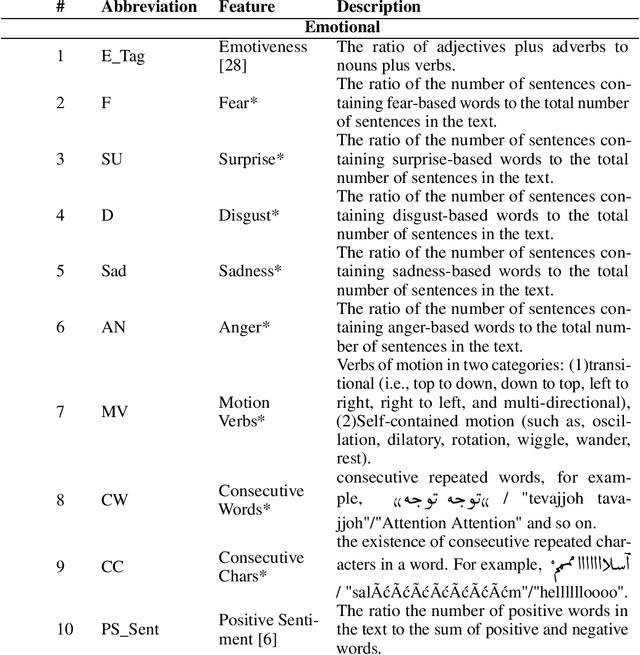
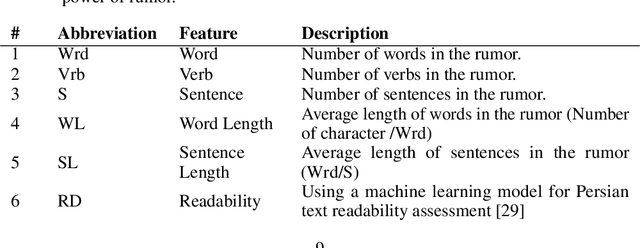

Nowadays, a significant portion of daily interacted posts in social media are infected by rumors. This study investigates the problem of rumor analysis in different areas from other researches. It tackles the unaddressed problem related to calculating the Spread Power of Rumor (SPR) for the first time and seeks to examine the spread power as the function of multi-contextual features. For this purpose, the theory of Allport and Postman will be adopted. In which it claims that there are two key factors determinant to the spread power of rumors, namely importance and ambiguity. The proposed Rumor Spread Power Measurement Model (RSPMM) computes SPR by utilizing a textual-based approach, which entails contextual features to compute the spread power of the rumors in two categories: False Rumor (FR) and True Rumor (TR). Totally 51 contextual features are introduced to measure SPR and their impact on classification are investigated, then 42 features in two categories "importance" (28 features) and "ambiguity" (14 features) are selected to compute SPR. The proposed RSPMM is verified on two labelled datasets, which are collected from Twitter and Telegram. The results show that (i) the proposed new features are effective and efficient to discriminate between FRs and TRs. (ii) the proposed RSPMM approach focused only on contextual features while existing techniques are based on Structure and Content features, but RSPMM achieves considerably outstanding results (F-measure=83%). (iii) The result of T-Test shows that SPR criteria can significantly distinguish between FR and TR, besides it can be useful as a new method to verify the trueness of rumors.