 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
Paper and Code
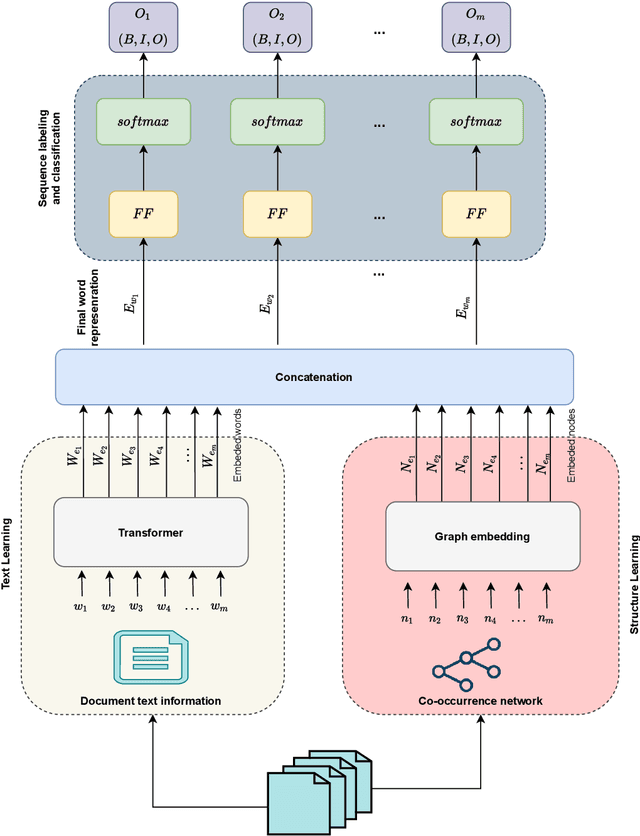
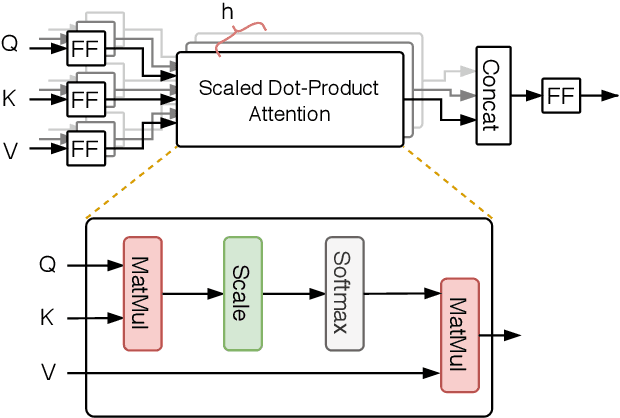
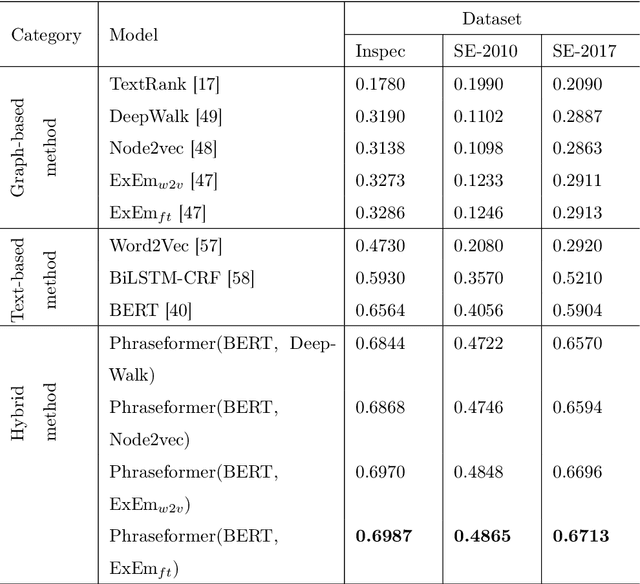
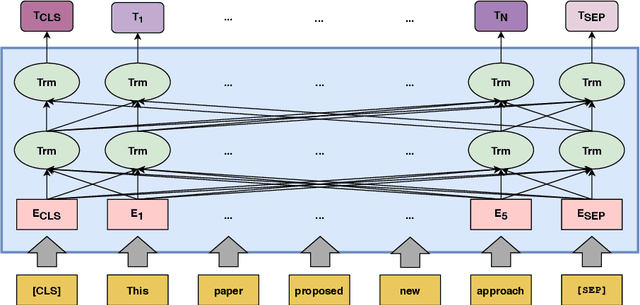
Background: Keyword extraction is a popular research topic in the field of natural language processing. Keywords are terms that describe the most relevant information in a document. The main problem that researchers are facing is how to efficiently and accurately extract the core keywords from a document. However, previous keyword extraction approaches have utilized the text and graph features, there is the lack of models that can properly learn and combine these features in a best way. Methods: In this paper, we develop a multimodal Key-phrase extraction approach, namely Phraseformer, using transformer and graph embedding techniques. In Phraseformer, each keyword candidate is presented by a vector which is the concatenation of the text and structure learning representations. Phraseformer takes the advantages of recent researches such as BERT and ExEm to preserve both representations. Also, the Phraseformer treats the key-phrase extraction task as a sequence labeling problem solved using classification task. Results: We analyze the performance of Phraseformer on three datasets including Inspec, SemEval2010 and SemEval 2017 by F1-score. Also, we investigate the performance of different classifiers on Phraseformer method over Inspec dataset. Experimental results demonstrate the effectiveness of Phraseformer method over the three datasets used. Additionally, the Random Forest classifier gain the highest F1-score among all classifiers. Conclusions: Due to the fact that the combination of BERT and ExEm is more meaningful and can better represent the semantic of words. Hence, Phraseformer significantly outperforms single-modality methods.