 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPEC: Manifold-Preserved EEG Classification via an Ensemble of Clustering-Based Classifiers
Apr 30, 2025


Accurate classification of EEG signals is crucial for brain-computer interfaces (BCIs) and neuroprosthetic applications, yet many existing methods fail to account for the non-Euclidean, manifold structure of EEG data, resulting in suboptimal performance. Preserving this manifold information is essential to capture the true geometry of EEG signals, but traditional classification techniques largely overlook this need. To this end, we propose MPEC (Manifold-Preserved EEG Classification via an Ensemble of Clustering-Based Classifiers), that introduces two key innovations: (1) a feature engineering phase that combines covariance matrices and Radial Basis Function (RBF) kernels to capture both linear and non-linear relationships among EEG channels, and (2) a clustering phase that employs a modified K-means algorithm tailored for the Riemannian manifold space, ensuring local geometric sensitivity. Ensembling multiple clustering-based classifiers, MPEC achieves superior results, validated by significant improvements on the BCI Competition IV dataset 2a.
RSAttAE: An Information-Aware Attention-based Autoencoder Recommender System
Feb 10, 2025Recommender systems play a crucial role in modern life, including information retrieval, the pharmaceutical industry, retail, and entertainment. The entertainment sector, in particular, attracts significant attention and generates substantial profits. This work proposes a new method for predicting unknown user-movie ratings to enhance customer satisfaction. To achieve this, we utilize the MovieLens 100K dataset. Our approach introduces an attention-based autoencoder to create meaningful representations and the XGBoost method for rating predictions. The results demonstrate that our proposal outperforms most of the existing state-of-the-art methods. Availability: github.com/ComputationIASBS/RecommSys
RELIANCE: Reliable Ensemble Learning for Information and News Credibility Evaluation
Jan 17, 2024



In the era of information proliferation, discerning the credibility of news content poses an ever-growing challenge. This paper introduces RELIANCE, a pioneering ensemble learning system designed for robust information and fake news credibility evaluation. Comprising five diverse base models, including Support Vector Machine (SVM), naive Bayes, logistic regression, random forest, and Bidirectional Long Short Term Memory Networks (BiLSTMs), RELIANCE employs an innovative approach to integrate their strengths, harnessing the collective intelligence of the ensemble for enhanced accuracy. Experiments demonstrate the superiority of RELIANCE over individual models, indicating its efficacy in distinguishing between credible and non-credible information sources. RELIANCE, also surpasses baseline models in information and news credibility assessment, establishing itself as an effective solution for evaluating the reliability of information sources.
Unsupervised Broadcast News Summarization; a comparative study on Maximal Marginal Relevance (MMR) and Latent Semantic Analysis (LSA)
Jan 05, 2023The methods of automatic speech summarization are classified into two groups: supervised and unsupervised methods. Supervised methods are based on a set of features, while unsupervised methods perform summarization based on a set of rules. Latent Semantic Analysis (LSA) and Maximal Marginal Relevance (MMR) are considered the most important and well-known unsupervised methods in automatic speech summarization. This study set out to investigate the performance of two aforementioned unsupervised methods in transcriptions of Persian broadcast news summarization. The results show that in generic summarization, LSA outperforms MMR, and in query-based summarization, MMR outperforms LSA in broadcast news summarization.
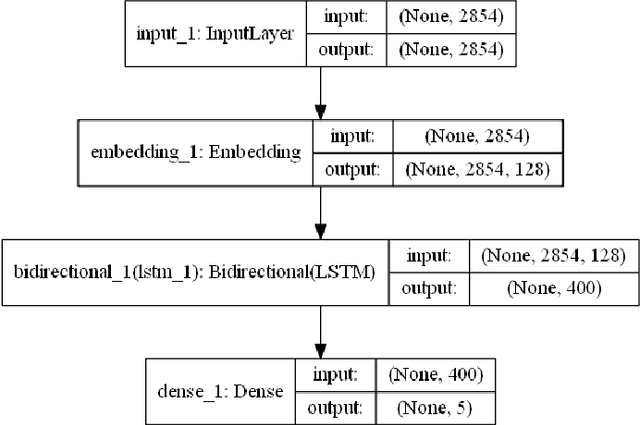
Text-Based Automatic Personality Prediction Using KGrAt-Net; A Knowledge Graph Attention Network Classifier
May 27, 2022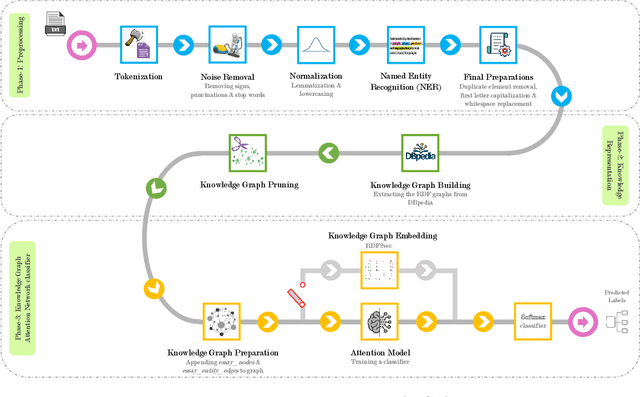

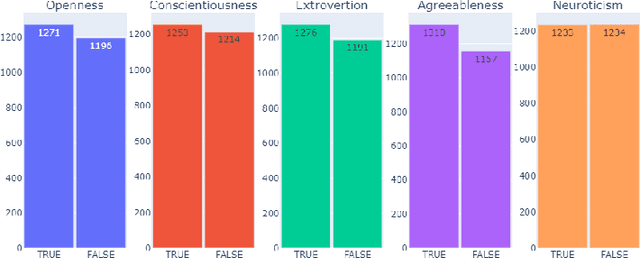
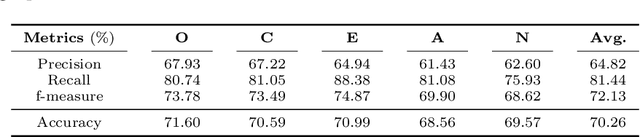
Nowadays, a tremendous amount of human communications take place on the Internet-based communication infrastructures, like social networks, email, forums, organizational communication platforms, etc. Indeed, the automatic prediction or assessment of individuals' personalities through their written or exchanged text would be advantageous to ameliorate the relationships among them. To this end, this paper aims to propose KGrAt-Net which is a Knowledge Graph Attention Network text classifier. For the first time, it applies the knowledge graph attention network to perform Automatic Personality Prediction (APP), according to the Big Five personality traits. After performing some preprocessing activities, first, it tries to acquire a knowingful representation of the knowledge behind the concepts in the input text through building its equivalent knowledge graph. A knowledge graph is a graph-based data model that formally represents the semantics of the existing concepts in the input text and models the knowledge behind them. Then, applying the attention mechanism, it efforts to pay attention to the most relevant parts of the graph to predict the personality traits of the input text. The results demonstrated that KGrAt-Net considerably improved the personality prediction accuracies. Furthermore, KGrAt-Net also uses the knowledge graphs' embeddings to enrich the classification, which makes it even more accurate in APP.
Knowledge Graph-Enabled Text-Based Automatic Personality Prediction
Mar 17, 2022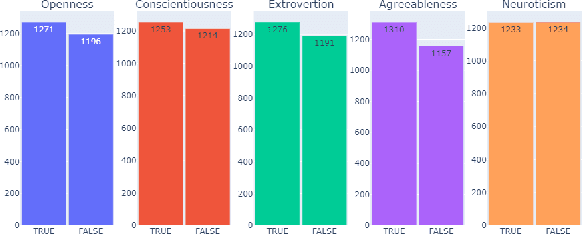

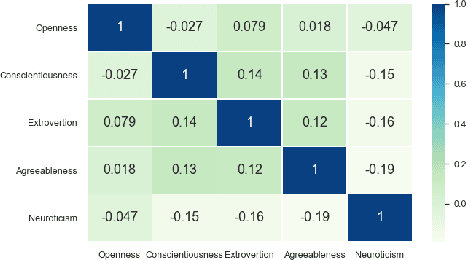

How people think, feel, and behave, primarily is a representation of their personality characteristics. By being conscious of personality characteristics of individuals whom we are dealing with or decided to deal with, one can competently ameliorate the relationship, regardless of its type. With the rise of Internet-based communication infrastructures (social networks, forums, etc.), a considerable amount of human communications take place there. The most prominent tool in such communications, is the language in written and spoken form that adroitly encodes all those essential personality characteristics of individuals. Text-based Automatic Personality Prediction (APP) is the automated forecasting of the personality of individuals based on the generated/exchanged text contents. This paper presents a novel knowledge graph-enabled approach to text-based APP that relies on the Big Five personality traits. To this end, given a text a knowledge graph which is a set of interlinked descriptions of concepts, was built through matching the input text's concepts with DBpedia knowledge base entries. Then, due to achieving more powerful representation the graph was enriched with the DBpedia ontology, NRC Emotion Intensity Lexicon, and MRC psycholinguistic database information. Afterwards, the knowledge graph which is now a knowledgeable alternative for the input text was embedded to yield an embedding matrix. Finally, to perform personality predictions the resulting embedding matrix was fed to four suggested deep learning models independently, which are based on convolutional neural network (CNN), simple recurrent neural network (RNN), long short term memory (LSTM) and bidirectional long short term memory (BiLSTM). The results indicated a considerable improvements in prediction accuracies in all of the suggested classifiers.
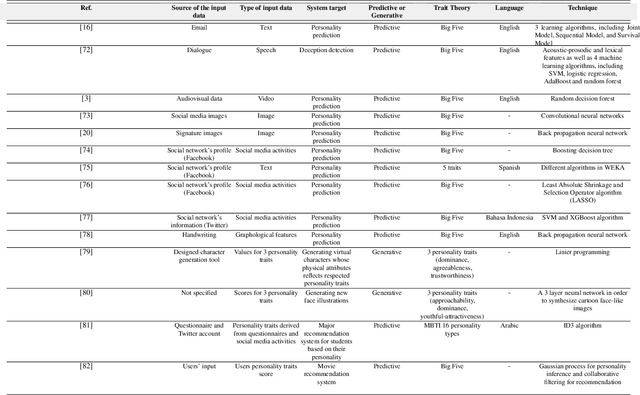
The state-of-the-art in text-based automatic personality prediction
Oct 04, 2021
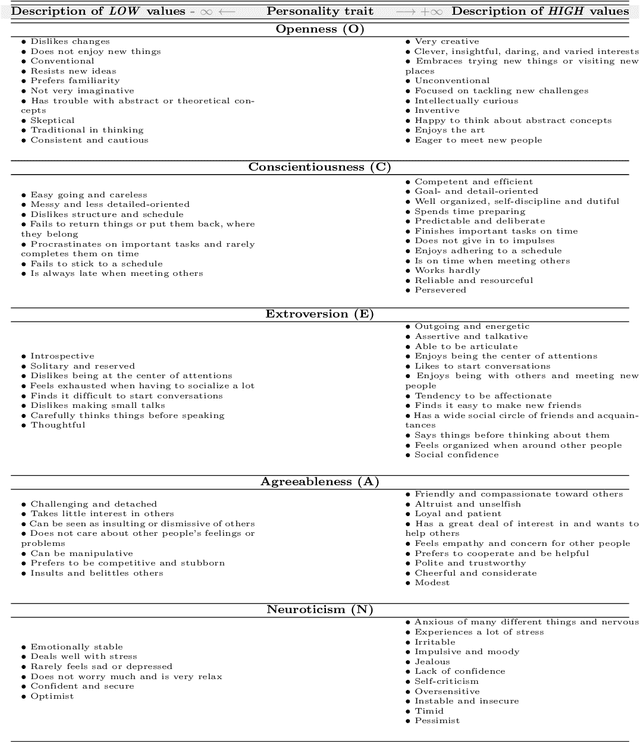
Personality detection is an old topic in psychology and Automatic Personality Prediction (or Perception) (APP) is the automated (computationally) forecasting of the personality on different types of human generated/exchanged contents (such as text, speech, image, video). The principal objective of this study is to offer a shallow (overall) review of natural language processing approaches on APP since 2010. With the advent of deep learning and following it transfer-learning and pre-trained model in NLP, APP research area has been a hot topic, so in this review, methods are categorized into three; pre-trained independent, pre-trained model based, multimodal approaches. Also, to achieve a comprehensive comparison, reported results are informed by datasets.
Phraseformer: Multimodal Key-phrase Extraction using Transformer and Graph Embedding
Jun 09, 2021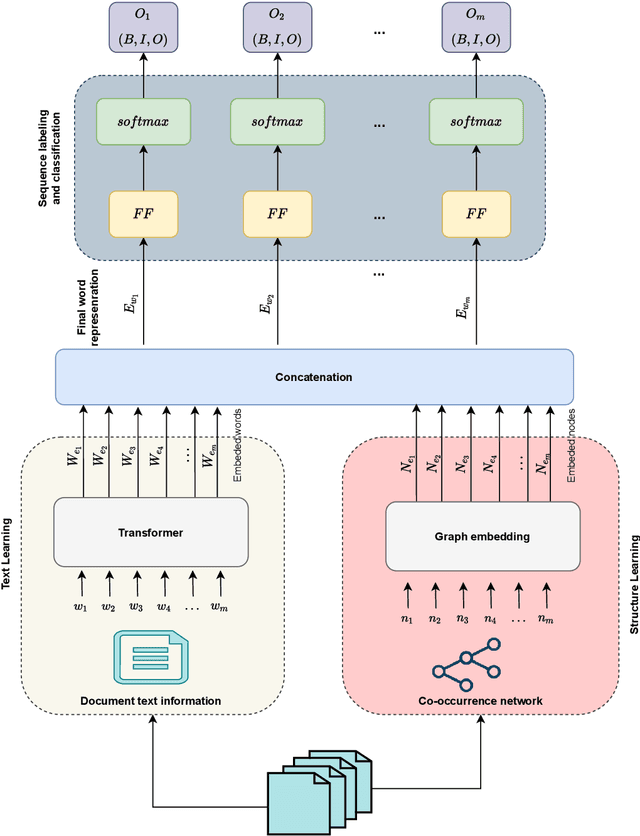
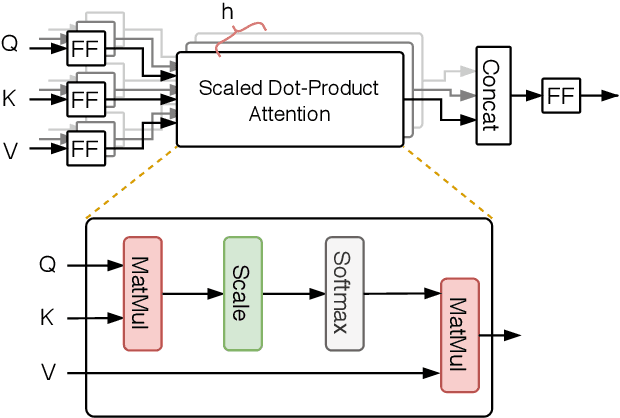
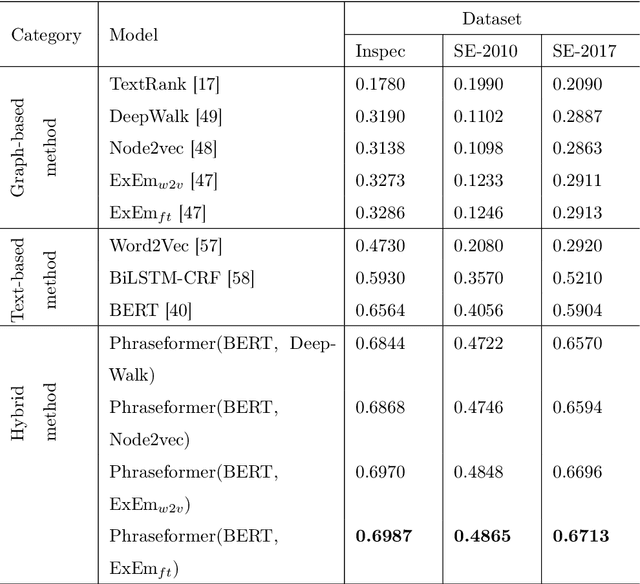
Background: Keyword extraction is a popular research topic in the field of natural language processing. Keywords are terms that describe the most relevant information in a document. The main problem that researchers are facing is how to efficiently and accurately extract the core keywords from a document. However, previous keyword extraction approaches have utilized the text and graph features, there is the lack of models that can properly learn and combine these features in a best way. Methods: In this paper, we develop a multimodal Key-phrase extraction approach, namely Phraseformer, using transformer and graph embedding techniques. In Phraseformer, each keyword candidate is presented by a vector which is the concatenation of the text and structure learning representations. Phraseformer takes the advantages of recent researches such as BERT and ExEm to preserve both representations. Also, the Phraseformer treats the key-phrase extraction task as a sequence labeling problem solved using classification task. Results: We analyze the performance of Phraseformer on three datasets including Inspec, SemEval2010 and SemEval 2017 by F1-score. Also, we investigate the performance of different classifiers on Phraseformer method over Inspec dataset. Experimental results demonstrate the effectiveness of Phraseformer method over the three datasets used. Additionally, the Random Forest classifier gain the highest F1-score among all classifiers. Conclusions: Due to the fact that the combination of BERT and ExEm is more meaningful and can better represent the semantic of words. Hence, Phraseformer significantly outperforms single-modality methods.
Automatic Personality Prediction; an Enhanced Method Using Ensemble Modeling
Jul 09, 2020
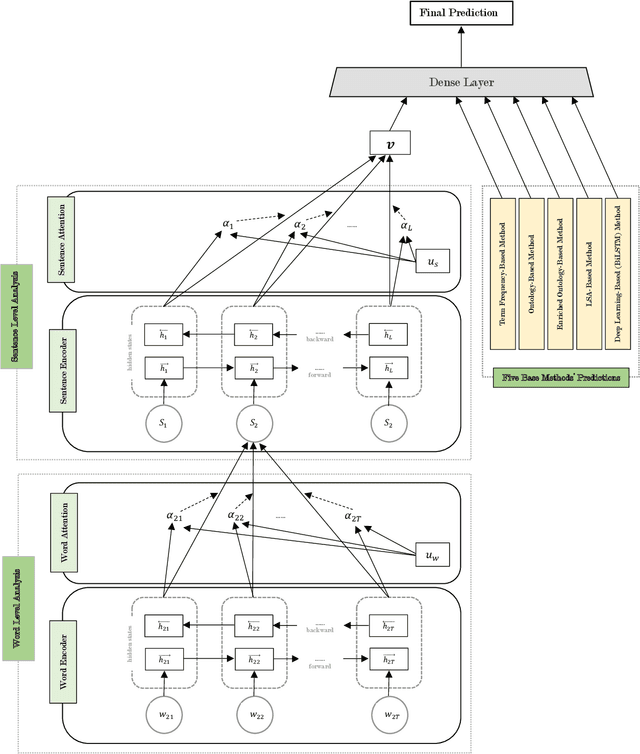
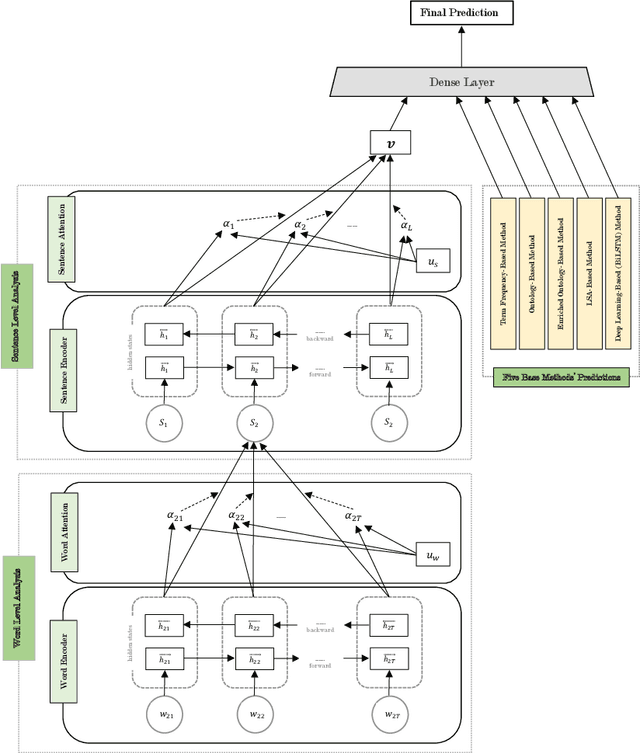
Human personality is significantly represented by those words which he/she uses in his/her speech or writing. As a consequence of spreading the information infrastructures (specifically the Internet and social media), human communications have reformed notably from face to face communication. Generally, Automatic Personality Prediction (or Perception) (APP) is the automated forecasting of the personality on different types of human generated/exchanged contents (like text, speech, image, video, etc.). The major objective of this study is to enhance the accuracy of APP from the text. To this end, we suggest five new APP methods including term frequency vector-based, ontology-based, enriched ontology-based, latent semantic analysis (LSA)-based, and deep learning-based (BiLSTM) methods. These methods as the base ones, contribute to each other to enhance the APP accuracy through ensemble modeling (stacking) based on a hierarchical attention network (HAN) as the meta-model. The results show that ensemble modeling enhances the accuracy of APP.
A Model to Measure the Spread Power of Rumors
Feb 27, 2020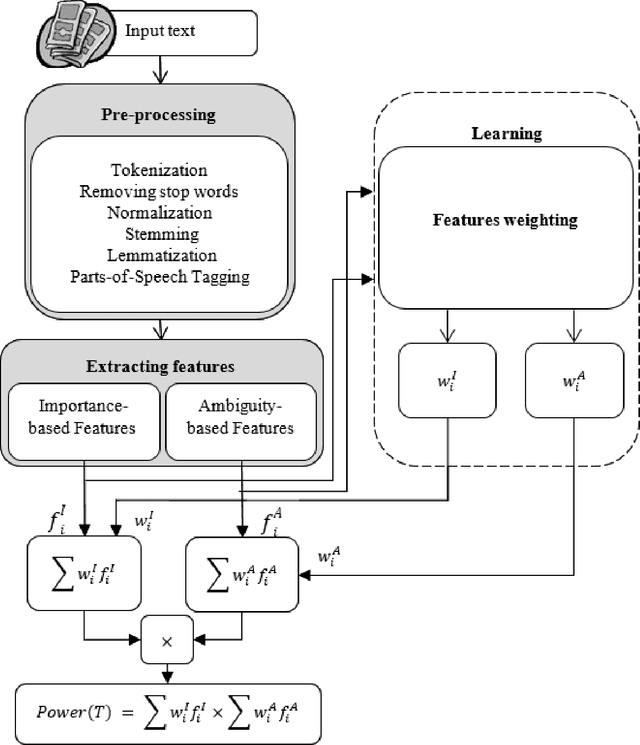
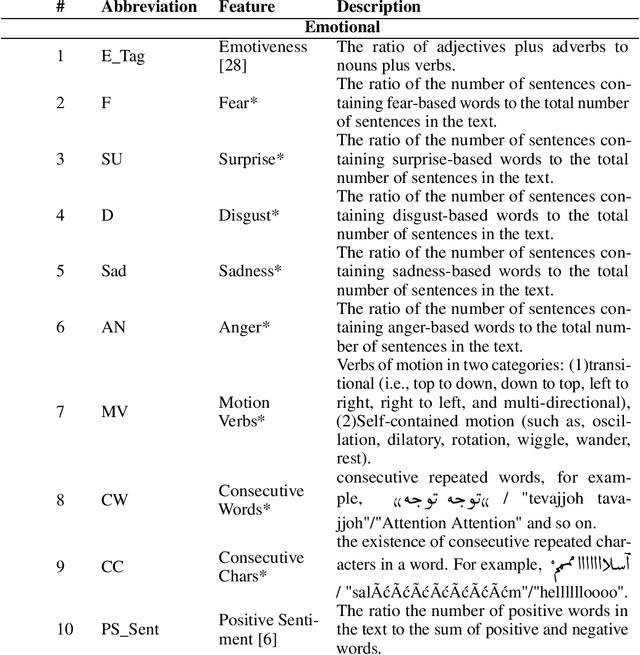
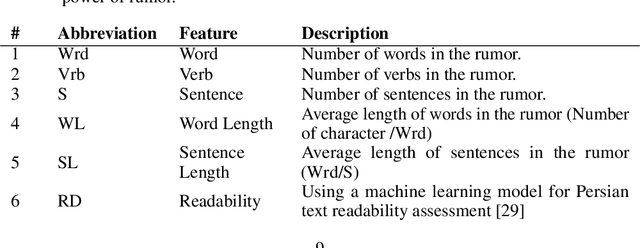

Nowadays, a significant portion of daily interacted posts in social media are infected by rumors. This study investigates the problem of rumor analysis in different areas from other researches. It tackles the unaddressed problem related to calculating the Spread Power of Rumor (SPR) for the first time and seeks to examine the spread power as the function of multi-contextual features. For this purpose, the theory of Allport and Postman will be adopted. In which it claims that there are two key factors determinant to the spread power of rumors, namely importance and ambiguity. The proposed Rumor Spread Power Measurement Model (RSPMM) computes SPR by utilizing a textual-based approach, which entails contextual features to compute the spread power of the rumors in two categories: False Rumor (FR) and True Rumor (TR). Totally 51 contextual features are introduced to measure SPR and their impact on classification are investigated, then 42 features in two categories "importance" (28 features) and "ambiguity" (14 features) are selected to compute SPR. The proposed RSPMM is verified on two labelled datasets, which are collected from Twitter and Telegram. The results show that (i) the proposed new features are effective and efficient to discriminate between FRs and TRs. (ii) the proposed RSPMM approach focused only on contextual features while existing techniques are based on Structure and Content features, but RSPMM achieves considerably outstanding results (F-measure=83%). (iii) The result of T-Test shows that SPR criteria can significantly distinguish between FR and TR, besides it can be useful as a new method to verify the trueness of rumors.