 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Pipelines: A Fundamental Study on the Rise of Generative-Retrieval Architectures in Web Research
Feb 19, 2026Web research and practices have evolved significantly over time, offering users diverse and accessible solutions across a wide range of tasks. While advanced concepts such as Web 4.0 have emerged from mature technologies, the introduction of large language models (LLMs) has profoundly influenced both the field and its applications. This wave of LLMs has permeated science and technology so deeply that no area remains untouched. Consequently, LLMs are reshaping web research and development, transforming traditional pipelines into generative solutions for tasks like information retrieval, question answering, recommendation systems, and web analytics. They have also enabled new applications such as web-based summarization and educational tools. This survey explores recent advances in the impact of LLMs-particularly through the use of retrieval-augmented generation (RAG)-on web research and industry. It discusses key developments, open challenges, and future directions for enhancing web solutions with LLMs.
On the Universality of Transformer Architectures; How Much Attention Is Enough?
Dec 20, 2025
Transformers are crucial across many AI fields, such as large language models, computer vision, and reinforcement learning. This prominence stems from the architecture's perceived universality and scalability compared to alternatives. This work examines the problem of universality in Transformers, reviews recent progress, including architectural refinements such as structural minimality and approximation rates, and surveys state-of-the-art advances that inform both theoretical and practical understanding. Our aim is to clarify what is currently known about Transformers expressiveness, separate robust guarantees from fragile ones, and identify key directions for future theoretical research.
RSAttAE: An Information-Aware Attention-based Autoencoder Recommender System
Feb 10, 2025Recommender systems play a crucial role in modern life, including information retrieval, the pharmaceutical industry, retail, and entertainment. The entertainment sector, in particular, attracts significant attention and generates substantial profits. This work proposes a new method for predicting unknown user-movie ratings to enhance customer satisfaction. To achieve this, we utilize the MovieLens 100K dataset. Our approach introduces an attention-based autoencoder to create meaningful representations and the XGBoost method for rating predictions. The results demonstrate that our proposal outperforms most of the existing state-of-the-art methods. Availability: github.com/ComputationIASBS/RecommSys
Longest Common Substring in Longest Common Subsequence's Solution Service: A Novel Hyper-Heuristic
Dec 03, 2022



The Longest Common Subsequence (LCS) is the problem of finding a subsequence among a set of strings that has two properties of being common to all and is the longest. The LCS has applications in computational biology and text editing, among many others. Due to the NP-hardness of the general longest common subsequence, numerous heuristic algorithms and solvers have been proposed to give the best possible solution for different sets of strings. None of them has the best performance for all types of sets. In addition, there is no method to specify the type of a given set of strings. Besides that, the available hyper-heuristic is not efficient and fast enough to solve this problem in real-world applications. This paper proposes a novel hyper-heuristic to solve the longest common subsequence problem using a novel criterion to classify a set of strings based on their similarity. To do this, we offer a general stochastic framework to identify the type of a given set of strings. Following that, we introduce the set similarity dichotomizer ($S^2D$) algorithm based on the framework that divides the type of sets into two. This algorithm is introduced for the first time in this paper and opens a new way to go beyond the current LCS solvers. Then, we present a novel hyper-heuristic that exploits the $S^2D$ and one of the internal properties of the set to choose the best matching heuristic among a set of heuristics. We compare the results on benchmark datasets with the best heuristics and hyper-heuristics. The results show a higher performance of our proposed hyper-heuristic in both quality of solutions and run time factors.
EEPT: Early Discovery of Emerging Entities in Twitter with Semantic Similarity
Jul 06, 2022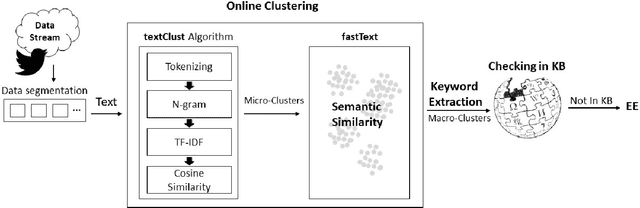
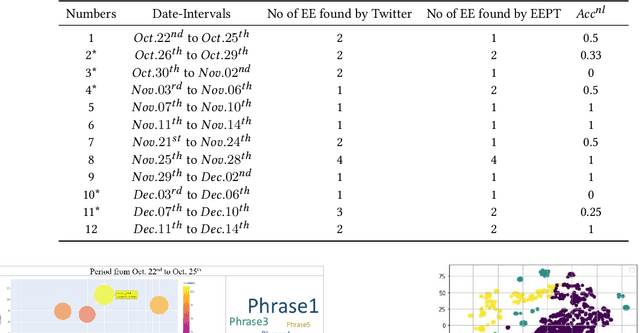
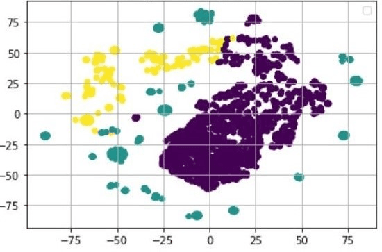
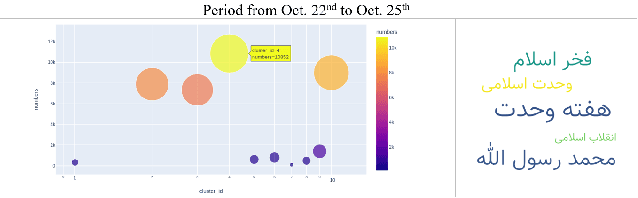
Some events which happen in the future could be important for companies, governments, and even our personal life. Prediction of these events before their establishment is helpful for efficient decision-making. We call such events emerging entities. They have not taken place yet, and there is no information about them in KB. However, some clues exist in different areas, especially on social media. Thus, retrieving these type of entities are possible. This paper proposes a method of early discovery of emerging entities. We use semantic clustering of short messages. To evaluate the performance of our proposal, we devise and utilize a performance evaluation metric. The results show that our proposed method finds those emerging entities of which Twitter trends are not always capable.