 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning-based approach for tomato classification in complex scenes
Jan 26, 2024



Tracking ripening tomatoes is time consuming and labor intensive. Artificial intelligence technologies combined with those of computer vision can help users optimize the process of monitoring the ripening status of plants. To this end, we have proposed a tomato ripening monitoring approach based on deep learning in complex scenes. The objective is to detect mature tomatoes and harvest them in a timely manner. The proposed approach is declined in two parts. Firstly, the images of the scene are transmitted to the pre-processing layer. This process allows the detection of areas of interest (area of the image containing tomatoes). Then, these images are used as input to the maturity detection layer. This layer, based on a deep neural network learning algorithm, classifies the tomato thumbnails provided to it in one of the following five categories: green, brittle, pink, pale red, mature red. The experiments are based on images collected from the internet gathered through searches using tomato state across diverse languages including English, German, French, and Spanish. The experimental results of the maturity detection layer on a dataset composed of images of tomatoes taken under the extreme conditions, gave a good classification rate.
TopicBERT: A Transformer transfer learning based memory-graph approach for multimodal streaming social media topic detection
Aug 16, 2020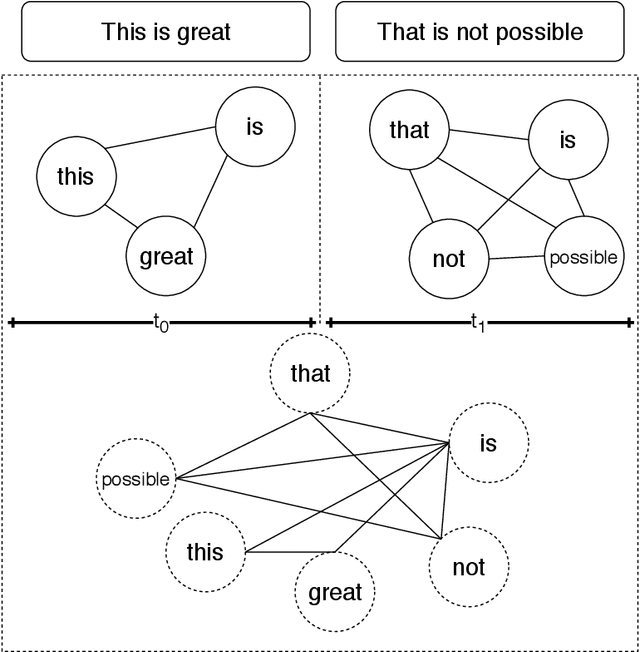


Real time nature of social networks with bursty short messages and their respective large data scale spread among vast variety of topics are research interest of many researchers. These properties of social networks which are known as 5'Vs of big data has led to many unique and enlightenment algorithms and techniques applied to large social networking datasets and data streams. Many of these researches are based on detection and tracking of hot topics and trending social media events that help revealing many unanswered questions. These algorithms and in some cases software products mostly rely on the nature of the language itself. Although, other techniques such as unsupervised data mining methods are language independent but many requirements for a comprehensive solution are not met. Many research issues such as noisy sentences that adverse grammar and new online user invented words are challenging maintenance of a good social network topic detection and tracking methodology; The semantic relationship between words and in most cases, synonyms are also ignored by many of these researches. In this research, we use Transformers combined with an incremental community detection algorithm. Transformer in one hand, provides the semantic relation between words in different contexts. On the other hand, the proposed graph mining technique enhances the resulting topics with aid of simple structural rules. Named entity recognition from multimodal data, image and text, labels the named entities with entity type and the extracted topics are tuned using them. All operations of proposed system has been applied with big social data perspective under NoSQL technologies. In order to present a working and systematic solution, we combined MongoDB with Neo4j as two major database systems of our work. The proposed system shows higher precision and recall compared to other methods in three different datasets.
BERTERS: Multimodal Representation Learning for Expert Recommendation System with Transformer
Jun 30, 2020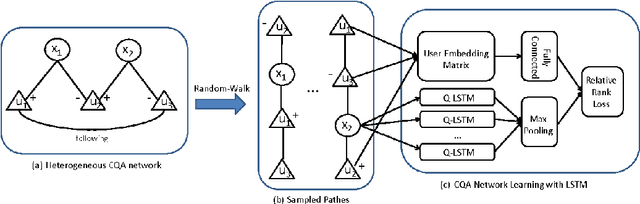

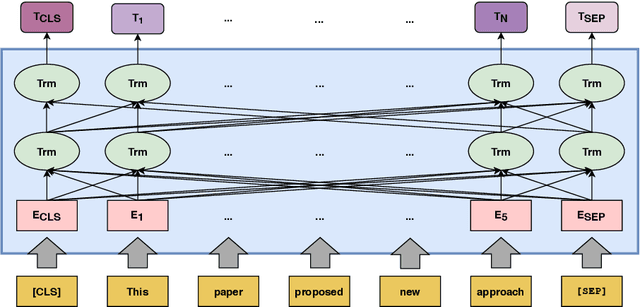
The objective of an expert recommendation system is to trace a set of candidates' expertise and preferences, recognize their expertise patterns, and identify experts. In this paper, we introduce a multimodal classification approach for expert recommendation system (BERTERS). In our proposed system, the modalities are derived from text (articles published by candidates) and graph (their co-author connections) information. BERTERS converts text into a vector using the Bidirectional Encoder Representations from Transformer (BERT). Also, a graph Representation technique called ExEm is used to extract the features of candidates from the co-author network. Final representation of a candidate is the concatenation of these vectors and other features. Eventually, a classifier is built on the concatenation of features. This multimodal approach can be used in both the academic community and the community question answering. To verify the effectiveness of BERTERS, we analyze its performance on multi-label classification and visualization tasks.
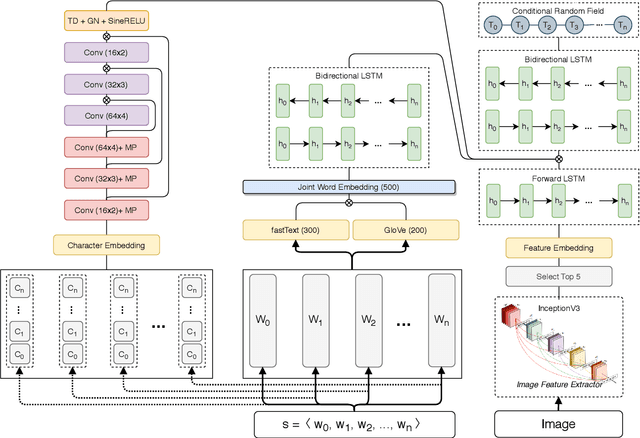
A multimodal deep learning approach for named entity recognition from social media
Jan 19, 2020

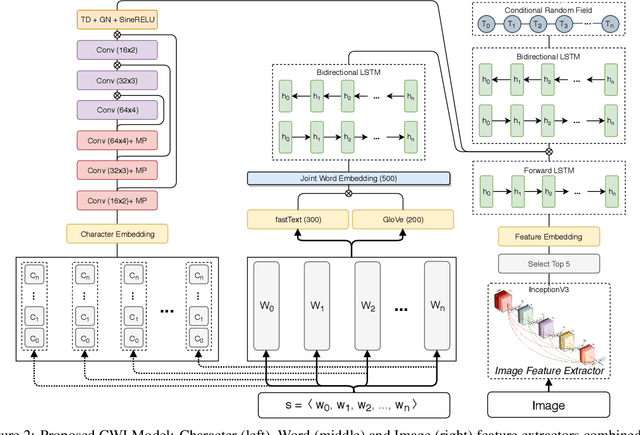
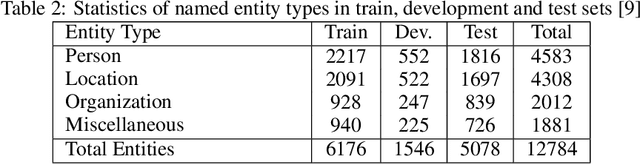
Named Entity Recognition (NER) from social media posts is a challenging task. User generated content which forms the nature of social media, is noisy and contains grammatical and linguistic errors. This noisy content makes it much harder for tasks such as named entity recognition. However some applications like automatic journalism or information retrieval from social media, require more information about entities mentioned in groups of social media posts. Conventional methods applied to structured and well typed documents provide acceptable results while compared to new user generated media, these methods are not satisfactory. One valuable piece of information about an entity is the related image to the text. Combining this multimodal data reduces ambiguity and provides wider information about the entities mentioned. In order to address this issue, we propose a novel deep learning approach utilizing multimodal deep learning. Our solution is able to provide more accurate results on named entity recognition task. Experimental results, namely the precision, recall and F1 score metrics show the superiority of our work compared to other state-of-the-art NER solutions.
ExEm: Expert Embedding using dominating set theory with deep learning approaches
Jan 16, 2020

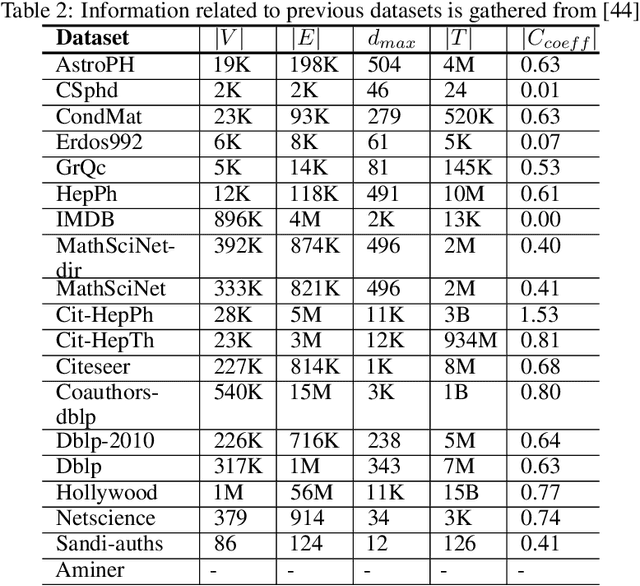
A collaborative network is a social network that is comprised of experts who cooperate with each other to fulfill a special goal. Analyzing the graph of this network yields meaningful information about the expertise of these experts and their subject areas. To perform the analysis, graph embedding techniques have emerged as a promising tool. Graph embedding attempts to represent graph nodes as low-dimensional vectors. In this paper, we propose a graph embedding method, called ExEm, which using dominating-set theory and deep learning approaches. In the proposed method, the dominating set theory is applied to the collaborative network and dominating nodes of this network are found. After that, a set of random walks is created which starts from dominating nodes (experts). The main condition for constricting these random walks is the existence of another dominating node. After making the walks that satisfy the stated conditions, they are stored as a sequence in a corpus. In the next step, the corpus is fed to the SKIP-GRAM neural network model. Word2vec, fastText and their combination are employed to train the neural network of the SKIP-GRAM model. Finally, the result is the low dimensional vectors of experts, called expert embeddings. Expert embeddings can be used for various purposes including accurately modeling experts' expertise or computing experts' scores in expert recommendation systems. Hence, we also introduce a novel strategy to calculate experts' scores by using the extracted expert embedding vectors. The effectiveness of ExEm is validated through assessing its performance on multi-label classification, link prediction, and recommendation tasks. We conduct extensive experiments on common datasets. Moreover in this study, we present data related to a co-author network formed by crawling the vast author profiles from Scopus.
Foreground-Background Segmentation Based on Codebook and Edge Detector
Oct 23, 2014

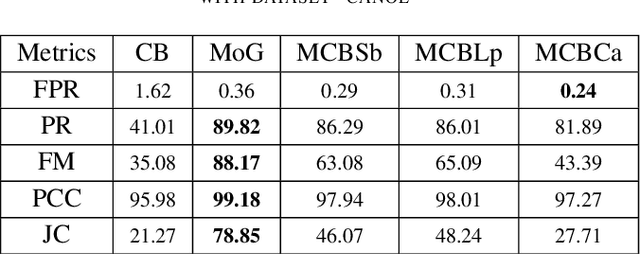
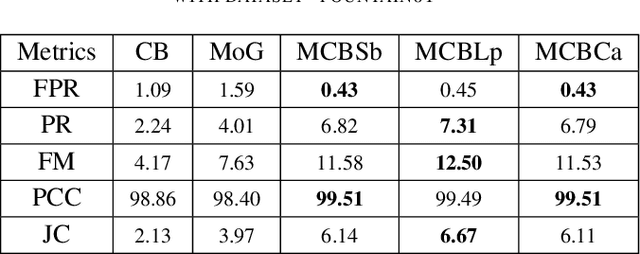
Background modeling techniques are used for moving object detection in video. Many algorithms exist in the field of object detection with different purposes. In this paper, we propose an improvement of moving object detection based on codebook segmentation. We associate the original codebook algorithm with an edge detection algorithm. Our goal is to prove the efficiency of using an edge detection algorithm with a background modeling algorithm. Throughout our study, we compared the quality of the moving object detection when codebook segmentation algorithm is associated with some standard edge detectors. In each case, we use frame-based metrics for the evaluation of the detection. The different results are presented and analyzed.