 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Image Modeling: A Survey
Aug 13, 2024



In this work, we survey recent studies on masked image modeling (MIM), an approach that emerged as a powerful self-supervised learning technique in computer vision. The MIM task involves masking some information, e.g. pixels, patches, or even latent representations, and training a model, usually an autoencoder, to predicting the missing information by using the context available in the visible part of the input. We identify and formalize two categories of approaches on how to implement MIM as a pretext task, one based on reconstruction and one based on contrastive learning. Then, we construct a taxonomy and review the most prominent papers in recent years. We complement the manually constructed taxonomy with a dendrogram obtained by applying a hierarchical clustering algorithm. We further identify relevant clusters via manually inspecting the resulting dendrogram. Our review also includes datasets that are commonly used in MIM research. We aggregate the performance results of various masked image modeling methods on the most popular datasets, to facilitate the comparison of competing methods. Finally, we identify research gaps and propose several interesting directions of future work.
Large Language Models: A Survey
Feb 20, 2024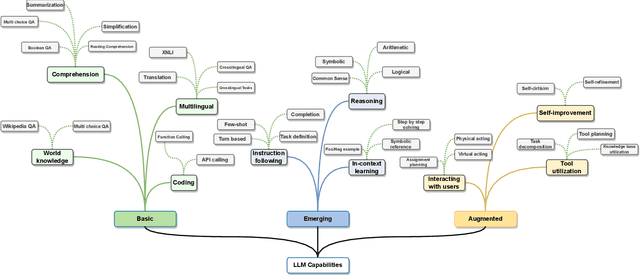
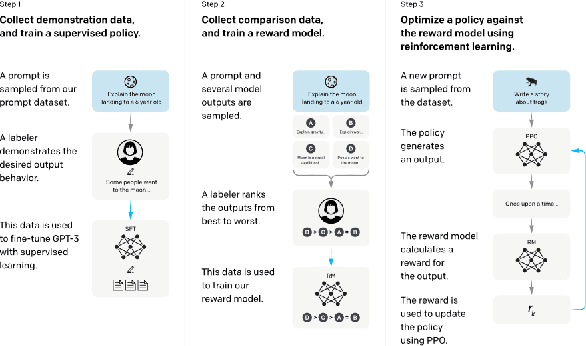
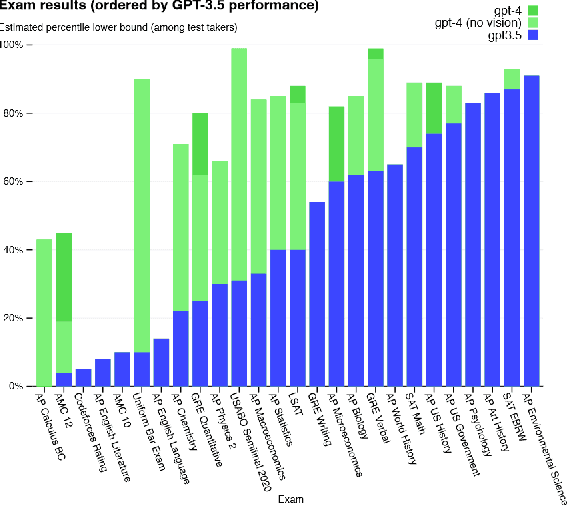
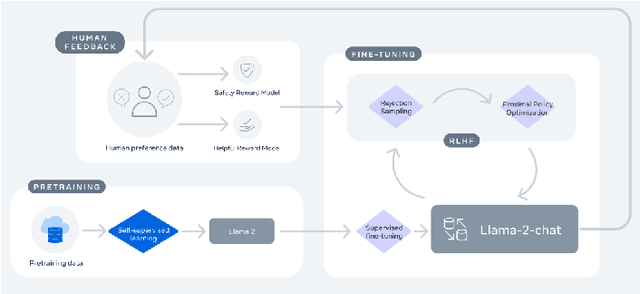
Large Language Models (LLMs) have drawn a lot of attention due to their strong performance on a wide range of natural language tasks, since the release of ChatGPT in November 2022. LLMs' ability of general-purpose language understanding and generation is acquired by training billions of model's parameters on massive amounts of text data, as predicted by scaling laws \cite{kaplan2020scaling,hoffmann2022training}. The research area of LLMs, while very recent, is evolving rapidly in many different ways. In this paper, we review some of the most prominent LLMs, including three popular LLM families (GPT, LLaMA, PaLM), and discuss their characteristics, contributions and limitations. We also give an overview of techniques developed to build, and augment LLMs. We then survey popular datasets prepared for LLM training, fine-tuning, and evaluation, review widely used LLM evaluation metrics, and compare the performance of several popular LLMs on a set of representative benchmarks. Finally, we conclude the paper by discussing open challenges and future research directions.
Show Me What and Tell Me How: Video Synthesis via Multimodal Conditioning
Mar 04, 2022


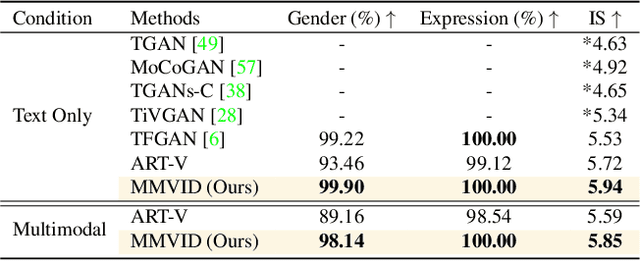
Most methods for conditional video synthesis use a single modality as the condition. This comes with major limitations. For example, it is problematic for a model conditioned on an image to generate a specific motion trajectory desired by the user since there is no means to provide motion information. Conversely, language information can describe the desired motion, while not precisely defining the content of the video. This work presents a multimodal video generation framework that benefits from text and images provided jointly or separately. We leverage the recent progress in quantized representations for videos and apply a bidirectional transformer with multiple modalities as inputs to predict a discrete video representation. To improve video quality and consistency, we propose a new video token trained with self-learning and an improved mask-prediction algorithm for sampling video tokens. We introduce text augmentation to improve the robustness of the textual representation and diversity of generated videos. Our framework can incorporate various visual modalities, such as segmentation masks, drawings, and partially occluded images. It can generate much longer sequences than the one used for training. In addition, our model can extract visual information as suggested by the text prompt, e.g., "an object in image one is moving northeast", and generate corresponding videos. We run evaluations on three public datasets and a newly collected dataset labeled with facial attributes, achieving state-of-the-art generation results on all four.
Modern Augmented Reality: Applications, Trends, and Future Directions
Feb 24, 2022



Augmented reality (AR) is one of the relatively old, yet trending areas in the intersection of computer vision and computer graphics with numerous applications in several areas, from gaming and entertainment, to education and healthcare. Although it has been around for nearly fifty years, it has seen a lot of interest by the research community in the recent years, mainly because of the huge success of deep learning models for various computer vision and AR applications, which made creating new generations of AR technologies possible. This work tries to provide an overview of modern augmented reality, from both application-level and technical perspective. We first give an overview of main AR applications, grouped into more than ten categories. We then give an overview of around 100 recent promising machine learning based works developed for AR systems, such as deep learning works for AR shopping (clothing, makeup), AR based image filters (such as Snapchat's lenses), AR animations, and more. In the end we discuss about some of the current challenges in AR domain, and the future directions in this area.
Going Deeper Into Face Detection: A Survey
Apr 13, 2021
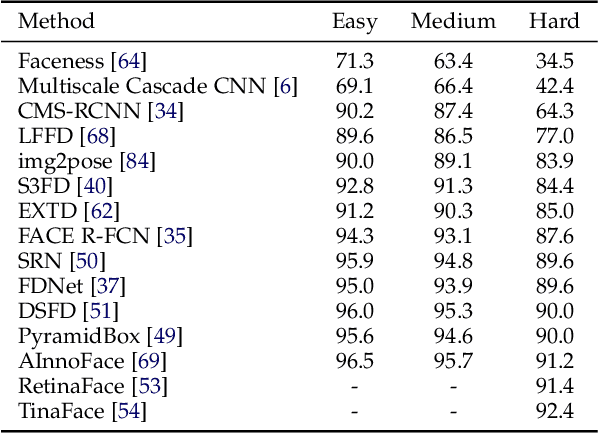
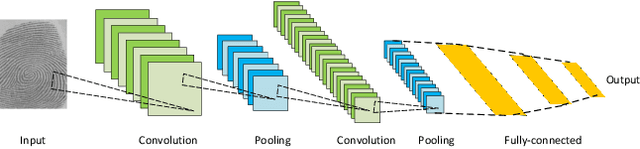
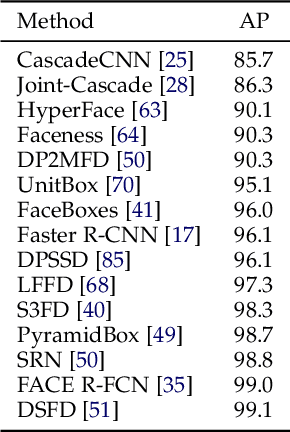
Face detection is a crucial first step in many facial recognition and face analysis systems. Early approaches for face detection were mainly based on classifiers built on top of hand-crafted features extracted from local image regions, such as Haar Cascades and Histogram of Oriented Gradients. However, these approaches were not powerful enough to achieve a high accuracy on images of from uncontrolled environments. With the breakthrough work in image classification using deep neural networks in 2012, there has been a huge paradigm shift in face detection. Inspired by the rapid progress of deep learning in computer vision, many deep learning based frameworks have been proposed for face detection over the past few years, achieving significant improvements in accuracy. In this work, we provide a detailed overview of some of the most representative deep learning based face detection methods by grouping them into a few major categories, and present their core architectural designs and accuracies on popular benchmarks. We also describe some of the most popular face detection datasets. Finally, we discuss some current challenges in the field, and suggest potential future research directions.
Age and Gender Prediction From Face Images Using Attentional Convolutional Network
Oct 08, 2020

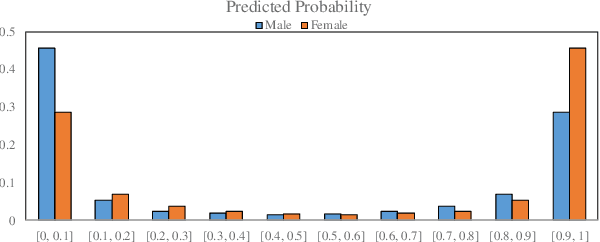

Automatic prediction of age and gender from face images has drawn a lot of attention recently, due it is wide applications in various facial analysis problems. However, due to the large intra-class variation of face images (such as variation in lighting, pose, scale, occlusion), the existing models are still behind the desired accuracy level, which is necessary for the use of these models in real-world applications. In this work, we propose a deep learning framework, based on the ensemble of attentional and residual convolutional networks, to predict gender and age group of facial images with high accuracy rate. Using attention mechanism enables our model to focus on the important and informative parts of the face, which can help it to make a more accurate prediction. We train our model in a multi-task learning fashion, and augment the feature embedding of the age classifier, with the predicted gender, and show that doing so can further increase the accuracy of age prediction. Our model is trained on a popular face age and gender dataset, and achieved promising results. Through visualization of the attention maps of the train model, we show that our model has learned to become sensitive to the right regions of the face.
Covid-Transformer: Detecting COVID-19 Trending Topics on Twitter Using Universal Sentence Encoder
Sep 19, 2020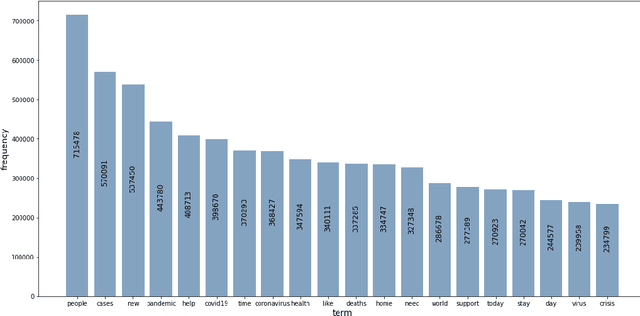
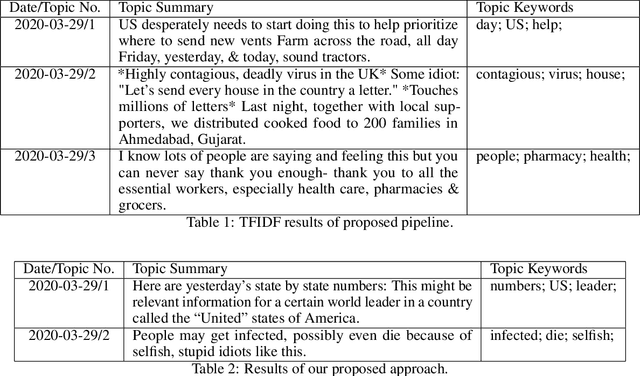

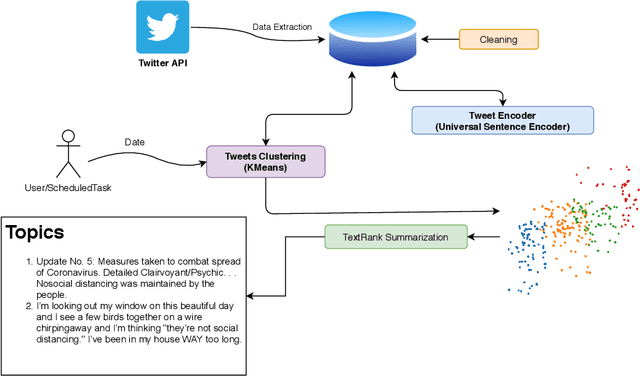
The novel corona-virus disease (also known as COVID-19) has led to a pandemic, impacting more than 200 countries across the globe. With its global impact, COVID-19 has become a major concern of people almost everywhere, and therefore there are a large number of tweets coming out from every corner of the world, about COVID-19 related topics. In this work, we try to analyze the tweets and detect the trending topics and major concerns of people on Twitter, which can enable us to better understand the situation, and devise better planning. More specifically we propose a model based on the universal sentence encoder to detect the main topics of Tweets in recent months. We used universal sentence encoder in order to derive the semantic representation and the similarity of tweets. We then used the sentence similarity and their embeddings, and feed them to K-means clustering algorithm to group similar tweets (in semantic sense). After that, the cluster summary is obtained using a text summarization algorithm based on deep learning, which can uncover the underlying topics of each cluster. Through experimental results, we show that our model can detect very informative topics, by processing a large number of tweets on sentence level (which can preserve the overall meaning of the tweets). Since this framework has no restriction on specific data distribution, it can be used to detect trending topics from any other social media and any other context rather than COVID-19. Experimental results show superiority of our proposed approach to other baselines, including TF-IDF, and latent Dirichlet allocation (LDA).
COVID CT-Net: Predicting Covid-19 From Chest CT Images Using Attentional Convolutional Network
Sep 10, 2020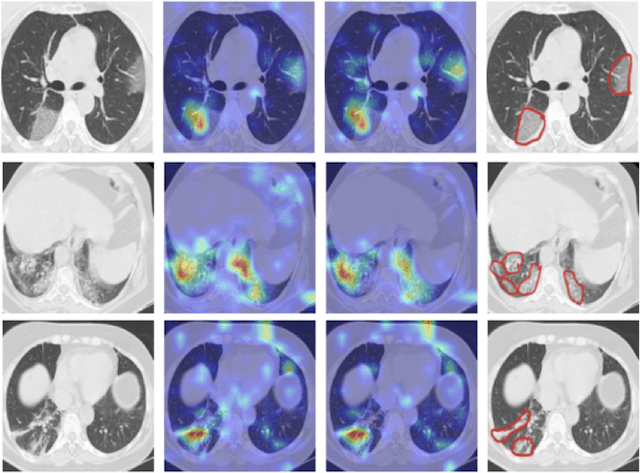
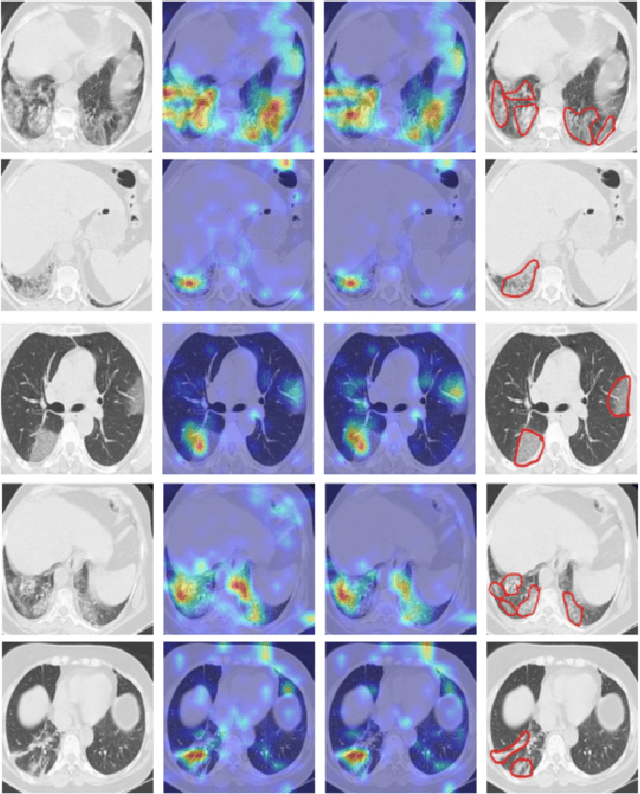
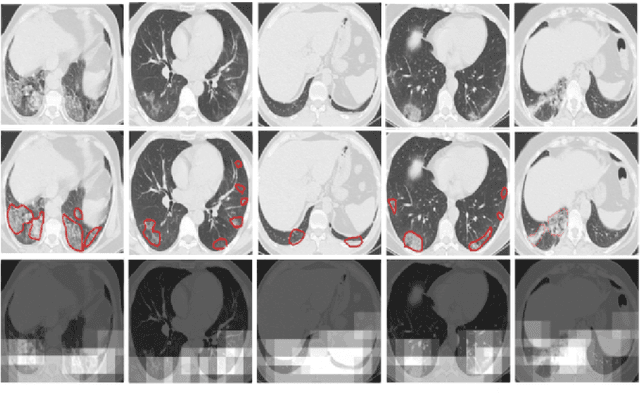
The novel corona-virus disease (COVID-19) pandemic has caused a major outbreak in more than 200 countries around the world, leading to a severe impact on the health and life of many people globally. As of Aug 25th of 2020, more than 20 million people are infected, and more than 800,000 death are reported. Computed Tomography (CT) images can be used as a as an alternative to the time-consuming "reverse transcription polymerase chain reaction (RT-PCR)" test, to detect COVID-19. In this work we developed a deep learning framework to predict COVID-19 from CT images. We propose to use an attentional convolution network, which can focus on the infected areas of chest, enabling it to perform a more accurate prediction. We trained our model on a dataset of more than 2000 CT images, and report its performance in terms of various popular metrics, such as sensitivity, specificity, area under the curve, and also precision-recall curve, and achieve very promising results. We also provide a visualization of the attention maps of the model for several test images, and show that our model is attending to the infected regions as intended. In addition to developing a machine learning modeling framework, we also provide the manual annotation of the potentionally infected regions of chest, with the help of a board-certified radiologist, and make that publicly available for other researchers.
COVID TV-UNet: Segmenting COVID-19 Chest CT Images Using Connectivity Imposed U-Net
Aug 06, 2020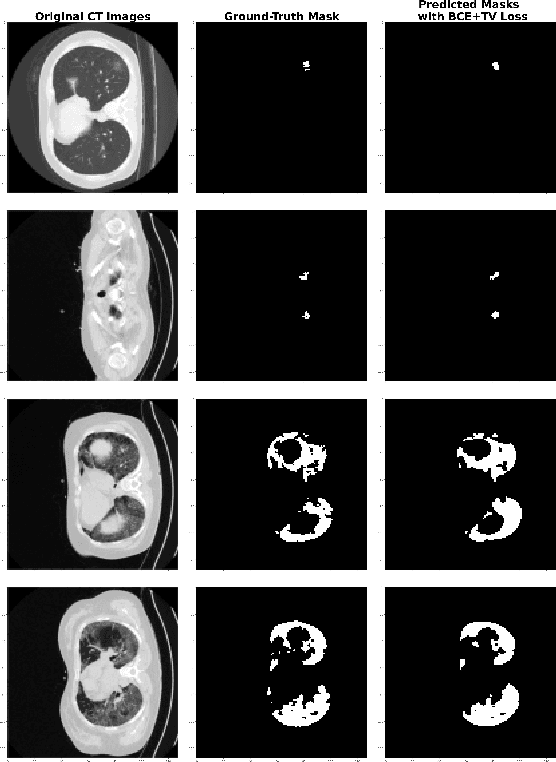
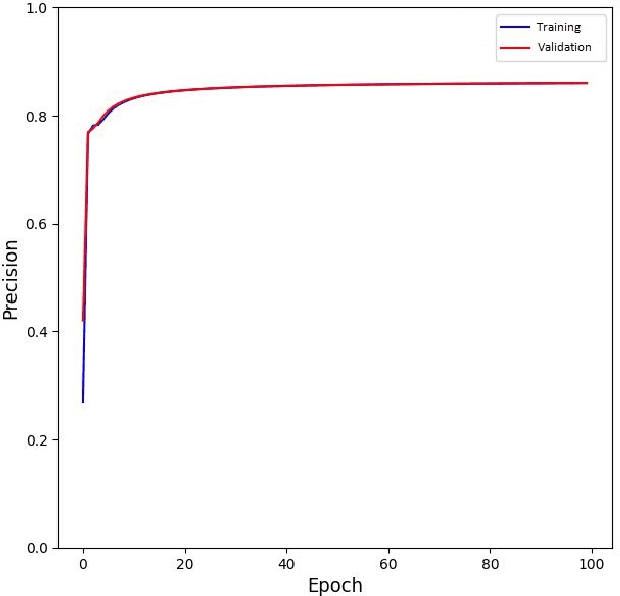
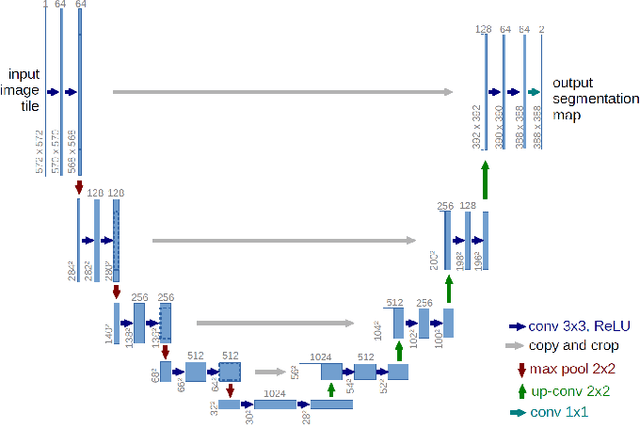
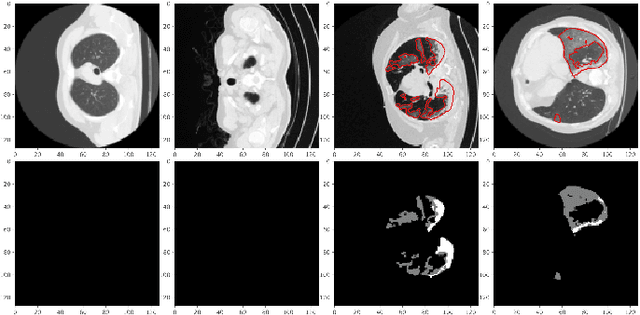
The novel corona-virus disease (COVID-19) pandemic has caused a major outbreak in more than 200 countries around the world, leading to a severe impact on the health and life of many people globally. As of mid-July 2020, more than 12 million people were infected, and more than 570,000 death were reported. Computed Tomography (CT) images can be used as an alternative to the time-consuming RT-PCR test, to detect COVID-19. In this work we propose a segmentation framework to detect chest regions in CT images, which are infected by COVID-19. We use an architecture similar to U-Net model, and train it to detect ground glass regions, on pixel level. As the infected regions tend to form a connected component (rather than randomly distributed pixels), we add a suitable regularization term to the loss function, to promote connectivity of the segmentation map for COVID-19 pixels. 2D-anisotropic total-variation is used for this purpose, and therefore the proposed model is called "TV-UNet". Through experimental results on a relatively large-scale CT segmentation dataset of around 900 images, we show that adding this new regularization term leads to 2\% gain on overall segmentation performance compared to the U-Net model. Our experimental analysis, ranging from visual evaluation of the predicted segmentation results to quantitative assessment of segmentation performance (precision, recall, Dice score, and mIoU) demonstrated great ability to identify COVID-19 associated regions of the lungs, achieving a mIoU rate of over 99\%, and a Dice score of around 86\%.
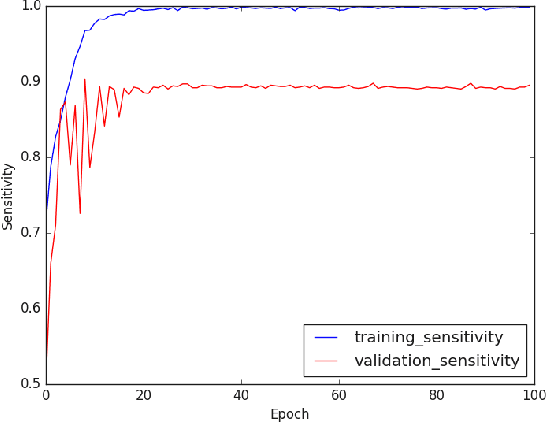
Deep-COVID: Predicting COVID-19 From Chest X-Ray Images Using Deep Transfer Learning
Apr 20, 2020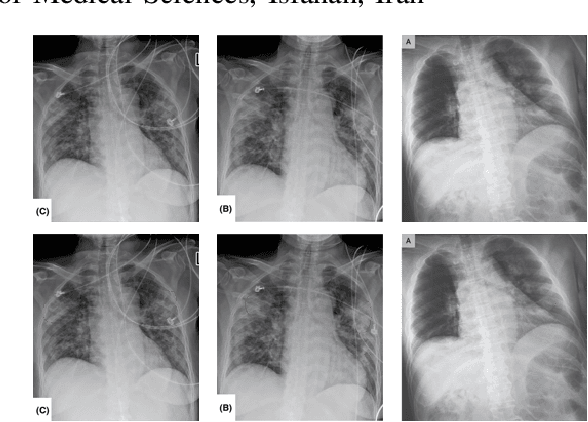
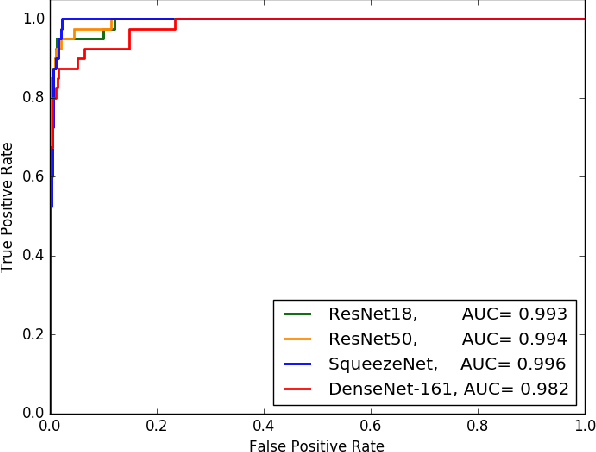
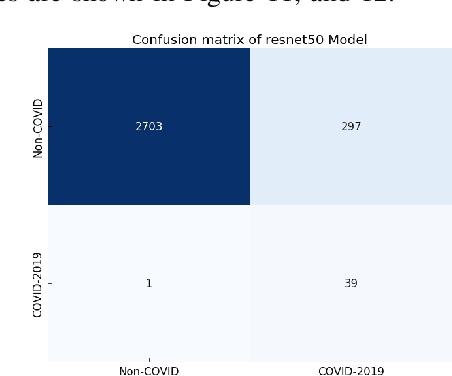
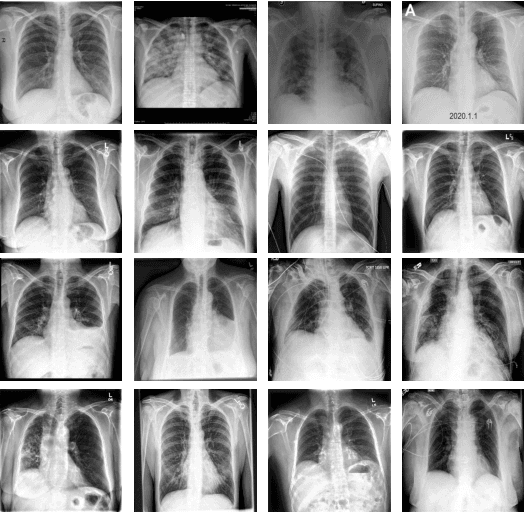
The COVID-19 pandemic is causing a major outbreak in more than 150 countries around the world, having a severe impact on the health and life of many people globally. One of the crucial step in fighting COVID-19 is the ability to detect the infected patients early enough, and put them under special care. Detecting this disease from radiography and radiology images is perhaps one of the fastest way to diagnose the patients. Some of the early studies showed specific abnormalities in the chest radiograms of patients infected with COVID-19. Inspired by earlier works, we study the application of deep learning models to detect COVID-19 patients from their chest radiography images. We first prepare a dataset of 5,000 Chest X-rays from the publicly available datasets. Images exhibiting COVID-19 disease presence were identified by board-certified radiologist. Transfer learning on a subset of 2,000 radiograms was used to train four popular convolutional neural networks, including ResNet18, ResNet50, SqueezeNet, and DenseNet-121, to identify COVID-19 disease in the analyzed chest X-ray images. We evaluated these models on the remaining 3,000 images, and most of these networks achieved a sensitivity rate of 97\%($\pm$ 5\%), while having a specificity rate of around 90\%. While the achieved performance is very encouraging, further analysis is required on a larger set of COVID-19 images, to have a more reliable estimation of accuracy rates. Besides sensitivity and specificity rates, we also present the receiver operating characteristic (ROC), area under the curve (AUC), and confusion matrix of each model. The dataset, model implementations (in PyTorch), and evaluations, are all made publicly available for research community, here: https://github.com/shervinmin/DeepCovid.git