 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTL-MAD: Multi-Task Learners are Effective Medical Anomaly Detectors
May 07, 2026Anomaly detection in medical images is a challenging task, since anomalies are not typically available during training. Recent methods leverage a single pretext task coupled with a large-scale pre-trained model to reach state-of-the-art performance. Instead, we propose to learn multiple self-supervised and pseudo-labeling tasks from scratch, using a joint model based on Mixture-of-Experts (MoE). By carefully integrating multiple proxy tasks, the joint model effectively learns a robust representation of normal anatomical structures, so that anomaly scores can be derived based on how well the multi-task learner (MTL) solves each task during inference. We perform comprehensive experiments on BMAD, a recent benchmark that comprises a broad range of medical image modalities. The empirical results indicate that our multi-task learner is an effective anomaly detector, outperforming all state-of-the-art competitors on BMAD. Moreover, our model produces interpretable anomaly maps, potentially helping physicians in providing more accurate diagnoses.
Task-Informed Anti-Curriculum by Masking Improves Downstream Performance on Text
Feb 18, 2025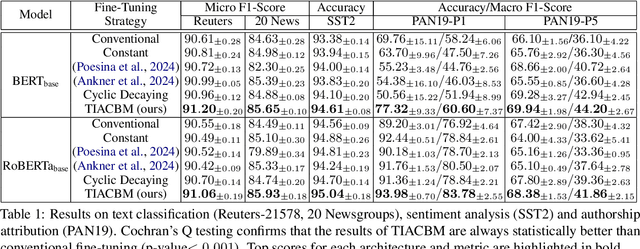


Masked language modeling has become a widely adopted unsupervised technique to pre-train language models. However, the process of selecting tokens for masking is random, and the percentage of masked tokens is typically fixed for the entire training process. In this paper, we propose to adjust the masking ratio and to decide which tokens to mask based on a novel task-informed anti-curriculum learning scheme. First, we harness task-specific knowledge about useful and harmful tokens in order to determine which tokens to mask. Second, we propose a cyclic decaying masking ratio, which corresponds to an anti-curriculum schedule (from hard to easy). We exemplify our novel task-informed anti-curriculum by masking (TIACBM) approach across three diverse downstream tasks: sentiment analysis, text classification by topic, and authorship attribution. Our findings suggest that TIACBM enhances the ability of the model to focus on key task-relevant features, contributing to statistically significant performance gains across tasks. We release our code at https://github.com/JarcaAndrei/TIACBM.
DLCR: A Generative Data Expansion Framework via Diffusion for Clothes-Changing Person Re-ID
Nov 11, 2024



With the recent exhibited strength of generative diffusion models, an open research question is \textit{if images generated by these models can be used to learn better visual representations}. While this generative data expansion may suffice for easier visual tasks, we explore its efficacy on a more difficult discriminative task: clothes-changing person re-identification (CC-ReID). CC-ReID aims to match people appearing in non-overlapping cameras, even when they change their clothes across cameras. Not only are current CC-ReID models constrained by the limited diversity of clothing in current CC-ReID datasets, but generating additional data that retains important personal features for accurate identification is a current challenge. To address this issue we propose DLCR, a novel data expansion framework that leverages pre-trained diffusion and large language models (LLMs) to accurately generate diverse images of individuals in varied attire. We generate additional data for five benchmark CC-ReID datasets (PRCC, CCVID, LaST, VC-Clothes, and LTCC) and \textbf{increase their clothing diversity by \boldmath{$10$}x, totaling over \boldmath{$2.1$}M images generated}. DLCR employs diffusion-based text-guided inpainting, conditioned on clothing prompts constructed using LLMs, to generate synthetic data that only modifies a subject's clothes while preserving their personally identifiable features. With this massive increase in data, we introduce two novel strategies - progressive learning and test-time prediction refinement - that respectively reduce training time and further boosts CC-ReID performance. On the PRCC dataset, we obtain a large top-1 accuracy improvement of $11.3\%$ by training CAL, a previous state of the art (SOTA) method, with DLCR-generated data. We publicly release our code and generated data for each dataset here: \url{https://github.com/CroitoruAlin/dlcr}.
Masked Image Modeling: A Survey
Aug 13, 2024



In this work, we survey recent studies on masked image modeling (MIM), an approach that emerged as a powerful self-supervised learning technique in computer vision. The MIM task involves masking some information, e.g. pixels, patches, or even latent representations, and training a model, usually an autoencoder, to predicting the missing information by using the context available in the visible part of the input. We identify and formalize two categories of approaches on how to implement MIM as a pretext task, one based on reconstruction and one based on contrastive learning. Then, we construct a taxonomy and review the most prominent papers in recent years. We complement the manually constructed taxonomy with a dendrogram obtained by applying a hierarchical clustering algorithm. We further identify relevant clusters via manually inspecting the resulting dendrogram. Our review also includes datasets that are commonly used in MIM research. We aggregate the performance results of various masked image modeling methods on the most popular datasets, to facilitate the comparison of competing methods. Finally, we identify research gaps and propose several interesting directions of future work.