 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Informed Anti-Curriculum by Masking Improves Downstream Performance on Text
Feb 18, 2025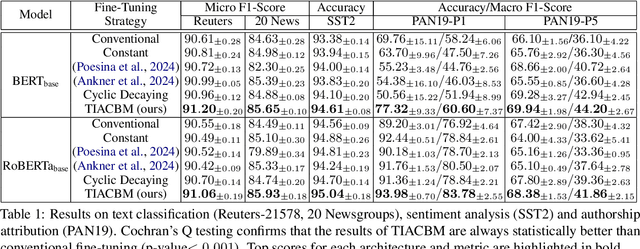


Masked language modeling has become a widely adopted unsupervised technique to pre-train language models. However, the process of selecting tokens for masking is random, and the percentage of masked tokens is typically fixed for the entire training process. In this paper, we propose to adjust the masking ratio and to decide which tokens to mask based on a novel task-informed anti-curriculum learning scheme. First, we harness task-specific knowledge about useful and harmful tokens in order to determine which tokens to mask. Second, we propose a cyclic decaying masking ratio, which corresponds to an anti-curriculum schedule (from hard to easy). We exemplify our novel task-informed anti-curriculum by masking (TIACBM) approach across three diverse downstream tasks: sentiment analysis, text classification by topic, and authorship attribution. Our findings suggest that TIACBM enhances the ability of the model to focus on key task-relevant features, contributing to statistically significant performance gains across tasks. We release our code at https://github.com/JarcaAndrei/TIACBM.
CBM: Curriculum by Masking
Jul 09, 2024



We propose Curriculum by Masking (CBM), a novel state-of-the-art curriculum learning strategy that effectively creates an easy-to-hard training schedule via patch (token) masking, offering significant accuracy improvements over the conventional training regime and previous curriculum learning (CL) methods. CBM leverages gradient magnitudes to prioritize the masking of salient image regions via a novel masking algorithm and a novel masking block. Our approach enables controlling sample difficulty via the patch masking ratio, generating an effective easy-to-hard curriculum by gradually introducing harder samples as training progresses. CBM operates with two easily configurable parameters, i.e. the number of patches and the curriculum schedule, making it a versatile curriculum learning approach for object recognition and detection. We conduct experiments with various neural architectures, ranging from convolutional networks to vision transformers, on five benchmark data sets (CIFAR-10, CIFAR-100, ImageNet, Food-101 and PASCAL VOC), to compare CBM with conventional as well as curriculum-based training regimes. Our results reveal the superiority of our strategy compared with the state-of-the-art curriculum learning regimes. We also observe improvements in transfer learning contexts, where CBM surpasses previous work by considerable margins in terms of accuracy. We release our code for free non-commercial use at https://github.com/CroitoruAlin/CBM.