 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIDiffAgent: Self-Improving Diffusion Agent
Feb 02, 2026Text-to-image diffusion models have revolutionized generative AI, enabling high-quality and photorealistic image synthesis. However, their practical deployment remains hindered by several limitations: sensitivity to prompt phrasing, ambiguity in semantic interpretation (e.g., ``mouse" as animal vs. a computer peripheral), artifacts such as distorted anatomy, and the need for carefully engineered input prompts. Existing methods often require additional training and offer limited controllability, restricting their adaptability in real-world applications. We introduce Self-Improving Diffusion Agent (SIDiffAgent), a training-free agentic framework that leverages the Qwen family of models (Qwen-VL, Qwen-Image, Qwen-Edit, Qwen-Embedding) to address these challenges. SIDiffAgent autonomously manages prompt engineering, detects and corrects poor generations, and performs fine-grained artifact removal, yielding more reliable and consistent outputs. It further incorporates iterative self-improvement by storing a memory of previous experiences in a database. This database of past experiences is then used to inject prompt-based guidance at each stage of the agentic pipeline. \modelour achieved an average VQA score of 0.884 on GenAIBench, significantly outperforming open-source, proprietary models and agentic methods. We will publicly release our code upon acceptance.
Minimizing Layerwise Activation Norm Improves Generalization in Federated Learning
Dec 09, 2025Federated Learning (FL) is an emerging machine learning framework that enables multiple clients (coordinated by a server) to collaboratively train a global model by aggregating the locally trained models without sharing any client's training data. It has been observed in recent works that learning in a federated manner may lead the aggregated global model to converge to a 'sharp minimum' thereby adversely affecting the generalizability of this FL-trained model. Therefore, in this work, we aim to improve the generalization performance of models trained in a federated setup by introducing a 'flatness' constrained FL optimization problem. This flatness constraint is imposed on the top eigenvalue of the Hessian computed from the training loss. As each client trains a model on its local data, we further re-formulate this complex problem utilizing the client loss functions and propose a new computationally efficient regularization technique, dubbed 'MAN,' which Minimizes Activation's Norm of each layer on client-side models. We also theoretically show that minimizing the activation norm reduces the top eigenvalue of the layer-wise Hessian of the client's loss, which in turn decreases the overall Hessian's top eigenvalue, ensuring convergence to a flat minimum. We apply our proposed flatness-constrained optimization to the existing FL techniques and obtain significant improvements, thereby establishing new state-of-the-art.
MGD$^3$: Mode-Guided Dataset Distillation using Diffusion Models
May 25, 2025Dataset distillation has emerged as an effective strategy, significantly reducing training costs and facilitating more efficient model deployment. Recent advances have leveraged generative models to distill datasets by capturing the underlying data distribution. Unfortunately, existing methods require model fine-tuning with distillation losses to encourage diversity and representativeness. However, these methods do not guarantee sample diversity, limiting their performance. We propose a mode-guided diffusion model leveraging a pre-trained diffusion model without the need to fine-tune with distillation losses. Our approach addresses dataset diversity in three stages: Mode Discovery to identify distinct data modes, Mode Guidance to enhance intra-class diversity, and Stop Guidance to mitigate artifacts in synthetic samples that affect performance. Our approach outperforms state-of-the-art methods, achieving accuracy gains of 4.4%, 2.9%, 1.6%, and 1.6% on ImageNette, ImageIDC, ImageNet-100, and ImageNet-1K, respectively. Our method eliminates the need for fine-tuning diffusion models with distillation losses, significantly reducing computational costs. Our code is available on the project webpage: https://jachansantiago.github.io/mode-guided-distillation/
DLCR: A Generative Data Expansion Framework via Diffusion for Clothes-Changing Person Re-ID
Nov 11, 2024



With the recent exhibited strength of generative diffusion models, an open research question is \textit{if images generated by these models can be used to learn better visual representations}. While this generative data expansion may suffice for easier visual tasks, we explore its efficacy on a more difficult discriminative task: clothes-changing person re-identification (CC-ReID). CC-ReID aims to match people appearing in non-overlapping cameras, even when they change their clothes across cameras. Not only are current CC-ReID models constrained by the limited diversity of clothing in current CC-ReID datasets, but generating additional data that retains important personal features for accurate identification is a current challenge. To address this issue we propose DLCR, a novel data expansion framework that leverages pre-trained diffusion and large language models (LLMs) to accurately generate diverse images of individuals in varied attire. We generate additional data for five benchmark CC-ReID datasets (PRCC, CCVID, LaST, VC-Clothes, and LTCC) and \textbf{increase their clothing diversity by \boldmath{$10$}x, totaling over \boldmath{$2.1$}M images generated}. DLCR employs diffusion-based text-guided inpainting, conditioned on clothing prompts constructed using LLMs, to generate synthetic data that only modifies a subject's clothes while preserving their personally identifiable features. With this massive increase in data, we introduce two novel strategies - progressive learning and test-time prediction refinement - that respectively reduce training time and further boosts CC-ReID performance. On the PRCC dataset, we obtain a large top-1 accuracy improvement of $11.3\%$ by training CAL, a previous state of the art (SOTA) method, with DLCR-generated data. We publicly release our code and generated data for each dataset here: \url{https://github.com/CroitoruAlin/dlcr}.
CityGuessr: City-Level Video Geo-Localization on a Global Scale
Nov 10, 2024



Video geolocalization is a crucial problem in current times. Given just a video, ascertaining where it was captured from can have a plethora of advantages. The problem of worldwide geolocalization has been tackled before, but only using the image modality. Its video counterpart remains relatively unexplored. Meanwhile, video geolocalization has also garnered some attention in the recent past, but the existing methods are all restricted to specific regions. This motivates us to explore the problem of video geolocalization at a global scale. Hence, we propose a novel problem of worldwide video geolocalization with the objective of hierarchically predicting the correct city, state/province, country, and continent, given a video. However, no large scale video datasets that have extensive worldwide coverage exist, to train models for solving this problem. To this end, we introduce a new dataset, CityGuessr68k comprising of 68,269 videos from 166 cities all over the world. We also propose a novel baseline approach to this problem, by designing a transformer-based architecture comprising of an elegant Self-Cross Attention module for incorporating scenes as well as a TextLabel Alignment strategy for distilling knowledge from textlabels in feature space. To further enhance our location prediction, we also utilize soft-scene labels. Finally we demonstrate the performance of our method on our new dataset as well as Mapillary(MSLS). Our code and datasets are available at: https://github.com/ParthPK/CityGuessr
GeoCLIP: Clip-Inspired Alignment between Locations and Images for Effective Worldwide Geo-localization
Sep 27, 2023



Worldwide Geo-localization aims to pinpoint the precise location of images taken anywhere on Earth. This task has considerable challenges due to immense variation in geographic landscapes. The image-to-image retrieval-based approaches fail to solve this problem on a global scale as it is not feasible to construct a large gallery of images covering the entire world. Instead, existing approaches divide the globe into discrete geographic cells, transforming the problem into a classification task. However, their performance is limited by the predefined classes and often results in inaccurate localizations when an image's location significantly deviates from its class center. To overcome these limitations, we propose GeoCLIP, a novel CLIP-inspired Image-to-GPS retrieval approach that enforces alignment between the image and its corresponding GPS locations. GeoCLIP's location encoder models the Earth as a continuous function by employing positional encoding through random Fourier features and constructing a hierarchical representation that captures information at varying resolutions to yield a semantically rich high-dimensional feature suitable to use even beyond geo-localization. To the best of our knowledge, this is the first work employing GPS encoding for geo-localization. We demonstrate the efficacy of our method via extensive experiments and ablations on benchmark datasets. We achieve competitive performance with just 20% of training data, highlighting its effectiveness even in limited-data settings. Furthermore, we qualitatively demonstrate geo-localization using a text query by leveraging CLIP backbone of our image encoder.
DAD++: Improved Data-free Test Time Adversarial Defense
Sep 10, 2023With the increasing deployment of deep neural networks in safety-critical applications such as self-driving cars, medical imaging, anomaly detection, etc., adversarial robustness has become a crucial concern in the reliability of these networks in real-world scenarios. A plethora of works based on adversarial training and regularization-based techniques have been proposed to make these deep networks robust against adversarial attacks. However, these methods require either retraining models or training them from scratch, making them infeasible to defend pre-trained models when access to training data is restricted. To address this problem, we propose a test time Data-free Adversarial Defense (DAD) containing detection and correction frameworks. Moreover, to further improve the efficacy of the correction framework in cases when the detector is under-confident, we propose a soft-detection scheme (dubbed as "DAD++"). We conduct a wide range of experiments and ablations on several datasets and network architectures to show the efficacy of our proposed approach. Furthermore, we demonstrate the applicability of our approach in imparting adversarial defense at test time under data-free (or data-efficient) applications/setups, such as Data-free Knowledge Distillation and Source-free Unsupervised Domain Adaptation, as well as Semi-supervised classification frameworks. We observe that in all the experiments and applications, our DAD++ gives an impressive performance against various adversarial attacks with a minimal drop in clean accuracy. The source code is available at: https://github.com/vcl-iisc/Improved-Data-free-Test-Time-Adversarial-Defense
DISBELIEVE: Distance Between Client Models is Very Essential for Effective Local Model Poisoning Attacks
Aug 14, 2023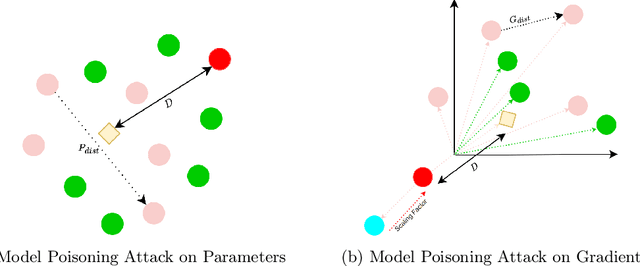



Federated learning is a promising direction to tackle the privacy issues related to sharing patients' sensitive data. Often, federated systems in the medical image analysis domain assume that the participating local clients are \textit{honest}. Several studies report mechanisms through which a set of malicious clients can be introduced that can poison the federated setup, hampering the performance of the global model. To overcome this, robust aggregation methods have been proposed that defend against those attacks. We observe that most of the state-of-the-art robust aggregation methods are heavily dependent on the distance between the parameters or gradients of malicious clients and benign clients, which makes them prone to local model poisoning attacks when the parameters or gradients of malicious and benign clients are close. Leveraging this, we introduce DISBELIEVE, a local model poisoning attack that creates malicious parameters or gradients such that their distance to benign clients' parameters or gradients is low respectively but at the same time their adverse effect on the global model's performance is high. Experiments on three publicly available medical image datasets demonstrate the efficacy of the proposed DISBELIEVE attack as it significantly lowers the performance of the state-of-the-art \textit{robust aggregation} methods for medical image analysis. Furthermore, compared to state-of-the-art local model poisoning attacks, DISBELIEVE attack is also effective on natural images where we observe a severe drop in classification performance of the global model for multi-class classification on benchmark dataset CIFAR-10.
Query Efficient Cross-Dataset Transferable Black-Box Attack on Action Recognition
Nov 23, 2022Black-box adversarial attacks present a realistic threat to action recognition systems. Existing black-box attacks follow either a query-based approach where an attack is optimized by querying the target model, or a transfer-based approach where attacks are generated using a substitute model. While these methods can achieve decent fooling rates, the former tends to be highly query-inefficient while the latter assumes extensive knowledge of the black-box model's training data. In this paper, we propose a new attack on action recognition that addresses these shortcomings by generating perturbations to disrupt the features learned by a pre-trained substitute model to reduce the number of queries. By using a nearly disjoint dataset to train the substitute model, our method removes the requirement that the substitute model be trained using the same dataset as the target model, and leverages queries to the target model to retain the fooling rate benefits provided by query-based methods. This ultimately results in attacks which are more transferable than conventional black-box attacks. Through extensive experiments, we demonstrate highly query-efficient black-box attacks with the proposed framework. Our method achieves 8% and 12% higher deception rates compared to state-of-the-art query-based and transfer-based attacks, respectively.
Data-free Defense of Black Box Models Against Adversarial Attacks
Nov 03, 2022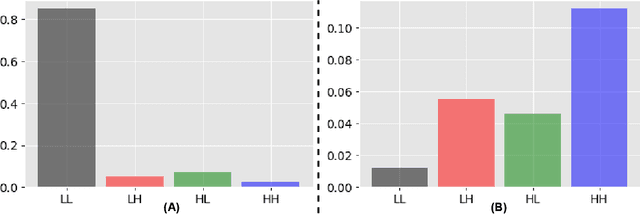


Several companies often safeguard their trained deep models (i.e. details of architecture, learnt weights, training details etc.) from third-party users by exposing them only as black boxes through APIs. Moreover, they may not even provide access to the training data due to proprietary reasons or sensitivity concerns. We make the first attempt to provide adversarial robustness to the black box models in a data-free set up. We construct synthetic data via generative model and train surrogate network using model stealing techniques. To minimize adversarial contamination on perturbed samples, we propose `wavelet noise remover' (WNR) that performs discrete wavelet decomposition on input images and carefully select only a few important coefficients determined by our `wavelet coefficient selection module' (WCSM). To recover the high-frequency content of the image after noise removal via WNR, we further train a `regenerator' network with an objective to retrieve the coefficients such that the reconstructed image yields similar to original predictions on the surrogate model. At test time, WNR combined with trained regenerator network is prepended to the black box network, resulting in a high boost in adversarial accuracy. Our method improves the adversarial accuracy on CIFAR-10 by 38.98% and 32.01% on state-of-the-art Auto Attack compared to baseline, even when the attacker uses surrogate architecture (Alexnet-half and Alexnet) similar to the black box architecture (Alexnet) with same model stealing strategy as defender. The code is available at https://github.com/vcl-iisc/data-free-black-box-defense