 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Telephone Game: Evaluating Semantic Drift in Unified Models
Sep 04, 2025Employing a single, unified model (UM) for both visual understanding (image-to-text: I2T) and and visual generation (text-to-image: T2I) has opened a new direction in Visual Language Model (VLM) research. While UMs can also support broader unimodal tasks (e.g., text-to-text, image-to-image), we focus on the core cross-modal pair T2I and I2T, as consistency between understanding and generation is critical for downstream use. Existing evaluations consider these capabilities in isolation: FID and GenEval for T2I, and benchmarks such as MME, MMBench for I2T. These single-pass metrics do not reveal whether a model that understands a concept can also render it, nor whether meaning is preserved when cycling between image and text modalities. To address this, we introduce the Unified Consistency Framework for Unified Models (UCF-UM), a cyclic evaluation protocol that alternates I2T and T2I over multiple generations to quantify semantic drift. UCF formulates 3 metrics: (i) Mean Cumulative Drift (MCD), an embedding-based measure of overall semantic loss; (ii) Semantic Drift Rate (SDR), that summarizes semantic decay rate; and (iii) Multi-Generation GenEval (MGG), an object-level compliance score extending GenEval. To assess generalization beyond COCO, which is widely used in training; we create a new benchmark ND400, sampled from NoCaps and DOCCI and evaluate on seven recent models. UCF-UM reveals substantial variation in cross-modal stability: some models like BAGEL maintain semantics over many alternations, whereas others like Vila-u drift quickly despite strong single-pass scores. Our results highlight cyclic consistency as a necessary complement to standard I2T and T2I evaluations, and provide practical metrics to consistently assess unified model's cross-modal stability and strength of their shared representations. Code: https://github.com/mollahsabbir/Semantic-Drift-in-Unified-Models
From Bias to Accountability: How the EU AI Act Confronts Challenges in European GeoAI Auditing
May 23, 2025Bias in geospatial artificial intelligence (GeoAI) models has been documented, yet the evidence is scattered across narrowly focused studies. We synthesize this fragmented literature to provide a concise overview of bias in GeoAI and examine how the EU's Artificial Intelligence Act (EU AI Act) shapes audit obligations. We discuss recurring bias mechanisms, including representation, algorithmic and aggregation bias, and map them to specific provisions of the EU AI Act. By applying the Act's high-risk criteria, we demonstrate that widely deployed GeoAI applications qualify as high-risk systems. We then present examples of recent audits along with an outline of practical methods for detecting bias. As far as we know, this study represents the first integration of GeoAI bias evidence into the EU AI Act context, by identifying high-risk GeoAI systems and mapping bias mechanisms to the Act's Articles. Although the analysis is exploratory, it suggests that even well-curated European datasets should employ routine bias audits before 2027, when the AI Act's high-risk provisions take full effect.
GAEA: A Geolocation Aware Conversational Model
Mar 20, 2025



Image geolocalization, in which, traditionally, an AI model predicts the precise GPS coordinates of an image is a challenging task with many downstream applications. However, the user cannot utilize the model to further their knowledge other than the GPS coordinate; the model lacks an understanding of the location and the conversational ability to communicate with the user. In recent days, with tremendous progress of large multimodal models (LMMs) proprietary and open-source researchers have attempted to geolocalize images via LMMs. However, the issues remain unaddressed; beyond general tasks, for more specialized downstream tasks, one of which is geolocalization, LMMs struggle. In this work, we propose to solve this problem by introducing a conversational model GAEA that can provide information regarding the location of an image, as required by a user. No large-scale dataset enabling the training of such a model exists. Thus we propose a comprehensive dataset GAEA with 800K images and around 1.6M question answer pairs constructed by leveraging OpenStreetMap (OSM) attributes and geographical context clues. For quantitative evaluation, we propose a diverse benchmark comprising 4K image-text pairs to evaluate conversational capabilities equipped with diverse question types. We consider 11 state-of-the-art open-source and proprietary LMMs and demonstrate that GAEA significantly outperforms the best open-source model, LLaVA-OneVision by 25.69% and the best proprietary model, GPT-4o by 8.28%. Our dataset, model and codes are available
NuPlanQA: A Large-Scale Dataset and Benchmark for Multi-View Driving Scene Understanding in Multi-Modal Large Language Models
Mar 17, 2025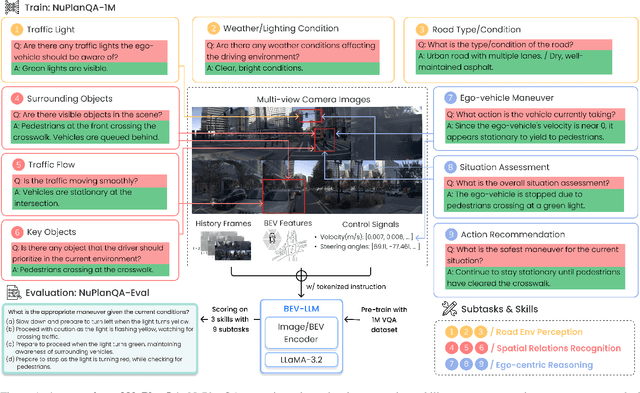
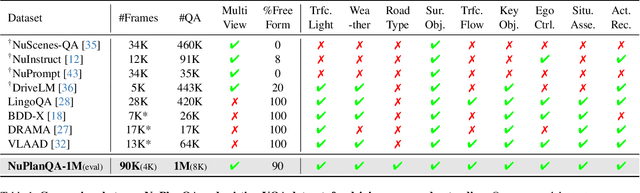
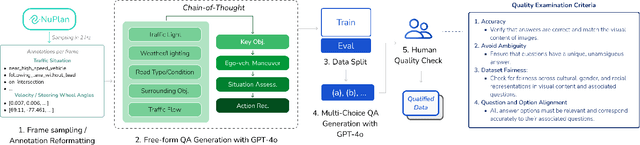
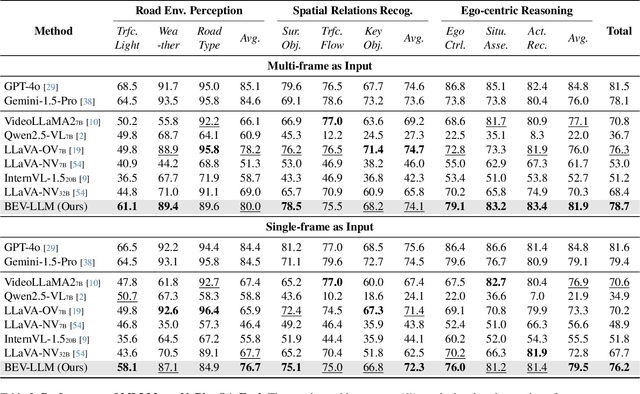
Recent advances in multi-modal large language models (MLLMs) have demonstrated strong performance across various domains; however, their ability to comprehend driving scenes remains less proven. The complexity of driving scenarios, which includes multi-view information, poses significant challenges for existing MLLMs. In this paper, we introduce NuPlanQA-Eval, a multi-view, multi-modal evaluation benchmark for driving scene understanding. To further support generalization to multi-view driving scenarios, we also propose NuPlanQA-1M, a large-scale dataset comprising 1M real-world visual question-answering (VQA) pairs. For context-aware analysis of traffic scenes, we categorize our dataset into nine subtasks across three core skills: Road Environment Perception, Spatial Relations Recognition, and Ego-Centric Reasoning. Furthermore, we present BEV-LLM, integrating Bird's-Eye-View (BEV) features from multi-view images into MLLMs. Our evaluation results reveal key challenges that existing MLLMs face in driving scene-specific perception and spatial reasoning from ego-centric perspectives. In contrast, BEV-LLM demonstrates remarkable adaptability to this domain, outperforming other models in six of the nine subtasks. These findings highlight how BEV integration enhances multi-view MLLMs while also identifying key areas that require further refinement for effective adaptation to driving scenes. To facilitate further research, we publicly release NuPlanQA at https://github.com/sungyeonparkk/NuPlanQA.
PDB: Not All Drivers Are the Same -- A Personalized Dataset for Understanding Driving Behavior
Mar 09, 2025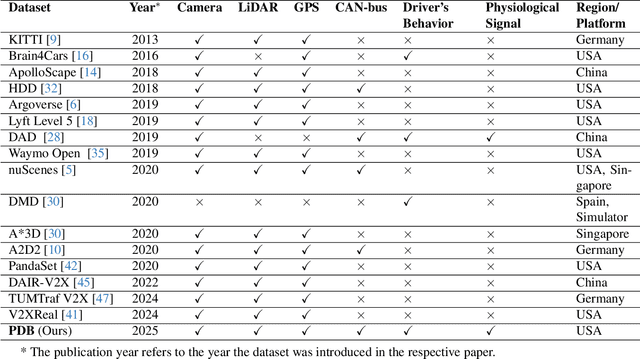
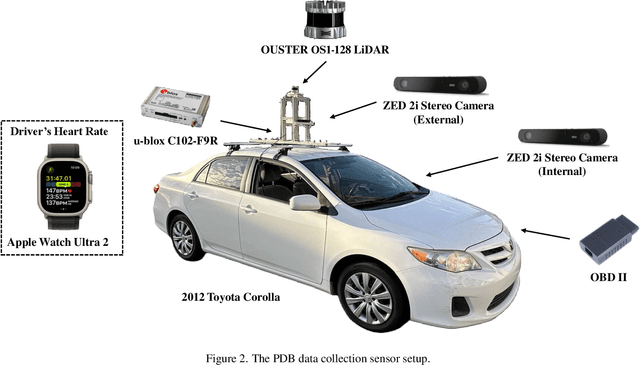
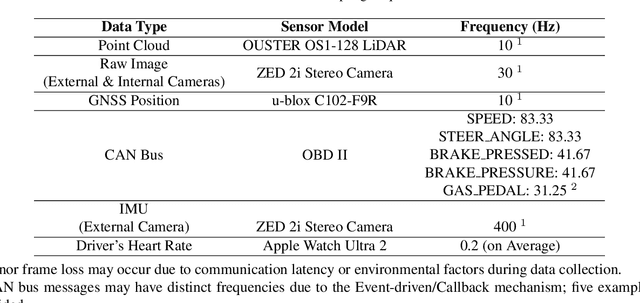
Driving behavior is inherently personal, influenced by individual habits, decision-making styles, and physiological states. However, most existing datasets treat all drivers as homogeneous, overlooking driver-specific variability. To address this gap, we introduce the Personalized Driving Behavior (PDB) dataset, a multi-modal dataset designed to capture personalization in driving behavior under naturalistic driving conditions. Unlike conventional datasets, PDB minimizes external influences by maintaining consistent routes, vehicles, and lighting conditions across sessions. It includes sources from 128-line LiDAR, front-facing camera video, GNSS, 9-axis IMU, CAN bus data (throttle, brake, steering angle), and driver-specific signals such as facial video and heart rate. The dataset features 12 participants, approximately 270,000 LiDAR frames, 1.6 million images, and 6.6 TB of raw sensor data. The processed trajectory dataset consists of 1,669 segments, each spanning 10 seconds with a 0.2-second interval. By explicitly capturing drivers' behavior, PDB serves as a unique resource for human factor analysis, driver identification, and personalized mobility applications, contributing to the development of human-centric intelligent transportation systems.
SB-Bench: Stereotype Bias Benchmark for Large Multimodal Models
Feb 12, 2025



Stereotype biases in Large Multimodal Models (LMMs) perpetuate harmful societal prejudices, undermining the fairness and equity of AI applications. As LMMs grow increasingly influential, addressing and mitigating inherent biases related to stereotypes, harmful generations, and ambiguous assumptions in real-world scenarios has become essential. However, existing datasets evaluating stereotype biases in LMMs often lack diversity and rely on synthetic images, leaving a gap in bias evaluation for real-world visual contexts. To address this, we introduce the Stereotype Bias Benchmark (SB-bench), the most comprehensive framework to date for assessing stereotype biases across nine diverse categories with non-synthetic images. SB-bench rigorously evaluates LMMs through carefully curated, visually grounded scenarios, challenging them to reason accurately about visual stereotypes. It offers a robust evaluation framework featuring real-world visual samples, image variations, and multiple-choice question formats. By introducing visually grounded queries that isolate visual biases from textual ones, SB-bench enables a precise and nuanced assessment of a model's reasoning capabilities across varying levels of difficulty. Through rigorous testing of state-of-the-art open-source and closed-source LMMs, SB-bench provides a systematic approach to assessing stereotype biases in LMMs across key social dimensions. This benchmark represents a significant step toward fostering fairness in AI systems and reducing harmful biases, laying the groundwork for more equitable and socially responsible LMMs. Our code and dataset are publicly available.
All Languages Matter: Evaluating LMMs on Culturally Diverse 100 Languages
Nov 25, 2024



Existing Large Multimodal Models (LMMs) generally focus on only a few regions and languages. As LMMs continue to improve, it is increasingly important to ensure they understand cultural contexts, respect local sensitivities, and support low-resource languages, all while effectively integrating corresponding visual cues. In pursuit of culturally diverse global multimodal models, our proposed All Languages Matter Benchmark (ALM-bench) represents the largest and most comprehensive effort to date for evaluating LMMs across 100 languages. ALM-bench challenges existing models by testing their ability to understand and reason about culturally diverse images paired with text in various languages, including many low-resource languages traditionally underrepresented in LMM research. The benchmark offers a robust and nuanced evaluation framework featuring various question formats, including true/false, multiple choice, and open-ended questions, which are further divided into short and long-answer categories. ALM-bench design ensures a comprehensive assessment of a model's ability to handle varied levels of difficulty in visual and linguistic reasoning. To capture the rich tapestry of global cultures, ALM-bench carefully curates content from 13 distinct cultural aspects, ranging from traditions and rituals to famous personalities and celebrations. Through this, ALM-bench not only provides a rigorous testing ground for state-of-the-art open and closed-source LMMs but also highlights the importance of cultural and linguistic inclusivity, encouraging the development of models that can serve diverse global populations effectively. Our benchmark is publicly available.
Video Token Sparsification for Efficient Multimodal LLMs in Autonomous Driving
Sep 16, 2024



Multimodal large language models (MLLMs) have demonstrated remarkable potential for enhancing scene understanding in autonomous driving systems through powerful logical reasoning capabilities. However, the deployment of these models faces significant challenges due to their substantial parameter sizes and computational demands, which often exceed the constraints of onboard computation. One major limitation arises from the large number of visual tokens required to capture fine-grained and long-context visual information, leading to increased latency and memory consumption. To address this issue, we propose Video Token Sparsification (VTS), a novel approach that leverages the inherent redundancy in consecutive video frames to significantly reduce the total number of visual tokens while preserving the most salient information. VTS employs a lightweight CNN-based proposal model to adaptively identify key frames and prune less informative tokens, effectively mitigating hallucinations and increasing inference throughput without compromising performance. We conduct comprehensive experiments on the DRAMA and LingoQA benchmarks, demonstrating the effectiveness of VTS in achieving up to a 33\% improvement in inference throughput and a 28\% reduction in memory usage compared to the baseline without compromising performance.
Open Vocabulary Multi-Label Video Classification
Jul 12, 2024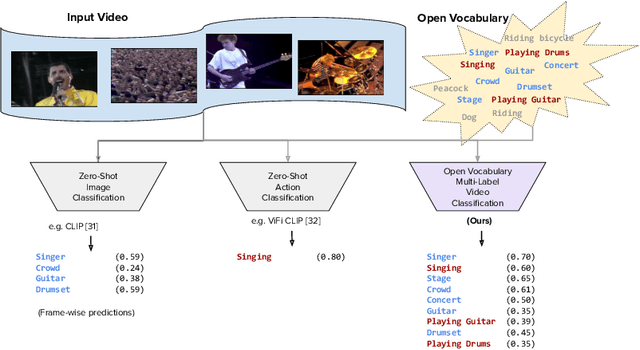
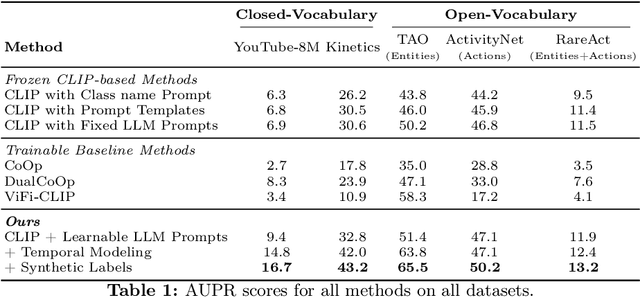
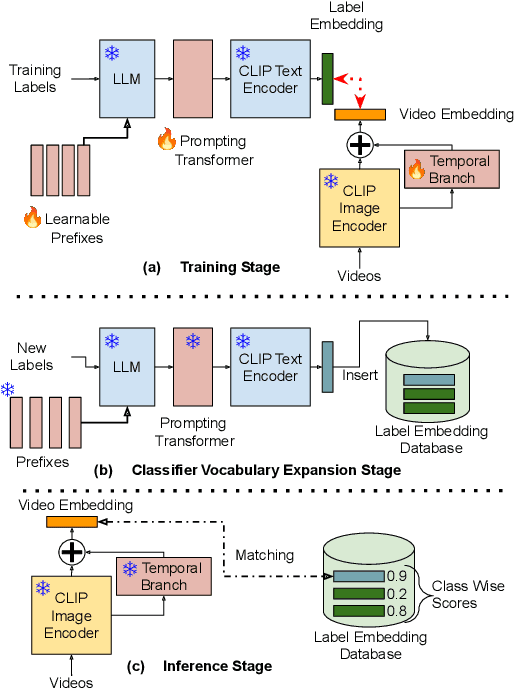
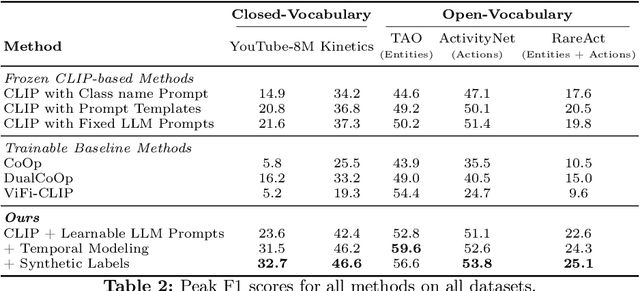
Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
Investigating Personalized Driving Behaviors in Dilemma Zones: Analysis and Prediction of Stop-or-Go Decisions
May 06, 2024Dilemma zones at signalized intersections present a commonly occurring but unsolved challenge for both drivers and traffic operators. Onsets of the yellow lights prompt varied responses from different drivers: some may brake abruptly, compromising the ride comfort, while others may accelerate, increasing the risk of red-light violations and potential safety hazards. Such diversity in drivers' stop-or-go decisions may result from not only surrounding traffic conditions, but also personalized driving behaviors. To this end, identifying personalized driving behaviors and integrating them into advanced driver assistance systems (ADAS) to mitigate the dilemma zone problem presents an intriguing scientific question. In this study, we employ a game engine-based (i.e., CARLA-enabled) driving simulator to collect high-resolution vehicle trajectories, incoming traffic signal phase and timing information, and stop-or-go decisions from four subject drivers in various scenarios. This approach allows us to analyze personalized driving behaviors in dilemma zones and develop a Personalized Transformer Encoder to predict individual drivers' stop-or-go decisions. The results show that the Personalized Transformer Encoder improves the accuracy of predicting driver decision-making in the dilemma zone by 3.7% to 12.6% compared to the Generic Transformer Encoder, and by 16.8% to 21.6% over the binary logistic regression model.