 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLLM: A Large Language Model for Composed Image Retrieval
Mar 25, 2025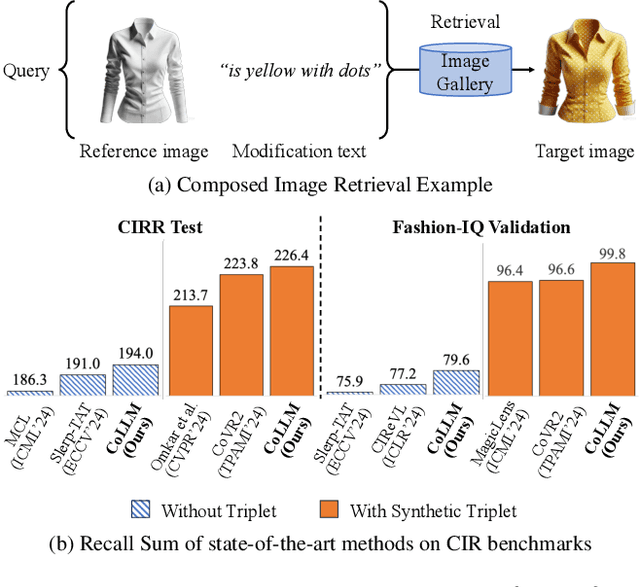
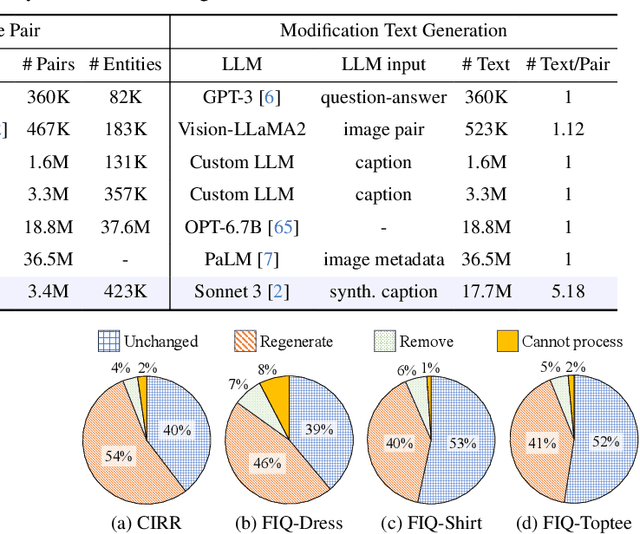
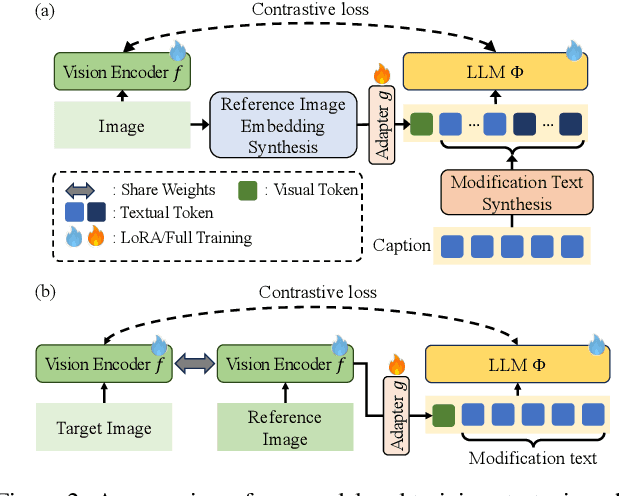
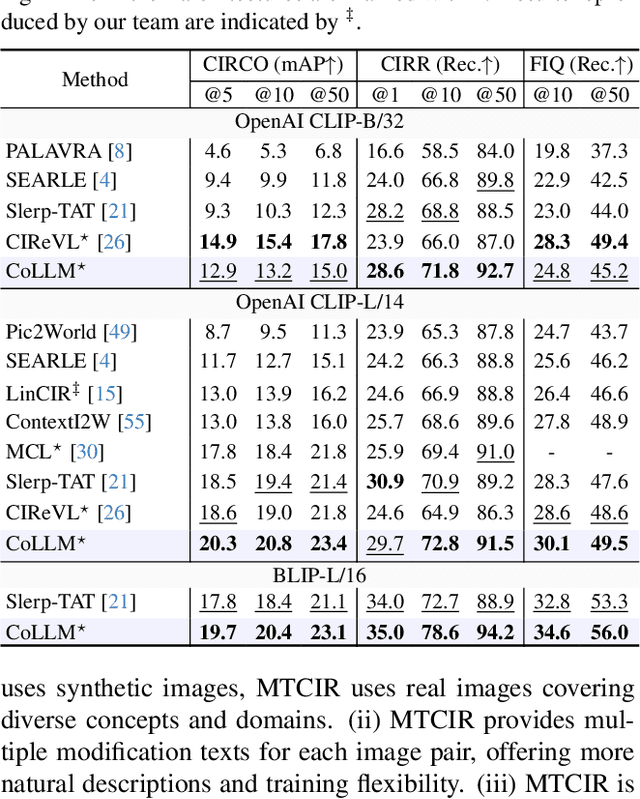
Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language models (VLMs) with ubiquitous web-crawled image-caption pairs. However, these methods have significant limitations: synthetic triplets suffer from limited scale, lack of diversity, and unnatural modification text, while image-caption pairs hinder joint embedding learning of the multimodal query due to the absence of triplet data. Moreover, existing approaches struggle with complex and nuanced modification texts that demand sophisticated fusion and understanding of vision and language modalities. We present CoLLM, a one-stop framework that effectively addresses these limitations. Our approach generates triplets on-the-fly from image-caption pairs, enabling supervised training without manual annotation. We leverage Large Language Models (LLMs) to generate joint embeddings of reference images and modification texts, facilitating deeper multimodal fusion. Additionally, we introduce Multi-Text CIR (MTCIR), a large-scale dataset comprising 3.4M samples, and refine existing CIR benchmarks (CIRR and Fashion-IQ) to enhance evaluation reliability. Experimental results demonstrate that CoLLM achieves state-of-the-art performance across multiple CIR benchmarks and settings. MTCIR yields competitive results, with up to 15% performance improvement. Our refined benchmarks provide more reliable evaluation metrics for CIR models, contributing to the advancement of this important field.
Open Vocabulary Multi-Label Video Classification
Jul 12, 2024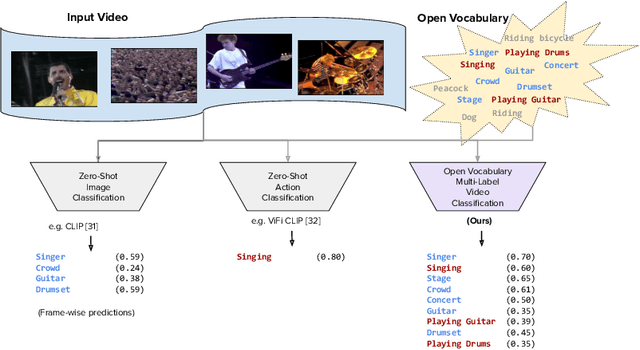
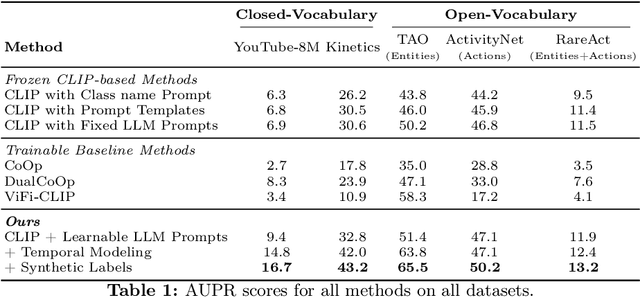
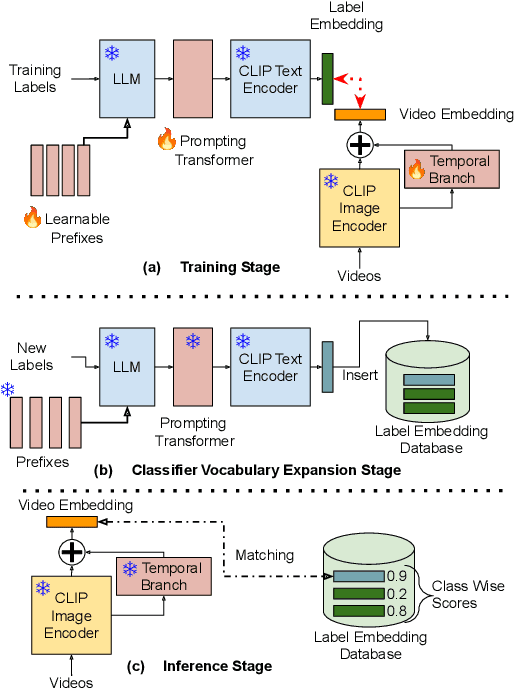
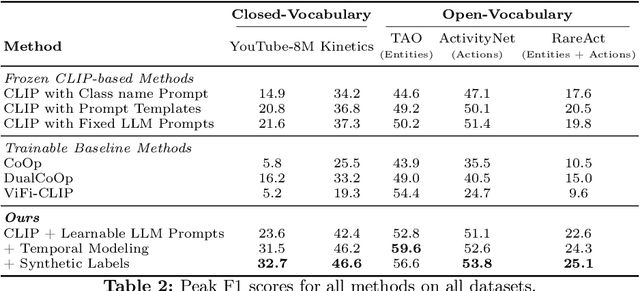
Pre-trained vision-language models (VLMs) have enabled significant progress in open vocabulary computer vision tasks such as image classification, object detection and image segmentation. Some recent works have focused on extending VLMs to open vocabulary single label action classification in videos. However, previous methods fall short in holistic video understanding which requires the ability to simultaneously recognize multiple actions and entities e.g., objects in the video in an open vocabulary setting. We formulate this problem as open vocabulary multilabel video classification and propose a method to adapt a pre-trained VLM such as CLIP to solve this task. We leverage large language models (LLMs) to provide semantic guidance to the VLM about class labels to improve its open vocabulary performance with two key contributions. First, we propose an end-to-end trainable architecture that learns to prompt an LLM to generate soft attributes for the CLIP text-encoder to enable it to recognize novel classes. Second, we integrate a temporal modeling module into CLIP's vision encoder to effectively model the spatio-temporal dynamics of video concepts as well as propose a novel regularized finetuning technique to ensure strong open vocabulary classification performance in the video domain. Our extensive experimentation showcases the efficacy of our approach on multiple benchmark datasets.
Interaction Graphs for Object Importance Estimation in On-road Driving Videos
Mar 12, 2020
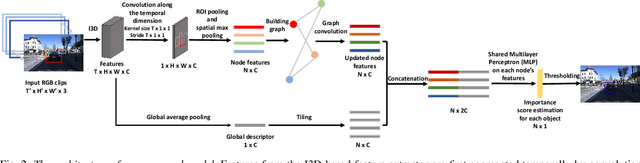


A vehicle driving along the road is surrounded by many objects, but only a small subset of them influence the driver's decisions and actions. Learning to estimate the importance of each object on the driver's real-time decision-making may help better understand human driving behavior and lead to more reliable autonomous driving systems. Solving this problem requires models that understand the interactions between the ego-vehicle and the surrounding objects. However, interactions among other objects in the scene can potentially also be very helpful, e.g., a pedestrian beginning to cross the road between the ego-vehicle and the car in front will make the car in front less important. We propose a novel framework for object importance estimation using an interaction graph, in which the features of each object node are updated by interacting with others through graph convolution. Experiments show that our model outperforms state-of-the-art baselines with much less input and pre-processing.
Grounding Human-to-Vehicle Advice for Self-driving Vehicles
Nov 16, 2019

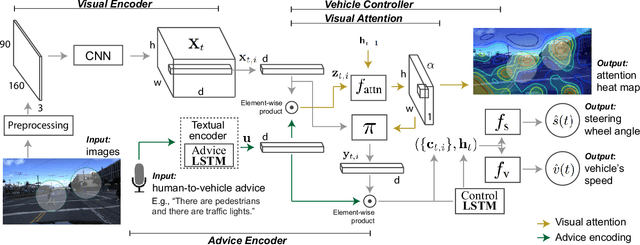
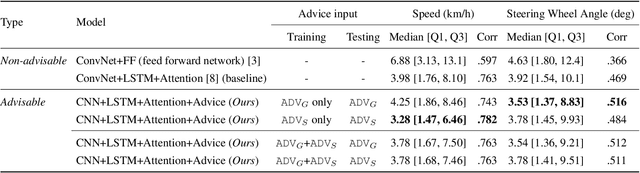
Recent success suggests that deep neural control networks are likely to be a key component of self-driving vehicles. These networks are trained on large datasets to imitate human actions, but they lack semantic understanding of image contents. This makes them brittle and potentially unsafe in situations that do not match training data. Here, we propose to address this issue by augmenting training data with natural language advice from a human. Advice includes guidance about what to do and where to attend. We present the first step toward advice giving, where we train an end-to-end vehicle controller that accepts advice. The controller adapts the way it attends to the scene (visual attention) and the control (steering and speed). Attention mechanisms tie controller behavior to salient objects in the advice. We evaluate our model on a novel advisable driving dataset with manually annotated human-to-vehicle advice called Honda Research Institute-Advice Dataset (HAD). We show that taking advice improves the performance of the end-to-end network, while the network cues on a variety of visual features that are provided by advice. The dataset is available at https://usa.honda-ri.com/HAD.
Context Aware Road-user Importance Estimation (iCARE)
Aug 30, 2019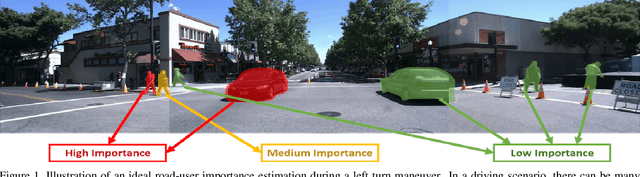
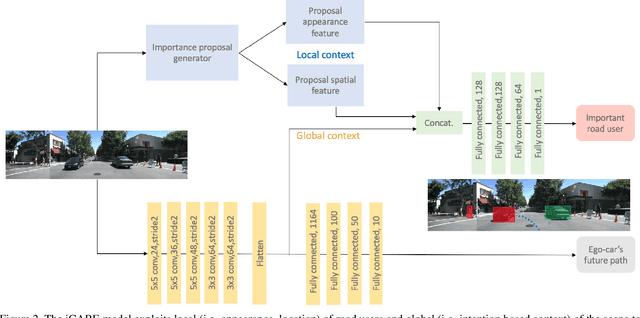

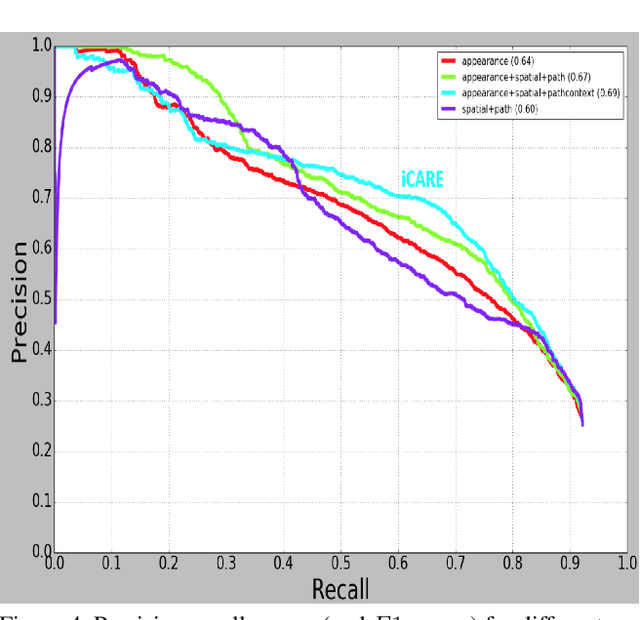
Road-users are a critical part of decision-making for both self-driving cars and driver assistance systems. Some road-users, however, are more important for decision-making than others because of their respective intentions, ego vehicle's intention and their effects on each other. In this paper, we propose a novel architecture for road-user importance estimation which takes advantage of the local and global context of the scene. For local context, the model exploits the appearance of the road users (which captures orientation, intention, etc.) and their location relative to ego-vehicle. The global context in our model is defined based on the feature map of the convolutional layer of the module which predicts the future path of the ego-vehicle and contains rich global information of the scene (e.g., infrastructure, road lanes, etc.), as well as the ego vehicle's intention information. Moreover, this paper introduces a new data set of real-world driving, concentrated around inter-sections and includes annotations of important road users. Systematic evaluations of our proposed method against several baselines show promising results.
Goal-oriented Object Importance Estimation in On-road Driving Videos
May 08, 2019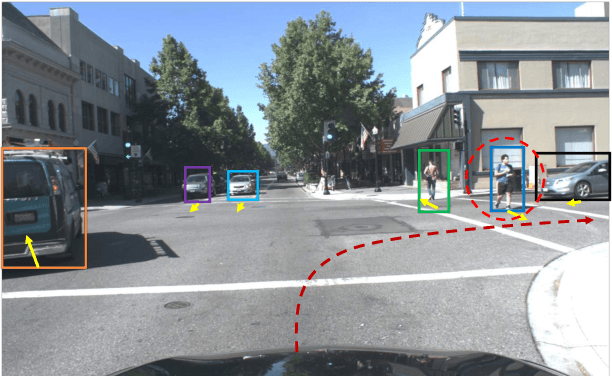
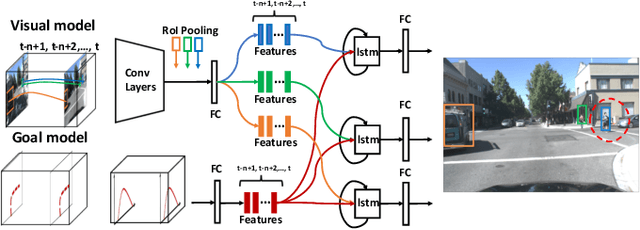
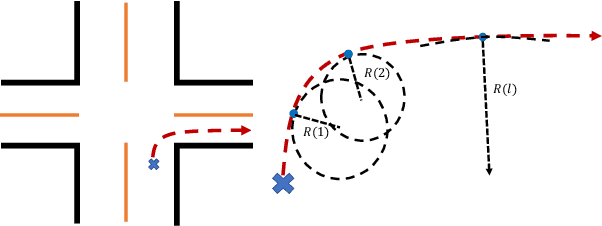
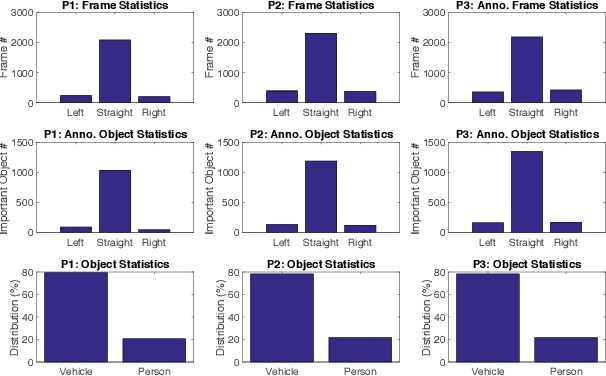
We formulate a new problem as Object Importance Estimation (OIE) in on-road driving videos, where the road users are considered as important objects if they have influence on the control decision of the ego-vehicle's driver. The importance of a road user depends on both its visual dynamics, e.g., appearance, motion and location, in the driving scene and the driving goal, \emph{e.g}., the planned path, of the ego vehicle. We propose a novel framework that incorporates both visual model and goal representation to conduct OIE. To evaluate our framework, we collect an on-road driving dataset at traffic intersections in the real world and conduct human-labeled annotation of the important objects. Experimental results show that our goal-oriented method outperforms baselines and has much more improvement on the left-turn and right-turn scenarios. Furthermore, we explore the possibility of using object importance for driving control prediction and demonstrate that binary brake prediction can be improved with the information of object importance.