 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocBed: A Multi-Stage OCR Solution for Documents with Complex Layouts
Feb 03, 2022


Digitization of newspapers is of interest for many reasons including preservation of history, accessibility and search ability, etc. While digitization of documents such as scientific articles and magazines is prevalent in literature, one of the main challenges for digitization of newspaper lies in its complex layout (e.g. articles spanning multiple columns, text interrupted by images) analysis, which is necessary to preserve human read-order. This work provides a major breakthrough in the digitization of newspapers on three fronts: first, releasing a dataset of 3000 fully-annotated, real-world newspaper images from 21 different U.S. states representing an extensive variety of complex layouts for document layout analysis; second, proposing layout segmentation as a precursor to existing optical character recognition (OCR) engines, where multiple state-of-the-art image segmentation models and several post-processing methods are explored for document layout segmentation; third, providing a thorough and structured evaluation protocol for isolated layout segmentation and end-to-end OCR.
Grounded Relational Inference: Domain Knowledge Driven Explainable Autonomous Driving
Feb 23, 2021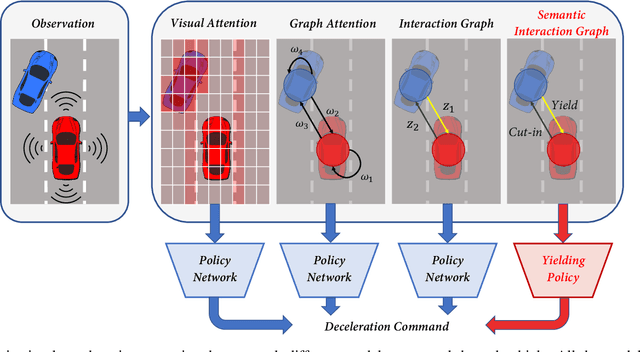

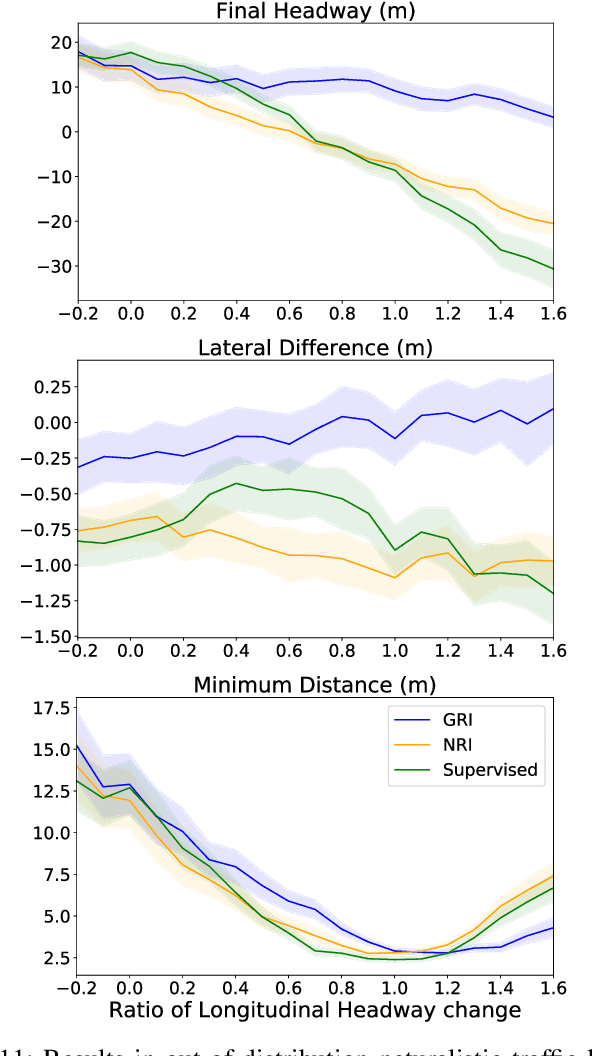
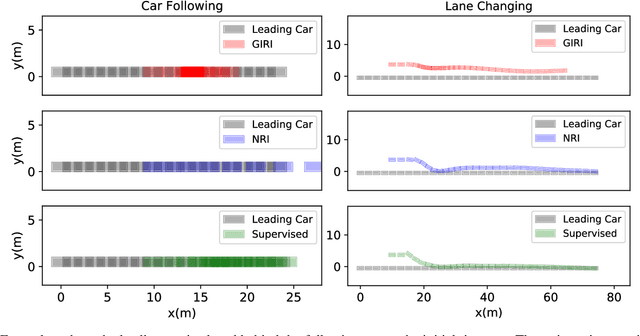
Explainability is essential for autonomous vehicles and other robotics systems interacting with humans and other objects during operation. Humans need to understand and anticipate the actions taken by the machines for trustful and safe cooperation. In this work, we aim to enable the explainability of an autonomous driving system at the design stage by incorporating expert domain knowledge into the model. We propose Grounded Relational Inference (GRI). It models an interactive system's underlying dynamics by inferring an interaction graph representing the agents' relations. We ensure an interpretable interaction graph by grounding the relational latent space into semantic behaviors defined with expert domain knowledge. We demonstrate that it can model interactive traffic scenarios under both simulation and real-world settings, and generate interpretable graphs explaining the vehicle's behavior by their interactions.
Interaction Graphs for Object Importance Estimation in On-road Driving Videos
Mar 12, 2020
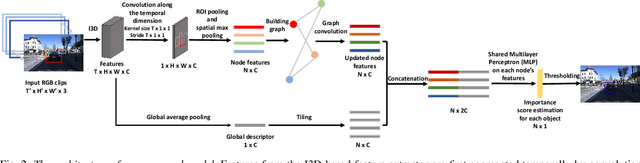


A vehicle driving along the road is surrounded by many objects, but only a small subset of them influence the driver's decisions and actions. Learning to estimate the importance of each object on the driver's real-time decision-making may help better understand human driving behavior and lead to more reliable autonomous driving systems. Solving this problem requires models that understand the interactions between the ego-vehicle and the surrounding objects. However, interactions among other objects in the scene can potentially also be very helpful, e.g., a pedestrian beginning to cross the road between the ego-vehicle and the car in front will make the car in front less important. We propose a novel framework for object importance estimation using an interaction graph, in which the features of each object node are updated by interacting with others through graph convolution. Experiments show that our model outperforms state-of-the-art baselines with much less input and pre-processing.
Context Aware Road-user Importance Estimation (iCARE)
Aug 30, 2019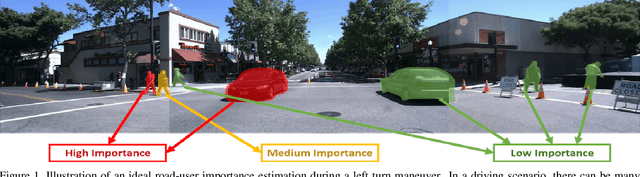
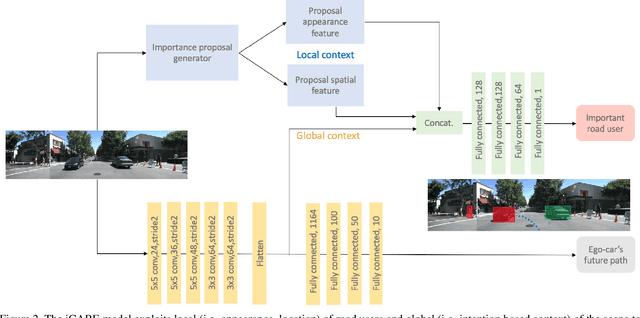

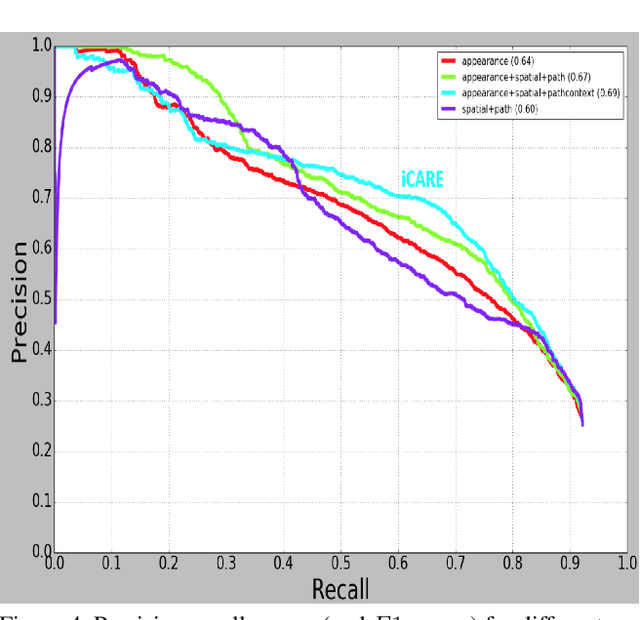
Road-users are a critical part of decision-making for both self-driving cars and driver assistance systems. Some road-users, however, are more important for decision-making than others because of their respective intentions, ego vehicle's intention and their effects on each other. In this paper, we propose a novel architecture for road-user importance estimation which takes advantage of the local and global context of the scene. For local context, the model exploits the appearance of the road users (which captures orientation, intention, etc.) and their location relative to ego-vehicle. The global context in our model is defined based on the feature map of the convolutional layer of the module which predicts the future path of the ego-vehicle and contains rich global information of the scene (e.g., infrastructure, road lanes, etc.), as well as the ego vehicle's intention information. Moreover, this paper introduces a new data set of real-world driving, concentrated around inter-sections and includes annotations of important road users. Systematic evaluations of our proposed method against several baselines show promising results.
Goal-oriented Object Importance Estimation in On-road Driving Videos
May 08, 2019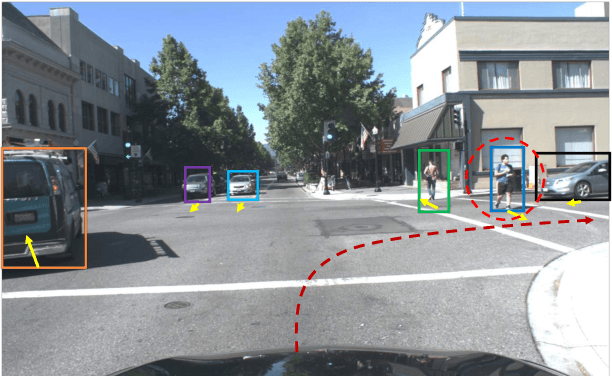
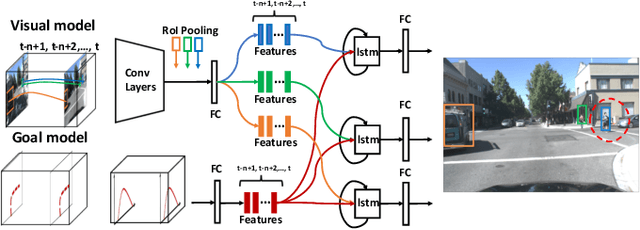
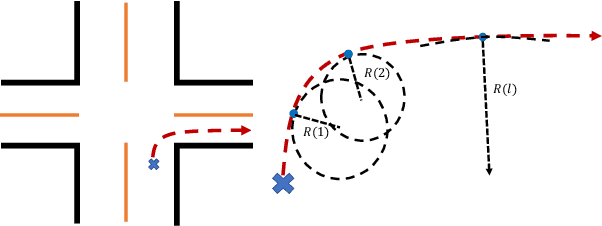
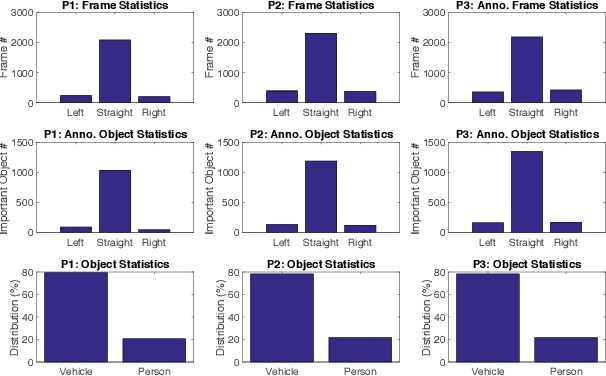
We formulate a new problem as Object Importance Estimation (OIE) in on-road driving videos, where the road users are considered as important objects if they have influence on the control decision of the ego-vehicle's driver. The importance of a road user depends on both its visual dynamics, e.g., appearance, motion and location, in the driving scene and the driving goal, \emph{e.g}., the planned path, of the ego vehicle. We propose a novel framework that incorporates both visual model and goal representation to conduct OIE. To evaluate our framework, we collect an on-road driving dataset at traffic intersections in the real world and conduct human-labeled annotation of the important objects. Experimental results show that our goal-oriented method outperforms baselines and has much more improvement on the left-turn and right-turn scenarios. Furthermore, we explore the possibility of using object importance for driving control prediction and demonstrate that binary brake prediction can be improved with the information of object importance.
Dynamics of Driver's Gaze: Explorations in Behavior Modeling & Maneuver Prediction
Jan 31, 2018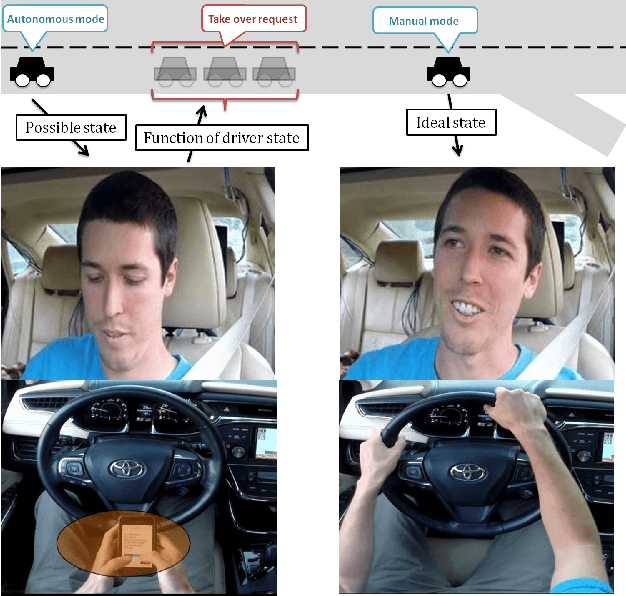
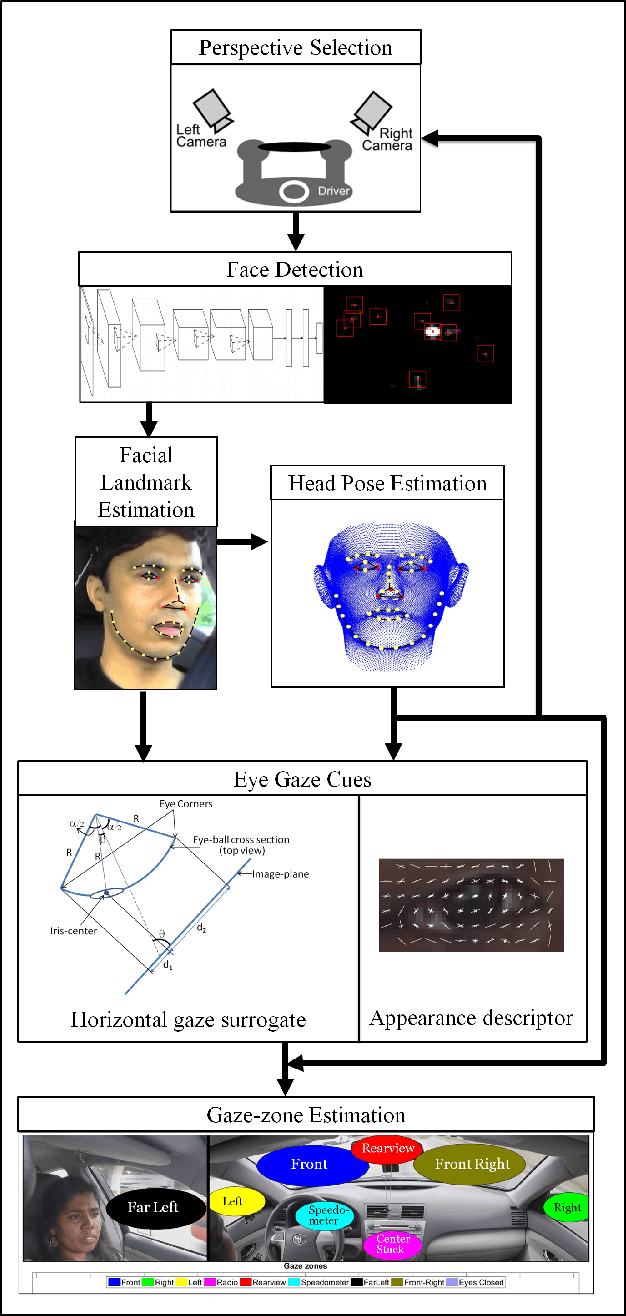
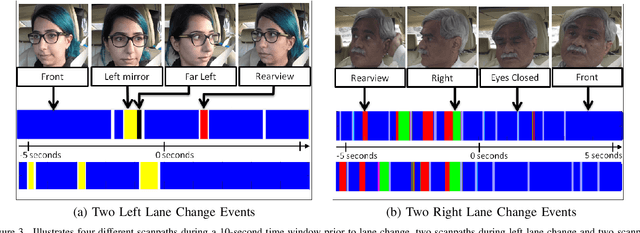
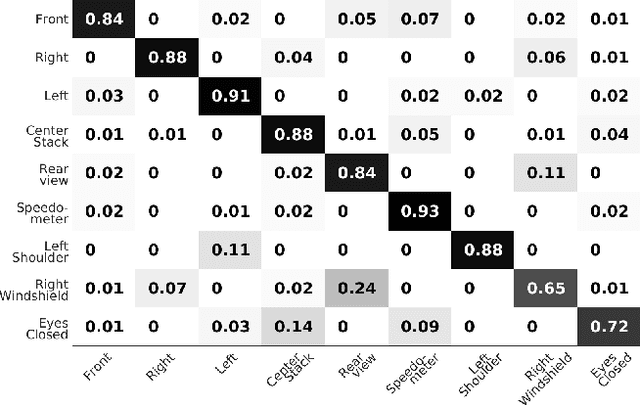
The study and modeling of driver's gaze dynamics is important because, if and how the driver is monitoring the driving environment is vital for driver assistance in manual mode, for take-over requests in highly automated mode and for semantic perception of the surround in fully autonomous mode. We developed a machine vision based framework to classify driver's gaze into context rich zones of interest and model driver's gaze behavior by representing gaze dynamics over a time period using gaze accumulation, glance duration and glance frequencies. As a use case, we explore the driver's gaze dynamic patterns during maneuvers executed in freeway driving, namely, left lane change maneuver, right lane change maneuver and lane keeping. It is shown that condensing gaze dynamics into durations and frequencies leads to recurring patterns based on driver activities. Furthermore, modeling these patterns show predictive powers in maneuver detection up to a few hundred milliseconds a priori.