 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIR-based Future Trajectory Prediction in Nighttime Autonomous Driving
Mar 31, 2023The performance of the current collision avoidance systems in Autonomous Vehicles (AV) and Advanced Driver Assistance Systems (ADAS) can be drastically affected by low light and adverse weather conditions. Collisions with large animals such as deer in low light cause significant cost and damage every year. In this paper, we propose the first AI-based method for future trajectory prediction of large animals and mitigating the risk of collision with them in low light. In order to minimize false collision warnings, in our multi-step framework, first, the large animal is accurately detected and a preliminary risk level is predicted for it and low-risk animals are discarded. In the next stage, a multi-stream CONV-LSTM-based encoder-decoder framework is designed to predict the future trajectory of the potentially high-risk animals. The proposed model uses camera motion prediction as well as the local and global context of the scene to generate accurate predictions. Furthermore, this paper introduces a new dataset of FIR videos for large animal detection and risk estimation in real nighttime driving scenarios. Our experiments show promising results of the proposed framework in adverse conditions. Our code is available online.
Using simulation to quantify the performance of automotive perception systems
Mar 10, 2023



The design and evaluation of complex systems can benefit from a software simulation - sometimes called a digital twin. The simulation can be used to characterize system performance or to test its performance under conditions that are difficult to measure (e.g., nighttime for automotive perception systems). We describe the image system simulation software tools that we use to evaluate the performance of image systems for object (automobile) detection. We describe experiments with 13 different cameras with a variety of optics and pixel sizes. To measure the impact of camera spatial resolution, we designed a collection of driving scenes that had cars at many different distances. We quantified system performance by measuring average precision and we report a trend relating system resolution and object detection performance. We also quantified the large performance degradation under nighttime conditions, compared to daytime, for all cameras and a COCO pre-trained network.
Context Aware Road-user Importance Estimation (iCARE)
Aug 30, 2019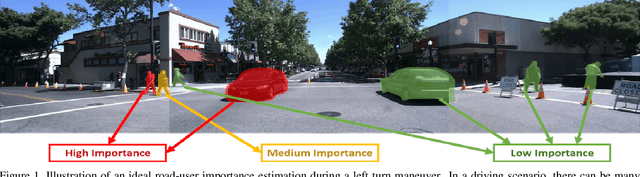
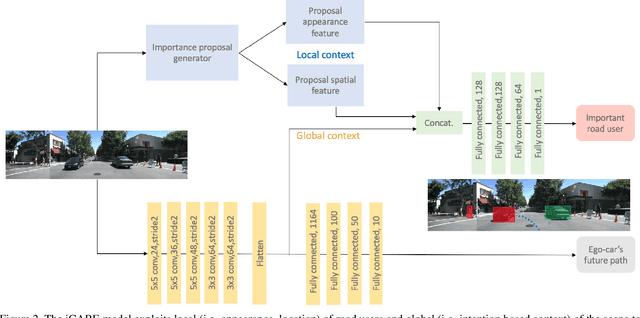

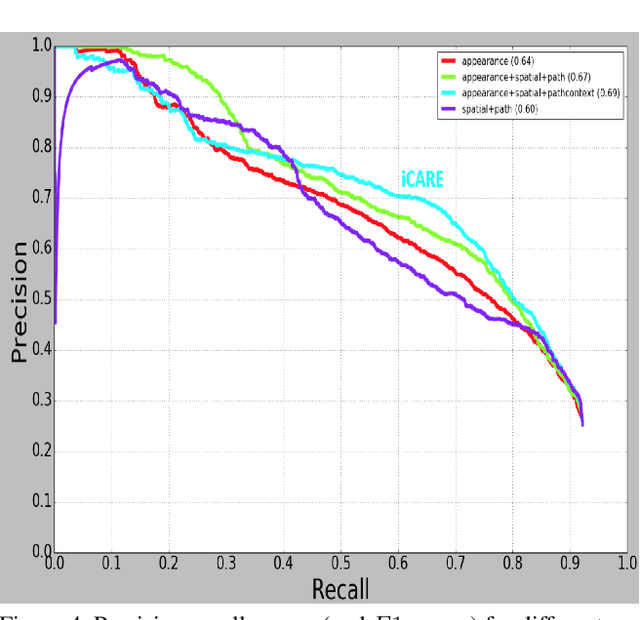
Road-users are a critical part of decision-making for both self-driving cars and driver assistance systems. Some road-users, however, are more important for decision-making than others because of their respective intentions, ego vehicle's intention and their effects on each other. In this paper, we propose a novel architecture for road-user importance estimation which takes advantage of the local and global context of the scene. For local context, the model exploits the appearance of the road users (which captures orientation, intention, etc.) and their location relative to ego-vehicle. The global context in our model is defined based on the feature map of the convolutional layer of the module which predicts the future path of the ego-vehicle and contains rich global information of the scene (e.g., infrastructure, road lanes, etc.), as well as the ego vehicle's intention information. Moreover, this paper introduces a new data set of real-world driving, concentrated around inter-sections and includes annotations of important road users. Systematic evaluations of our proposed method against several baselines show promising results.
advPattern: Physical-World Attacks on Deep Person Re-Identification via Adversarially Transformable Patterns
Aug 28, 2019


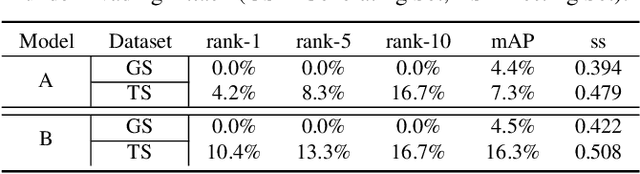
Person re-identification (re-ID) is the task of matching person images across camera views, which plays an important role in surveillance and security applications. Inspired by great progress of deep learning, deep re-ID models began to be popular and gained state-of-the-art performance. However, recent works found that deep neural networks (DNNs) are vulnerable to adversarial examples, posing potential threats to DNNs based applications. This phenomenon throws a serious question about whether deep re-ID based systems are vulnerable to adversarial attacks. In this paper, we take the first attempt to implement robust physical-world attacks against deep re-ID. We propose a novel attack algorithm, called advPattern, for generating adversarial patterns on clothes, which learns the variations of image pairs across cameras to pull closer the image features from the same camera, while pushing features from different cameras farther. By wearing our crafted "invisible cloak", an adversary can evade person search, or impersonate a target person to fool deep re-ID models in physical world. We evaluate the effectiveness of our transformable patterns on adversaries'clothes with Market1501 and our established PRCS dataset. The experimental results show that the rank-1 accuracy of re-ID models for matching the adversary decreases from 87.9% to 27.1% under Evading Attack. Furthermore, the adversary can impersonate a target person with 47.1% rank-1 accuracy and 67.9% mAP under Impersonation Attack. The results demonstrate that deep re-ID systems are vulnerable to our physical attacks.
Attention-based Few-Shot Person Re-identification Using Meta Learning
Oct 08, 2018
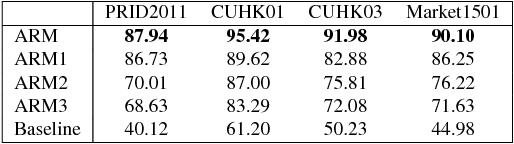
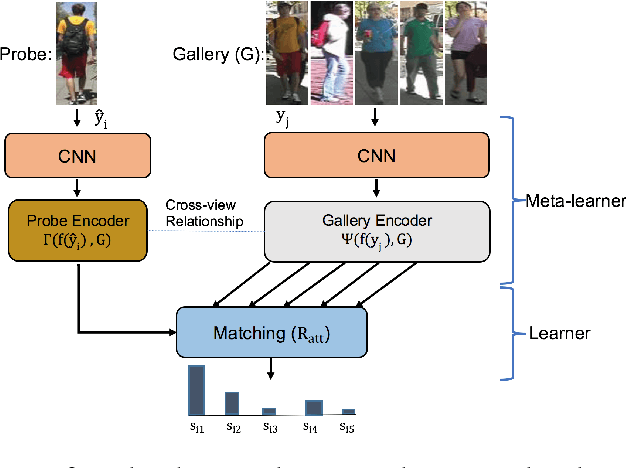
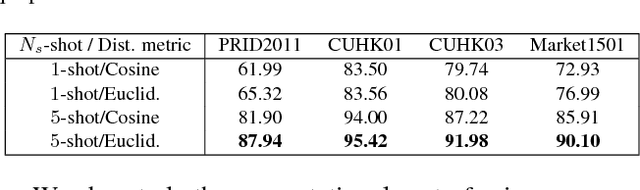
In this paper, we investigate the challenging task of person re-identification from a new perspective and propose an end-to-end attention-based architecture for few-shot re-identification through meta-learning. The motivation for this task lies in the fact that humans, can usually identify another person after just seeing that given person a few times (or even once) by attending to their memory. On the other hand, the unique nature of the person re-identification problem, i.e., only few examples exist per identity and new identities always appearing during testing, calls for a few shot learning architecture with the capacity of handling new identities. Hence, we frame the problem within a meta-learning setting, where a neural network based meta-learner is trained to optimize a learner i.e., an attention-based matching function. Another challenge of the person re-identification problem is the small inter-class difference between different identities and large intra-class difference of the same identity. In order to increase the discriminative power of the model, we propose a new attention-based feature encoding scheme that takes into account the critical intra-view and cross-view relationship of images. We refer to the proposed Attention-based Re-identification Metalearning model as ARM. Extensive evaluations demonstrate the advantages of the ARM as compared to the state-of-the-art on the challenging PRID2011, CUHK01, CUHK03 and Market1501 datasets.
Person Re-identification Using Visual Attention
Jun 25, 2018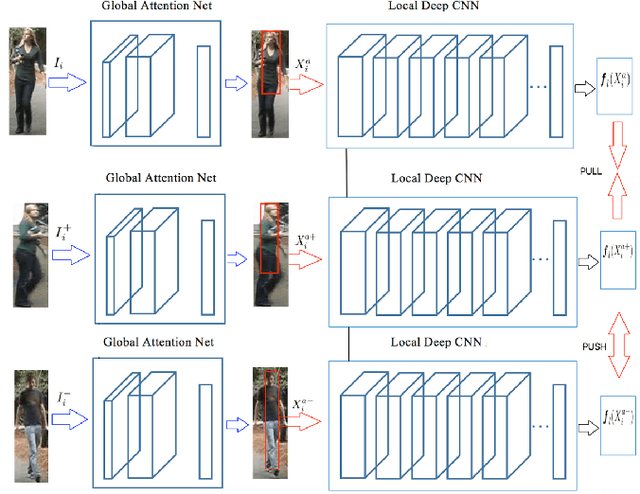
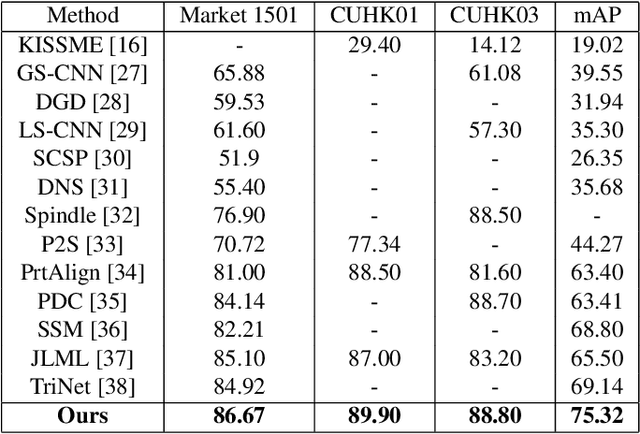


Despite recent attempts for solving the person re-identification problem, it remains a challenging task since a person's appearance can vary significantly when large variations in view angle, human pose and illumination are involved. The concept of attention is one of the most interesting recent architectural innovations in neural networks. Inspired by that, in this paper we propose a novel approach based on using a gradient-based attention mechanism in deep convolution neural network for solving the person re-identification problem. Our model learns to focus selectively on parts of the input image for which the networks' output is most sensitive to. Extensive comparative evaluations demonstrate that the proposed method outperforms state-of-the-art approaches, including both traditional and deep neural network-based methods on the challenging CUHK01, CUHK03, and Market1501 datasets.
Feature Encoding in Band-limited Distributed Surveillance Systems
Jun 06, 2017

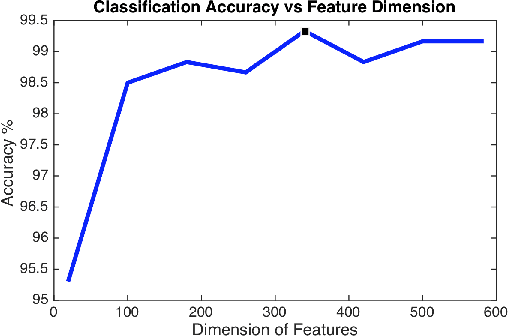
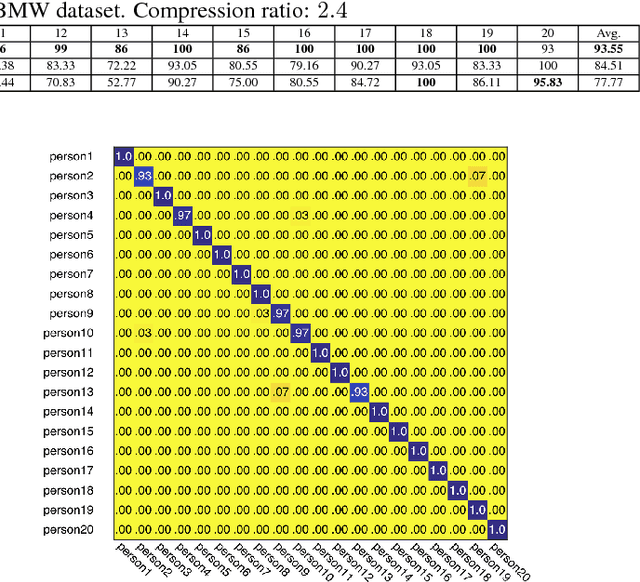
Distributed surveillance systems have become popular in recent years due to security concerns. However, transmitting high dimensional data in bandwidth-limited distributed systems becomes a major challenge. In this paper, we address this issue by proposing a novel probabilistic algorithm based on the divergence between the probability distributions of the visual features in order to reduce their dimensionality and thus save the network bandwidth in distributed wireless smart camera networks. We demonstrate the effectiveness of the proposed approach through extensive experiments on two surveillance recognition tasks.
End-to-end Binary Representation Learning via Direct Binary Embedding
Jun 04, 2017
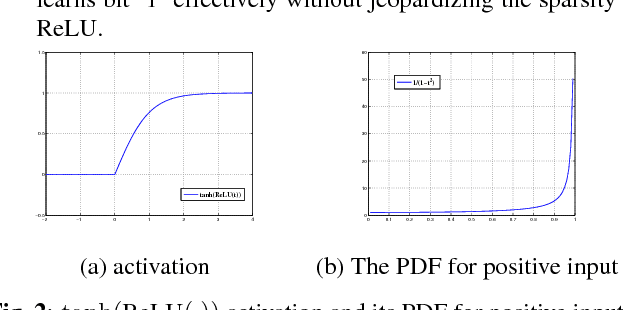

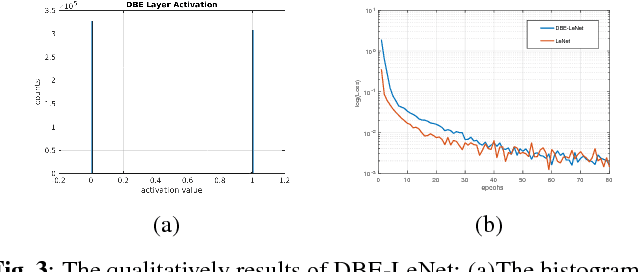
Learning binary representation is essential to large-scale computer vision tasks. Most existing algorithms require a separate quantization constraint to learn effective hashing functions. In this work, we present Direct Binary Embedding (DBE), a simple yet very effective algorithm to learn binary representation in an end-to-end fashion. By appending an ingeniously designed DBE layer to the deep convolutional neural network (DCNN), DBE learns binary code directly from the continuous DBE layer activation without quantization error. By employing the deep residual network (ResNet) as DCNN component, DBE captures rich semantics from images. Furthermore, in the effort of handling multilabel images, we design a joint cross entropy loss that includes both softmax cross entropy and weighted binary cross entropy in consideration of the correlation and independence of labels, respectively. Extensive experiments demonstrate the significant superiority of DBE over state-of-the-art methods on tasks of natural object recognition, image retrieval and image annotation.
Multi-View Task-Driven Recognition in Visual Sensor Networks
May 31, 2017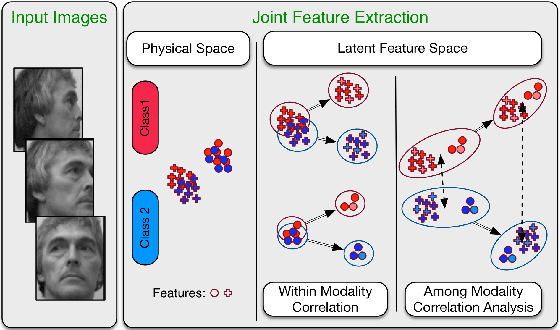



Nowadays, distributed smart cameras are deployed for a wide set of tasks in several application scenarios, ranging from object recognition, image retrieval, and forensic applications. Due to limited bandwidth in distributed systems, efficient coding of local visual features has in fact been an active topic of research. In this paper, we propose a novel approach to obtain a compact representation of high-dimensional visual data using sensor fusion techniques. We convert the problem of visual analysis in resource-limited scenarios to a multi-view representation learning, and we show that the key to finding properly compressed representation is to exploit the position of cameras with respect to each other as a norm-based regularization in the particular signal representation of sparse coding. Learning the representation of each camera is viewed as an individual task and a multi-task learning with joint sparsity for all nodes is employed. The proposed representation learning scheme is referred to as the multi-view task-driven learning for visual sensor network (MT-VSN). We demonstrate that MT-VSN outperforms state-of-the-art in various surveillance recognition tasks.