 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhispEar: A Bi-directional Framework for Scaling Whispered Speech Conversion via Pseudo-Parallel Whisper Generation
Mar 09, 2026Whispered speech lacks vocal fold vibration and fundamental frequency, resulting in degraded acoustic cues and making whisper-to-normal (W2N) conversion challenging, especially with limited parallel data. We propose WhispEar, a bidirectional framework based on unified semantic representations that capture speaking-mode-invariant information shared by whispered and normal speech. The framework contains both W2N and normal-to-whisper (N2W) models. Notably, the N2W model enables zero-shot pseudo-parallel whisper generation from abundant normal speech, allowing scalable data augmentation for W2N training. Increasing generated data consistently improves performance. We also release the largest bilingual (Chinese-English) whispered-normal parallel corpus to date. Experiments demonstrate that WhispEar outperforms strong baselines and benefits significantly from scalable pseudo-parallel data.
ISETHDR: A Physics-based Synthetic Radiance Dataset for High Dynamic Range Driving Scenes
Aug 22, 2024This paper describes a physics-based end-to-end software simulation for image systems. We use the software to explore sensors designed to enhance performance in high dynamic range (HDR) environments, such as driving through daytime tunnels and under nighttime conditions. We synthesize physically realistic HDR spectral radiance images and use them as the input to digital twins that model the optics and sensors of different systems. This paper makes three main contributions: (a) We create a labeled (instance segmentation and depth), synthetic radiance dataset of HDR driving scenes. (b) We describe the development and validation of the end-to-end simulation framework. (c) We present a comparative analysis of two single-shot sensors designed for HDR. We open-source both the dataset and the software.
SynFog: A Photo-realistic Synthetic Fog Dataset based on End-to-end Imaging Simulation for Advancing Real-World Defogging in Autonomous Driving
Mar 25, 2024



To advance research in learning-based defogging algorithms, various synthetic fog datasets have been developed. However, existing datasets created using the Atmospheric Scattering Model (ASM) or real-time rendering engines often struggle to produce photo-realistic foggy images that accurately mimic the actual imaging process. This limitation hinders the effective generalization of models from synthetic to real data. In this paper, we introduce an end-to-end simulation pipeline designed to generate photo-realistic foggy images. This pipeline comprehensively considers the entire physically-based foggy scene imaging process, closely aligning with real-world image capture methods. Based on this pipeline, we present a new synthetic fog dataset named SynFog, which features both sky light and active lighting conditions, as well as three levels of fog density. Experimental results demonstrate that models trained on SynFog exhibit superior performance in visual perception and detection accuracy compared to others when applied to real-world foggy images.
ChatSOS: LLM-based knowledge Q&A system for safety engineering
Dec 14, 2023Recent advancements in large language models (LLMs) have notably propelled natural language processing (NLP) capabilities, demonstrating significant potential in safety engineering applications. Despite these advancements, LLMs face constraints in processing specialized tasks, attributed to factors such as corpus size, input processing limitations, and privacy concerns. Obtaining useful information from reliable sources in a limited time is crucial for LLM. Addressing this, our study introduces an LLM-based Q&A system for safety engineering, enhancing the comprehension and response accuracy of the model. We employed prompt engineering to incorporate external knowledge databases, thus enriching the LLM with up-to-date and reliable information. The system analyzes historical incident reports through statistical methods, utilizes vector embedding to construct a vector database, and offers an efficient similarity-based search functionality. Our findings indicate that the integration of external knowledge significantly augments the capabilities of LLM for in-depth problem analysis and autonomous task assignment. It effectively summarizes accident reports and provides pertinent recommendations. This integration approach not only expands LLM applications in safety engineering but also sets a precedent for future developments towards automation and intelligent systems.
Using simulation to quantify the performance of automotive perception systems
Mar 10, 2023



The design and evaluation of complex systems can benefit from a software simulation - sometimes called a digital twin. The simulation can be used to characterize system performance or to test its performance under conditions that are difficult to measure (e.g., nighttime for automotive perception systems). We describe the image system simulation software tools that we use to evaluate the performance of image systems for object (automobile) detection. We describe experiments with 13 different cameras with a variety of optics and pixel sizes. To measure the impact of camera spatial resolution, we designed a collection of driving scenes that had cars at many different distances. We quantified system performance by measuring average precision and we report a trend relating system resolution and object detection performance. We also quantified the large performance degradation under nighttime conditions, compared to daytime, for all cameras and a COCO pre-trained network.
ISETAuto: Detecting vehicles with depth and radiance information
Jan 07, 2021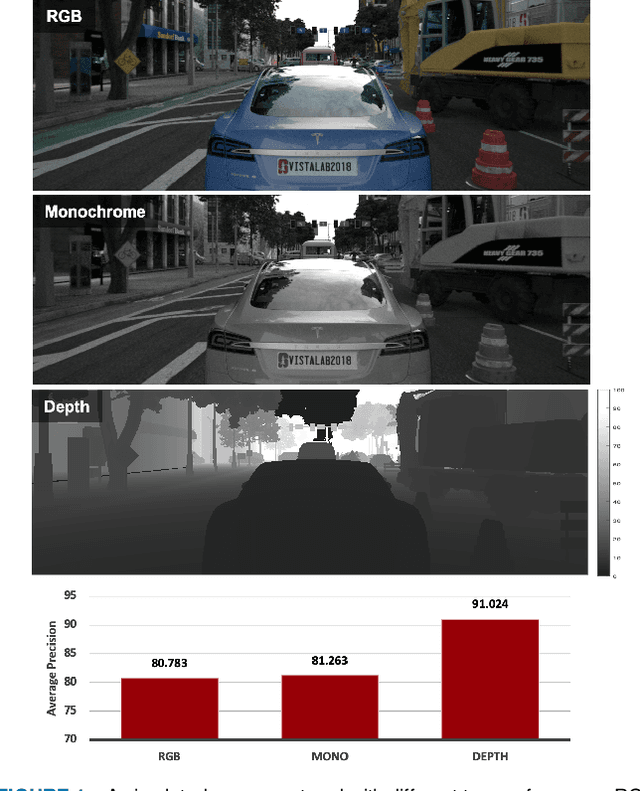

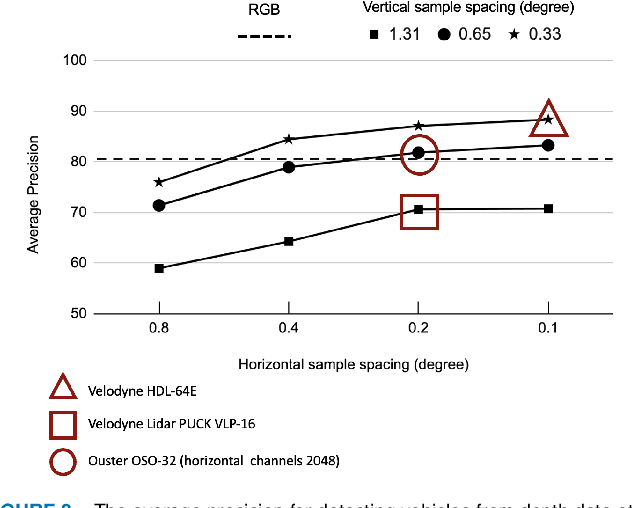
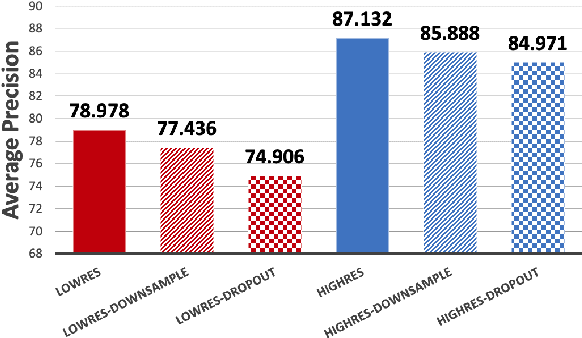
Autonomous driving applications use two types of sensor systems to identify vehicles - depth sensing LiDAR and radiance sensing cameras. We compare the performance (average precision) of a ResNet for vehicle detection in complex, daytime, driving scenes when the input is a depth map (D = d(x,y)), a radiance image (L = r(x,y)), or both [D,L]. (1) When the spatial sampling resolution of the depth map and radiance image are equal to typical camera resolutions, a ResNet detects vehicles at higher average precision from depth than radiance. (2) As the spatial sampling of the depth map declines to the range of current LiDAR devices, the ResNet average precision is higher for radiance than depth. (3) For a hybrid system that combines a depth map and radiance image, the average precision is higher than using depth or radiance alone. We established these observations in simulation and then confirmed them using realworld data. The advantage of combining depth and radiance can be explained by noting that the two type of information have complementary weaknesses. The radiance data are limited by dynamic range and motion blur. The LiDAR data have relatively low spatial resolution. The ResNet combines the two data sources effectively to improve overall vehicle detection.
Vehicle Reconstruction and Texture Estimation Using Deep Implicit Semantic Template Mapping
Nov 30, 2020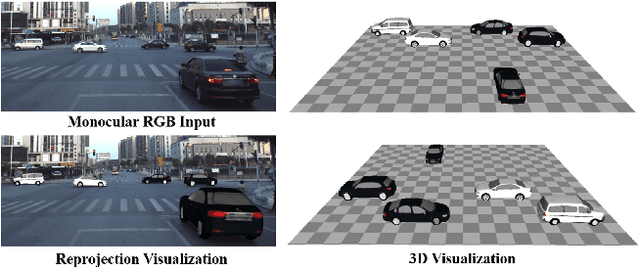
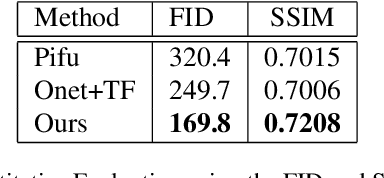
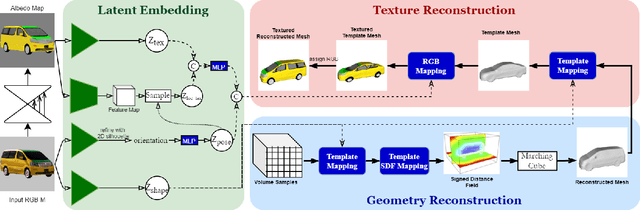
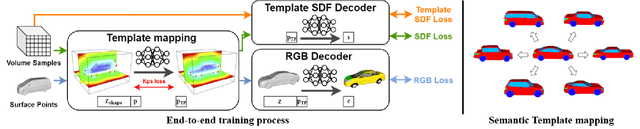
We introduce VERTEX, an effective solution to recover 3D shape and intrinsic texture of vehicles from uncalibrated monocular input in real-world street environments. To fully utilize the template prior of vehicles, we propose a novel geometry and texture joint representation, based on implicit semantic template mapping. Compared to existing representations which infer 3D texture distribution, our method explicitly constrains the texture distribution on the 2D surface of the template as well as avoids limitations of fixed resolution and topology. Moreover, by fusing the global and local features together, our approach is capable to generate consistent and detailed texture in both visible and invisible areas. We also contribute a new synthetic dataset containing 830 elaborate textured car models labeled with sparse key points and rendered using Physically Based Rendering (PBRT) system with measured HDRI skymaps to obtain highly realistic images. Experiments demonstrate the superior performance of our approach on both testing dataset and in-the-wild images. Furthermore, the presented technique enables additional applications such as 3D vehicle texture transfer and material identification.
Neural Network Generalization: The impact of camera parameters
Dec 08, 2019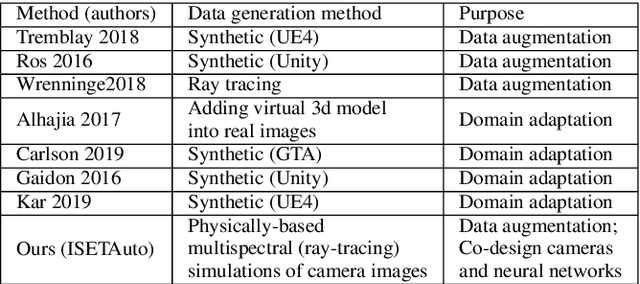
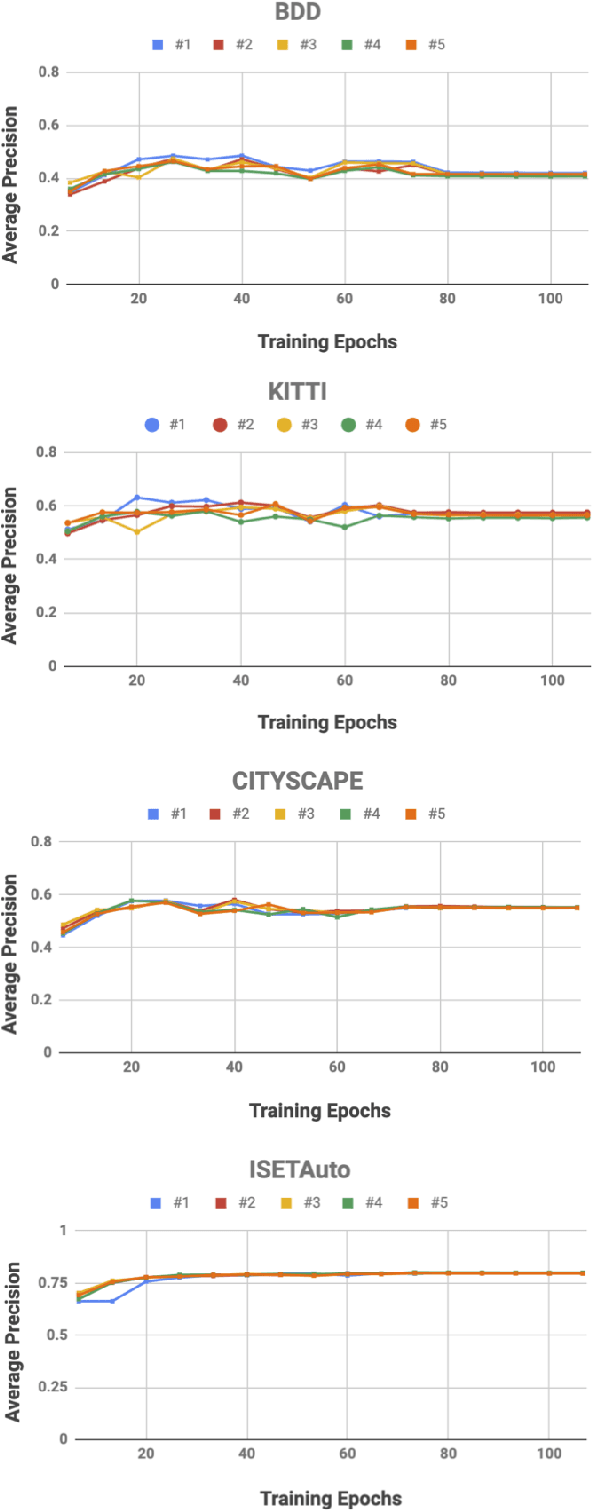
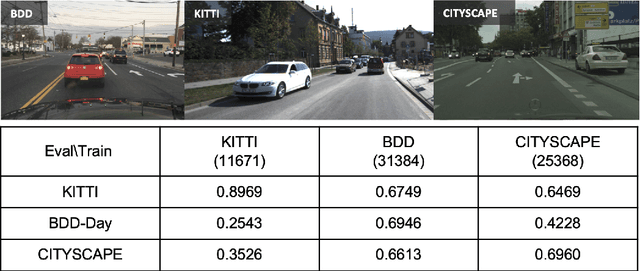
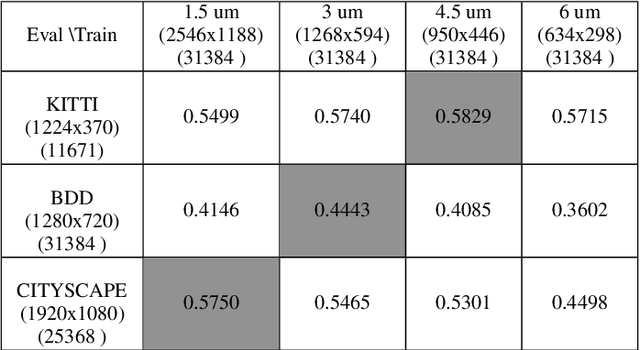
We quantify the generalization of a convolutional neural network (CNN) trained to identify cars. First, we perform a series of experiments to train the network using one image dataset - either synthetic or from a camera - and then test on a different image dataset. We show that generalization between images obtained with different cameras is roughly the same as generalization between images from a camera and ray-traced multispectral synthetic images. Second, we use ISETAuto, a soft prototyping tool that creates ray-traced multispectral simulations of camera images, to simulate sensor images with a range of pixel sizes, color filters, acquisition and post-acquisition processing. These experiments reveal how variations in specific camera parameters and image processing operations impact CNN generalization. We find that (a) pixel size impacts generalization, (b) demosaicking substantially impacts performance and generalization for shallow (8-bit) bit-depths but not deeper ones (10-bit), and (c) the network performs well using raw (not demosaicked) sensor data for 10-bit pixels.
Soft Prototyping Camera Designs for Car Detection Based on a Convolutional Neural Network
Oct 24, 2019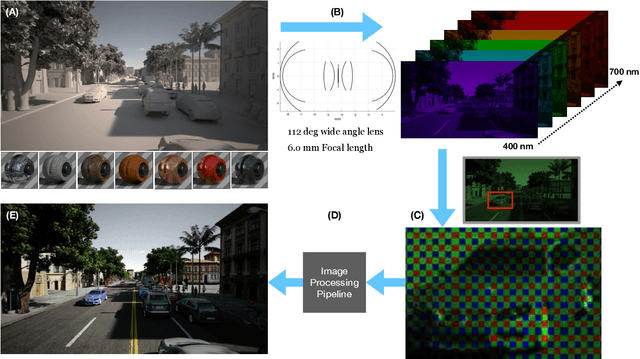
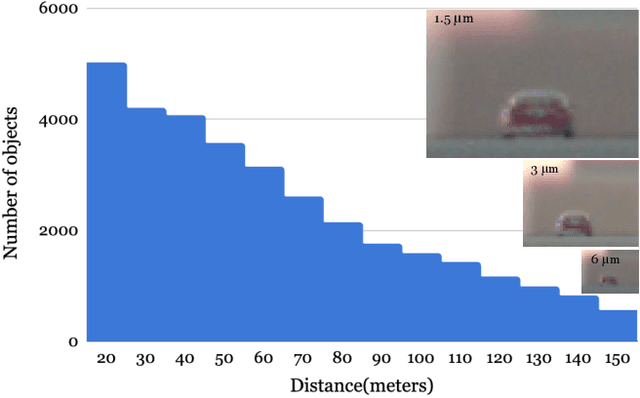
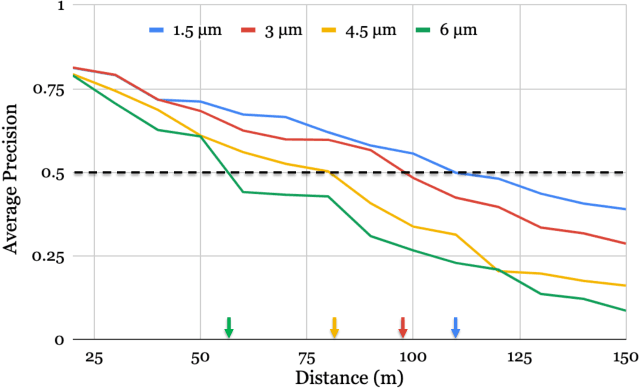
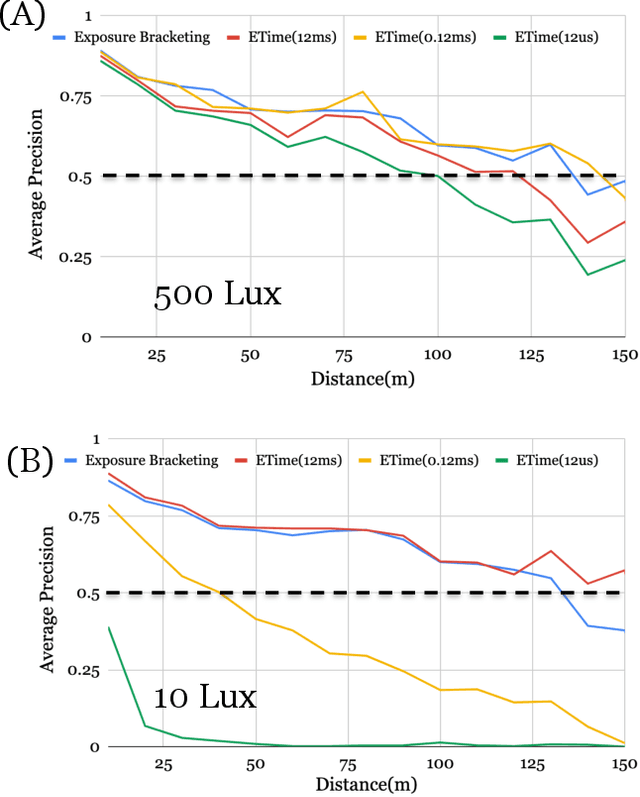
Imaging systems are increasingly used as input to convolutional neural networks (CNN) for object detection; we would like to design cameras that are optimized for this purpose. It is impractical to build different cameras and then acquire and label the necessary data for every potential camera design; creating software simulations of the camera in context (soft prototyping) is the only realistic approach. We implemented soft-prototyping tools that can quantitatively simulate image radiance and camera designs to create realistic images that are input to a convolutional neural network for car detection. We used these methods to quantify the effect that critical hardware components (pixel size), sensor control (exposure algorithms) and image processing (gamma and demosaicing algorithms) have upon average precision of car detection. We quantify (a) the relationship between pixel size and the ability to detect cars at different distances, (b) the penalty for choosing a poor exposure duration, and (c) the ability of the CNN to perform car detection for a variety of post-acquisition processing algorithms. These results show that the optimal choices for car detection are not constrained by the same metrics used for image quality in consumer photography. It is better to evaluate camera designs for CNN applications using soft prototyping with task-specific metrics rather than consumer photography metrics.
A system for generating complex physically accurate sensor images for automotive applications
Feb 12, 2019



We describe an open-source simulator that creates sensor irradiance and sensor images of typical automotive scenes in urban settings. The purpose of the system is to support camera design and testing for automotive applications. The user can specify scene parameters (e.g., scene type, road type, traffic density, time of day) to assemble a large number of random scenes from graphics assets stored in a database. The sensor irradiance is generated using quantitative computer graphics methods, and the sensor images are created using image systems sensor simulation. The synthetic sensor images have pixel level annotations; hence, they can be used to train and evaluate neural networks for imaging tasks, such as object detection and classification. The end-to-end simulation system supports quantitative assessment, from scene to camera to network accuracy, for automotive applications.