 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoDiff4D: Geometry-Aware Diffusion for 4D Head Avatar Reconstruction
Feb 27, 2026Reconstructing photorealistic and animatable 4D head avatars from a single portrait image remains a fundamental challenge in computer vision. While diffusion models have enabled remarkable progress in image and video generation for avatar reconstruction, existing methods primarily rely on 2D priors and struggle to achieve consistent 3D geometry. We propose a novel framework that leverages geometry-aware diffusion to learn strong geometry priors for high-fidelity head avatar reconstruction. Our approach jointly synthesizes portrait images and corresponding surface normals, while a pose-free expression encoder captures implicit expression representations. Both synthesized images and expression latents are incorporated into 3D Gaussian-based avatars, enabling photorealistic rendering with accurate geometry. Extensive experiments demonstrate that our method substantially outperforms state-of-the-art approaches in visual quality, expression fidelity, and cross-identity generalization, while supporting real-time rendering.
HyMem: Hybrid Memory Architecture with Dynamic Retrieval Scheduling
Feb 15, 2026Large language model (LLM) agents demonstrate strong performance in short-text contexts but often underperform in extended dialogues due to inefficient memory management. Existing approaches face a fundamental trade-off between efficiency and effectiveness: memory compression risks losing critical details required for complex reasoning, while retaining raw text introduces unnecessary computational overhead for simple queries. The crux lies in the limitations of monolithic memory representations and static retrieval mechanisms, which fail to emulate the flexible and proactive memory scheduling capabilities observed in humans, thus struggling to adapt to diverse problem scenarios. Inspired by the principle of cognitive economy, we propose HyMem, a hybrid memory architecture that enables dynamic on-demand scheduling through multi-granular memory representations. HyMem adopts a dual-granular storage scheme paired with a dynamic two-tier retrieval system: a lightweight module constructs summary-level context for efficient response generation, while an LLM-based deep module is selectively activated only for complex queries, augmented by a reflection mechanism for iterative reasoning refinement. Experiments show that HyMem achieves strong performance on both the LOCOMO and LongMemEval benchmarks, outperforming full-context while reducing computational cost by 92.6\%, establishing a state-of-the-art balance between efficiency and performance in long-term memory management.
Temporal Separation with Entropy Regularization for Knowledge Distillation in Spiking Neural Networks
Mar 05, 2025
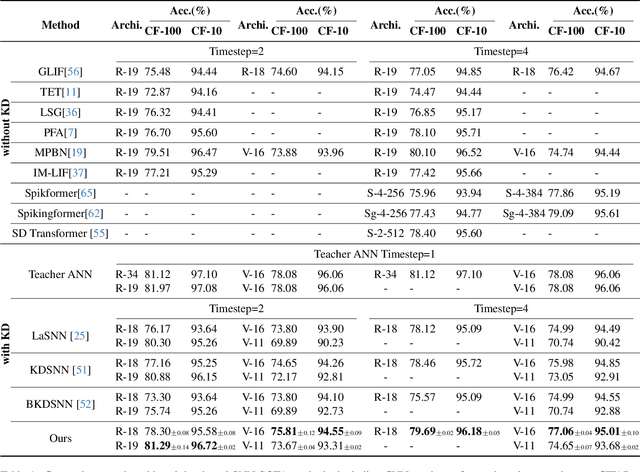


Spiking Neural Networks (SNNs), inspired by the human brain, offer significant computational efficiency through discrete spike-based information transfer. Despite their potential to reduce inference energy consumption, a performance gap persists between SNNs and Artificial Neural Networks (ANNs), primarily due to current training methods and inherent model limitations. While recent research has aimed to enhance SNN learning by employing knowledge distillation (KD) from ANN teacher networks, traditional distillation techniques often overlook the distinctive spatiotemporal properties of SNNs, thus failing to fully leverage their advantages. To overcome these challenge, we propose a novel logit distillation method characterized by temporal separation and entropy regularization. This approach improves existing SNN distillation techniques by performing distillation learning on logits across different time steps, rather than merely on aggregated output features. Furthermore, the integration of entropy regularization stabilizes model optimization and further boosts the performance. Extensive experimental results indicate that our method surpasses prior SNN distillation strategies, whether based on logit distillation, feature distillation, or a combination of both. The code will be available on GitHub.
Efficient Distillation of Deep Spiking Neural Networks for Full-Range Timestep Deployment
Jan 27, 2025Spiking Neural Networks (SNNs) are emerging as a brain-inspired alternative to traditional Artificial Neural Networks (ANNs), prized for their potential energy efficiency on neuromorphic hardware. Despite this, SNNs often suffer from accuracy degradation compared to ANNs and face deployment challenges due to fixed inference timesteps, which require retraining for adjustments, limiting operational flexibility. To address these issues, our work considers the spatio-temporal property inherent in SNNs, and proposes a novel distillation framework for deep SNNs that optimizes performance across full-range timesteps without specific retraining, enhancing both efficacy and deployment adaptability. We provide both theoretical analysis and empirical validations to illustrate that training guarantees the convergence of all implicit models across full-range timesteps. Experimental results on CIFAR-10, CIFAR-100, CIFAR10-DVS, and ImageNet demonstrate state-of-the-art performance among distillation-based SNNs training methods.
Stereo-Talker: Audio-driven 3D Human Synthesis with Prior-Guided Mixture-of-Experts
Oct 31, 2024



This paper introduces Stereo-Talker, a novel one-shot audio-driven human video synthesis system that generates 3D talking videos with precise lip synchronization, expressive body gestures, temporally consistent photo-realistic quality, and continuous viewpoint control. The process follows a two-stage approach. In the first stage, the system maps audio input to high-fidelity motion sequences, encompassing upper-body gestures and facial expressions. To enrich motion diversity and authenticity, large language model (LLM) priors are integrated with text-aligned semantic audio features, leveraging LLMs' cross-modal generalization power to enhance motion quality. In the second stage, we improve diffusion-based video generation models by incorporating a prior-guided Mixture-of-Experts (MoE) mechanism: a view-guided MoE focuses on view-specific attributes, while a mask-guided MoE enhances region-based rendering stability. Additionally, a mask prediction module is devised to derive human masks from motion data, enhancing the stability and accuracy of masks and enabling mask guiding during inference. We also introduce a comprehensive human video dataset with 2,203 identities, covering diverse body gestures and detailed annotations, facilitating broad generalization. The code, data, and pre-trained models will be released for research purposes.
DreamCraft3D++: Efficient Hierarchical 3D Generation with Multi-Plane Reconstruction Model
Oct 16, 2024
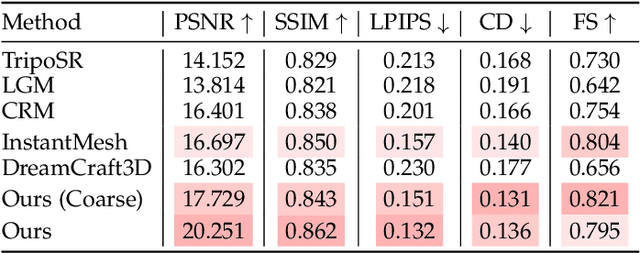


We introduce DreamCraft3D++, an extension of DreamCraft3D that enables efficient high-quality generation of complex 3D assets. DreamCraft3D++ inherits the multi-stage generation process of DreamCraft3D, but replaces the time-consuming geometry sculpting optimization with a feed-forward multi-plane based reconstruction model, speeding up the process by 1000x. For texture refinement, we propose a training-free IP-Adapter module that is conditioned on the enhanced multi-view images to enhance texture and geometry consistency, providing a 4x faster alternative to DreamCraft3D's DreamBooth fine-tuning. Experiments on diverse datasets demonstrate DreamCraft3D++'s ability to generate creative 3D assets with intricate geometry and realistic 360{\deg} textures, outperforming state-of-the-art image-to-3D methods in quality and speed. The full implementation will be open-sourced to enable new possibilities in 3D content creation.
InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars
Dec 03, 2023While high fidelity and efficiency are central to the creation of digital head avatars, recent methods relying on 2D or 3D generative models often experience limitations such as shape distortion, expression inaccuracy, and identity flickering. Additionally, existing one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction. We propose a novel framework, \textbf{Incremental 3D GAN Inversion}, that enhances avatar reconstruction performance using an algorithm designed to increase the fidelity from multiple frames, resulting in improved reconstruction quality proportional to frame count. Our method introduces a unique animatable 3D GAN prior with two crucial modifications for enhanced expression controllability alongside an innovative neural texture encoder that categorizes texture feature spaces based on UV parameterization. Differentiating from traditional techniques, our architecture emphasizes pixel-aligned image-to-image translation, mitigating the need to learn correspondences between observation and canonical spaces. Furthermore, we incorporate ConvGRU-based recurrent networks for temporal data aggregation from multiple frames, boosting geometry and texture detail reconstruction. The proposed paradigm demonstrates state-of-the-art performance on one-shot and few-shot avatar animation tasks.
High-Fidelity 3D Head Avatars Reconstruction through Spatially-Varying Expression Conditioned Neural Radiance Field
Oct 10, 2023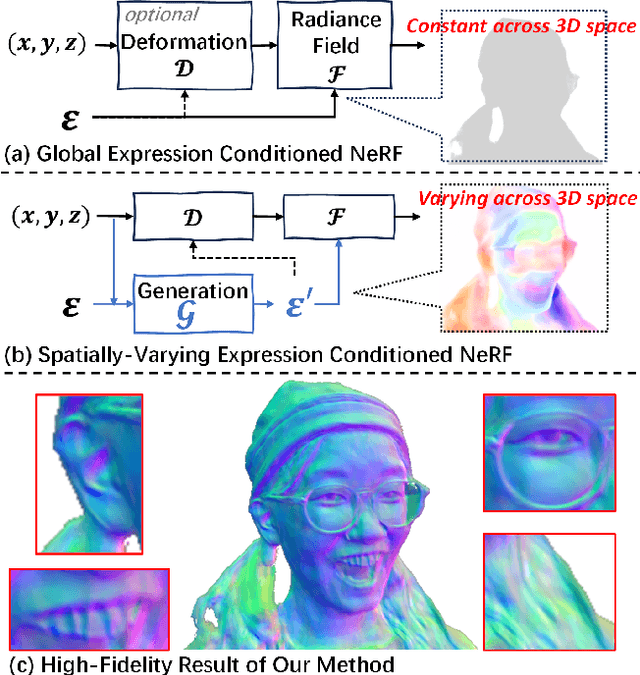
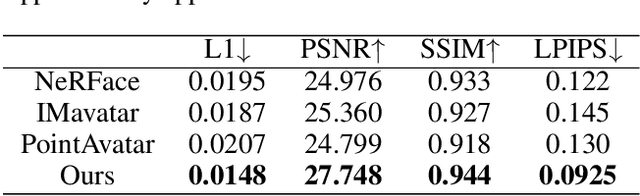
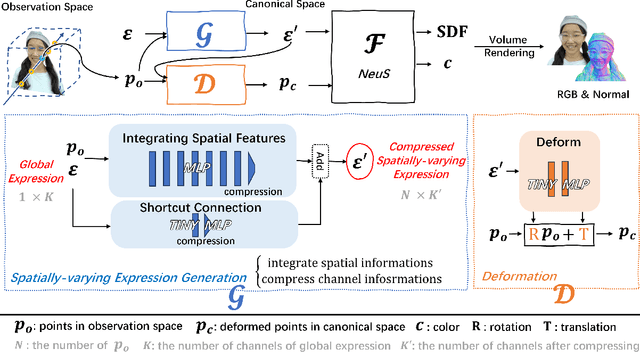
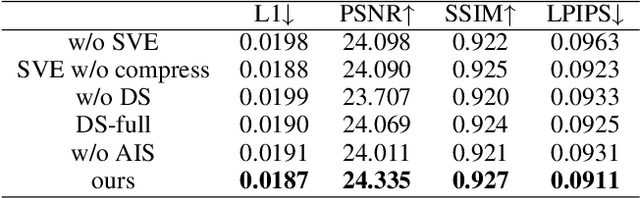
One crucial aspect of 3D head avatar reconstruction lies in the details of facial expressions. Although recent NeRF-based photo-realistic 3D head avatar methods achieve high-quality avatar rendering, they still encounter challenges retaining intricate facial expression details because they overlook the potential of specific expression variations at different spatial positions when conditioning the radiance field. Motivated by this observation, we introduce a novel Spatially-Varying Expression (SVE) conditioning. The SVE can be obtained by a simple MLP-based generation network, encompassing both spatial positional features and global expression information. Benefiting from rich and diverse information of the SVE at different positions, the proposed SVE-conditioned neural radiance field can deal with intricate facial expressions and achieve realistic rendering and geometry details of high-fidelity 3D head avatars. Additionally, to further elevate the geometric and rendering quality, we introduce a new coarse-to-fine training strategy, including a geometry initialization strategy at the coarse stage and an adaptive importance sampling strategy at the fine stage. Extensive experiments indicate that our method outperforms other state-of-the-art (SOTA) methods in rendering and geometry quality on mobile phone-collected and public datasets.
HAvatar: High-fidelity Head Avatar via Facial Model Conditioned Neural Radiance Field
Sep 29, 2023The problem of modeling an animatable 3D human head avatar under light-weight setups is of significant importance but has not been well solved. Existing 3D representations either perform well in the realism of portrait images synthesis or the accuracy of expression control, but not both. To address the problem, we introduce a novel hybrid explicit-implicit 3D representation, Facial Model Conditioned Neural Radiance Field, which integrates the expressiveness of NeRF and the prior information from the parametric template. At the core of our representation, a synthetic-renderings-based condition method is proposed to fuse the prior information from the parametric model into the implicit field without constraining its topological flexibility. Besides, based on the hybrid representation, we properly overcome the inconsistent shape issue presented in existing methods and improve the animation stability. Moreover, by adopting an overall GAN-based architecture using an image-to-image translation network, we achieve high-resolution, realistic and view-consistent synthesis of dynamic head appearance. Experiments demonstrate that our method can achieve state-of-the-art performance for 3D head avatar animation compared with previous methods.
AvatarReX: Real-time Expressive Full-body Avatars
May 08, 2023


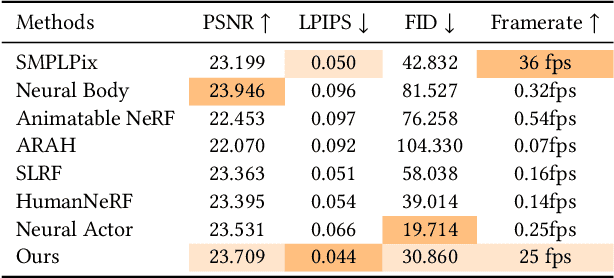
We present AvatarReX, a new method for learning NeRF-based full-body avatars from video data. The learnt avatar not only provides expressive control of the body, hands and the face together, but also supports real-time animation and rendering. To this end, we propose a compositional avatar representation, where the body, hands and the face are separately modeled in a way that the structural prior from parametric mesh templates is properly utilized without compromising representation flexibility. Furthermore, we disentangle the geometry and appearance for each part. With these technical designs, we propose a dedicated deferred rendering pipeline, which can be executed in real-time framerate to synthesize high-quality free-view images. The disentanglement of geometry and appearance also allows us to design a two-pass training strategy that combines volume rendering and surface rendering for network training. In this way, patch-level supervision can be applied to force the network to learn sharp appearance details on the basis of geometry estimation. Overall, our method enables automatic construction of expressive full-body avatars with real-time rendering capability, and can generate photo-realistic images with dynamic details for novel body motions and facial expressions.