 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Separation with Entropy Regularization for Knowledge Distillation in Spiking Neural Networks
Paper and Code
Mar 05, 2025
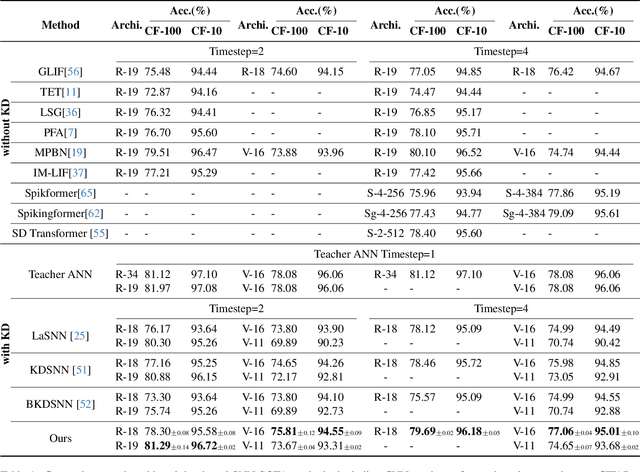


Spiking Neural Networks (SNNs), inspired by the human brain, offer significant computational efficiency through discrete spike-based information transfer. Despite their potential to reduce inference energy consumption, a performance gap persists between SNNs and Artificial Neural Networks (ANNs), primarily due to current training methods and inherent model limitations. While recent research has aimed to enhance SNN learning by employing knowledge distillation (KD) from ANN teacher networks, traditional distillation techniques often overlook the distinctive spatiotemporal properties of SNNs, thus failing to fully leverage their advantages. To overcome these challenge, we propose a novel logit distillation method characterized by temporal separation and entropy regularization. This approach improves existing SNN distillation techniques by performing distillation learning on logits across different time steps, rather than merely on aggregated output features. Furthermore, the integration of entropy regularization stabilizes model optimization and further boosts the performance. Extensive experimental results indicate that our method surpasses prior SNN distillation strategies, whether based on logit distillation, feature distillation, or a combination of both. The code will be available on GitHub.