 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities in AI/ML for the Rubin LSST Dark Energy Science Collaboration
Jan 20, 2026The Vera C. Rubin Observatory's Legacy Survey of Space and Time (LSST) will produce unprecedented volumes of heterogeneous astronomical data (images, catalogs, and alerts) that challenge traditional analysis pipelines. The LSST Dark Energy Science Collaboration (DESC) aims to derive robust constraints on dark energy and dark matter from these data, requiring methods that are statistically powerful, scalable, and operationally reliable. Artificial intelligence and machine learning (AI/ML) are already embedded across DESC science workflows, from photometric redshifts and transient classification to weak lensing inference and cosmological simulations. Yet their utility for precision cosmology hinges on trustworthy uncertainty quantification, robustness to covariate shift and model misspecification, and reproducible integration within scientific pipelines. This white paper surveys the current landscape of AI/ML across DESC's primary cosmological probes and cross-cutting analyses, revealing that the same core methodologies and fundamental challenges recur across disparate science cases. Since progress on these cross-cutting challenges would benefit multiple probes simultaneously, we identify key methodological research priorities, including Bayesian inference at scale, physics-informed methods, validation frameworks, and active learning for discovery. With an eye on emerging techniques, we also explore the potential of the latest foundation model methodologies and LLM-driven agentic AI systems to reshape DESC workflows, provided their deployment is coupled with rigorous evaluation and governance. Finally, we discuss critical software, computing, data infrastructure, and human capital requirements for the successful deployment of these new methodologies, and consider associated risks and opportunities for broader coordination with external actors.
TS-SNN: Temporal Shift Module for Spiking Neural Networks
May 08, 2025Spiking Neural Networks (SNNs) are increasingly recognized for their biological plausibility and energy efficiency, positioning them as strong alternatives to Artificial Neural Networks (ANNs) in neuromorphic computing applications. SNNs inherently process temporal information by leveraging the precise timing of spikes, but balancing temporal feature utilization with low energy consumption remains a challenge. In this work, we introduce Temporal Shift module for Spiking Neural Networks (TS-SNN), which incorporates a novel Temporal Shift (TS) module to integrate past, present, and future spike features within a single timestep via a simple yet effective shift operation. A residual combination method prevents information loss by integrating shifted and original features. The TS module is lightweight, requiring only one additional learnable parameter, and can be seamlessly integrated into existing architectures with minimal additional computational cost. TS-SNN achieves state-of-the-art performance on benchmarks like CIFAR-10 (96.72\%), CIFAR-100 (80.28\%), and ImageNet (70.61\%) with fewer timesteps, while maintaining low energy consumption. This work marks a significant step forward in developing efficient and accurate SNN architectures.
Head-Tail-Aware KL Divergence in Knowledge Distillation for Spiking Neural Networks
Apr 29, 2025Spiking Neural Networks (SNNs) have emerged as a promising approach for energy-efficient and biologically plausible computation. However, due to limitations in existing training methods and inherent model constraints, SNNs often exhibit a performance gap when compared to Artificial Neural Networks (ANNs). Knowledge distillation (KD) has been explored as a technique to transfer knowledge from ANN teacher models to SNN student models to mitigate this gap. Traditional KD methods typically use Kullback-Leibler (KL) divergence to align output distributions. However, conventional KL-based approaches fail to fully exploit the unique characteristics of SNNs, as they tend to overemphasize high-probability predictions while neglecting low-probability ones, leading to suboptimal generalization. To address this, we propose Head-Tail Aware Kullback-Leibler (HTA-KL) divergence, a novel KD method for SNNs. HTA-KL introduces a cumulative probability-based mask to dynamically distinguish between high- and low-probability regions. It assigns adaptive weights to ensure balanced knowledge transfer, enhancing the overall performance. By integrating forward KL (FKL) and reverse KL (RKL) divergence, our method effectively align both head and tail regions of the distribution. We evaluate our methods on CIFAR-10, CIFAR-100 and Tiny ImageNet datasets. Our method outperforms existing methods on most datasets with fewer timesteps.
EIoU-EMC: A Novel Loss for Domain-specific Nested Entity Recognition
Apr 19, 2025In recent years, research has mainly focused on the general NER task. There still have some challenges with nested NER task in the specific domains. Specifically, the scenarios of low resource and class imbalance impede the wide application for biomedical and industrial domains. In this study, we design a novel loss EIoU-EMC, by enhancing the implement of Intersection over Union loss and Multiclass loss. Our proposed method specially leverages the information of entity boundary and entity classification, thereby enhancing the model's capacity to learn from a limited number of data samples. To validate the performance of this innovative method in enhancing NER task, we conducted experiments on three distinct biomedical NER datasets and one dataset constructed by ourselves from industrial complex equipment maintenance documents. Comparing to strong baselines, our method demonstrates the competitive performance across all datasets. During the experimental analysis, our proposed method exhibits significant advancements in entity boundary recognition and entity classification. Our code are available here.
STAA-SNN: Spatial-Temporal Attention Aggregator for Spiking Neural Networks
Mar 05, 2025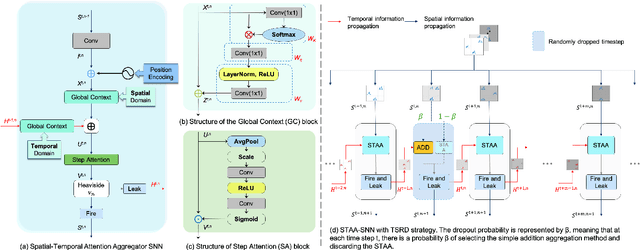
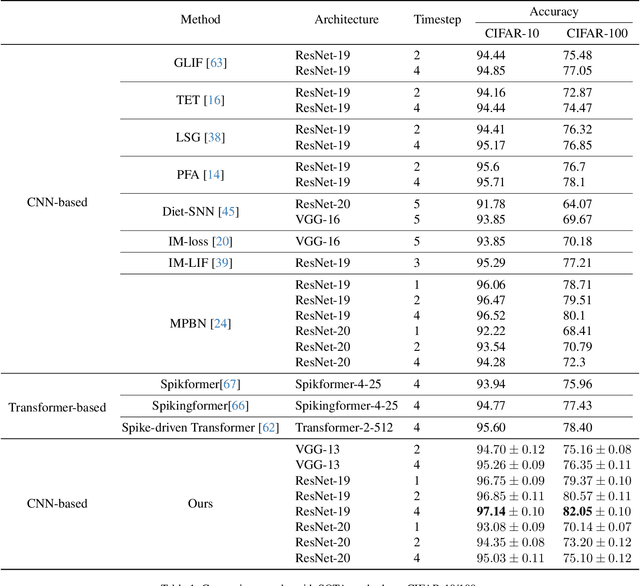
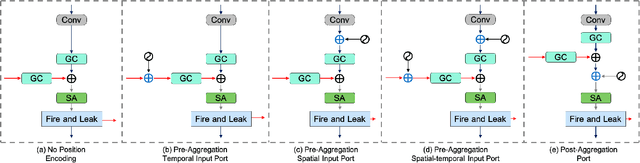
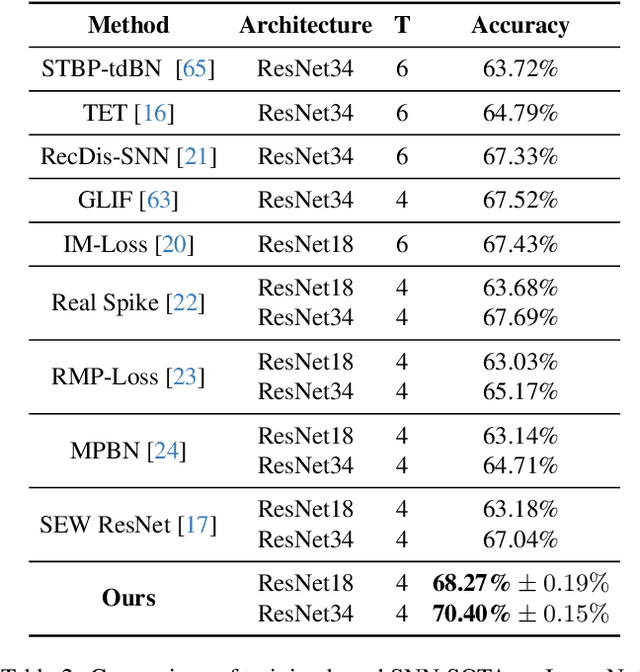
Spiking Neural Networks (SNNs) have gained significant attention due to their biological plausibility and energy efficiency, making them promising alternatives to Artificial Neural Networks (ANNs). However, the performance gap between SNNs and ANNs remains a substantial challenge hindering the widespread adoption of SNNs. In this paper, we propose a Spatial-Temporal Attention Aggregator SNN (STAA-SNN) framework, which dynamically focuses on and captures both spatial and temporal dependencies. First, we introduce a spike-driven self-attention mechanism specifically designed for SNNs. Additionally, we pioneeringly incorporate position encoding to integrate latent temporal relationships into the incoming features. For spatial-temporal information aggregation, we employ step attention to selectively amplify relevant features at different steps. Finally, we implement a time-step random dropout strategy to avoid local optima. As a result, STAA-SNN effectively captures both spatial and temporal dependencies, enabling the model to analyze complex patterns and make accurate predictions. The framework demonstrates exceptional performance across diverse datasets and exhibits strong generalization capabilities. Notably, STAA-SNN achieves state-of-the-art results on neuromorphic datasets CIFAR10-DVS, with remarkable performances of 97.14%, 82.05% and 70.40% on the static datasets CIFAR-10, CIFAR-100 and ImageNet, respectively. Furthermore, our model exhibits improved performance ranging from 0.33\% to 2.80\% with fewer time steps. The code for the model is available on GitHub.
Temporal Separation with Entropy Regularization for Knowledge Distillation in Spiking Neural Networks
Mar 05, 2025
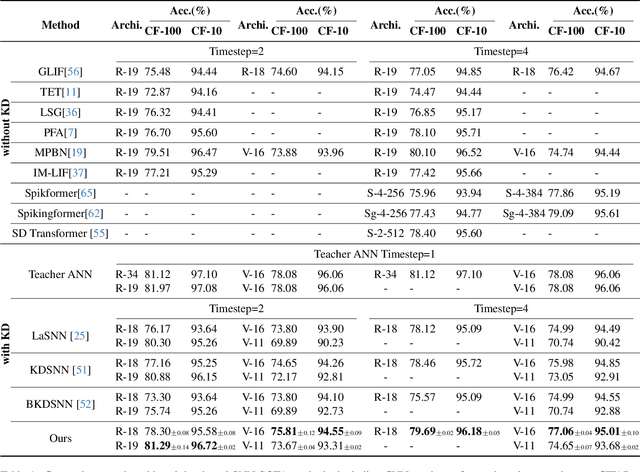


Spiking Neural Networks (SNNs), inspired by the human brain, offer significant computational efficiency through discrete spike-based information transfer. Despite their potential to reduce inference energy consumption, a performance gap persists between SNNs and Artificial Neural Networks (ANNs), primarily due to current training methods and inherent model limitations. While recent research has aimed to enhance SNN learning by employing knowledge distillation (KD) from ANN teacher networks, traditional distillation techniques often overlook the distinctive spatiotemporal properties of SNNs, thus failing to fully leverage their advantages. To overcome these challenge, we propose a novel logit distillation method characterized by temporal separation and entropy regularization. This approach improves existing SNN distillation techniques by performing distillation learning on logits across different time steps, rather than merely on aggregated output features. Furthermore, the integration of entropy regularization stabilizes model optimization and further boosts the performance. Extensive experimental results indicate that our method surpasses prior SNN distillation strategies, whether based on logit distillation, feature distillation, or a combination of both. The code will be available on GitHub.