 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRole-Playing Agents Driven by Large Language Models: Current Status, Challenges, and Future Trends
Jan 15, 2026In recent years, with the rapid advancement of large language models (LLMs), role-playing language agents (RPLAs) have emerged as a prominent research focus at the intersection of natural language processing (NLP) and human-computer interaction. This paper systematically reviews the current development and key technologies of RPLAs, delineating the technological evolution from early rule-based template paradigms, through the language style imitation stage, to the cognitive simulation stage centered on personality modeling and memory mechanisms. It summarizes the critical technical pathways supporting high-quality role-playing, including psychological scale-driven character modeling, memory-augmented prompting mechanisms, and motivation-situation-based behavioral decision control. At the data level, the paper further analyzes the methods and challenges of constructing role-specific corpora, focusing on data sources, copyright constraints, and structured annotation processes. In terms of evaluation, it collates multi-dimensional assessment frameworks and benchmark datasets covering role knowledge, personality fidelity, value alignment, and interactive hallucination, while commenting on the advantages and disadvantages of methods such as human evaluation, reward models, and LLM-based scoring. Finally, the paper outlines future development directions of role-playing agents, including personality evolution modeling, multi-agent collaborative narrative, multimodal immersive interaction, and integration with cognitive neuroscience, aiming to provide a systematic perspective and methodological insights for subsequent research.
PsyMem: Fine-grained psychological alignment and Explicit Memory Control for Advanced Role-Playing LLMs
May 19, 2025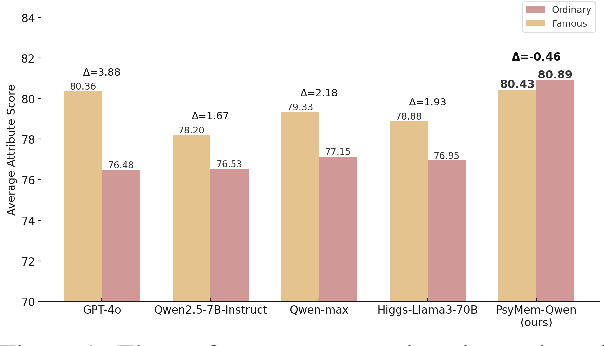
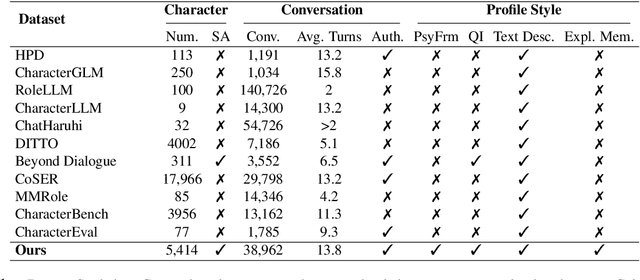
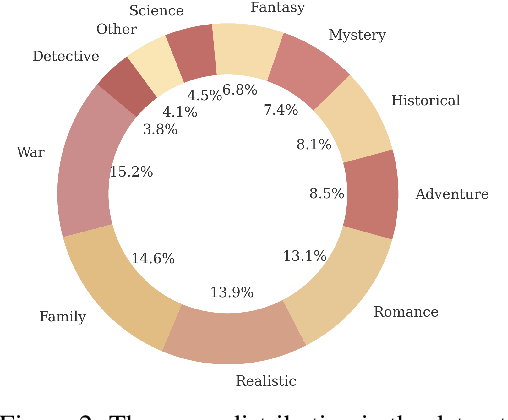
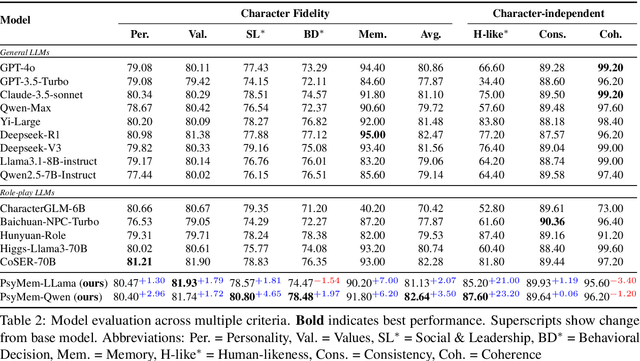
Existing LLM-based role-playing methods often rely on superficial textual descriptions or simplistic metrics, inadequately modeling both intrinsic and extrinsic character dimensions. Additionally, they typically simulate character memory with implicit model knowledge or basic retrieval augment generation without explicit memory alignment, compromising memory consistency. The two issues weaken reliability of role-playing LLMs in several applications, such as trustworthy social simulation. To address these limitations, we propose PsyMem, a novel framework integrating fine-grained psychological attributes and explicit memory control for role-playing. PsyMem supplements textual descriptions with 26 psychological indicators to detailed model character. Additionally, PsyMem implements memory alignment training, explicitly trains the model to align character's response with memory, thereby enabling dynamic memory-controlled responding during inference. By training Qwen2.5-7B-Instruct on our specially designed dataset (including 5,414 characters and 38,962 dialogues extracted from novels), the resulting model, termed as PsyMem-Qwen, outperforms baseline models in role-playing, achieving the best performance in human-likeness and character fidelity.
Stereo-Talker: Audio-driven 3D Human Synthesis with Prior-Guided Mixture-of-Experts
Oct 31, 2024



This paper introduces Stereo-Talker, a novel one-shot audio-driven human video synthesis system that generates 3D talking videos with precise lip synchronization, expressive body gestures, temporally consistent photo-realistic quality, and continuous viewpoint control. The process follows a two-stage approach. In the first stage, the system maps audio input to high-fidelity motion sequences, encompassing upper-body gestures and facial expressions. To enrich motion diversity and authenticity, large language model (LLM) priors are integrated with text-aligned semantic audio features, leveraging LLMs' cross-modal generalization power to enhance motion quality. In the second stage, we improve diffusion-based video generation models by incorporating a prior-guided Mixture-of-Experts (MoE) mechanism: a view-guided MoE focuses on view-specific attributes, while a mask-guided MoE enhances region-based rendering stability. Additionally, a mask prediction module is devised to derive human masks from motion data, enhancing the stability and accuracy of masks and enabling mask guiding during inference. We also introduce a comprehensive human video dataset with 2,203 identities, covering diverse body gestures and detailed annotations, facilitating broad generalization. The code, data, and pre-trained models will be released for research purposes.
Mimicking the Mavens: Agent-based Opinion Synthesis and Emotion Prediction for Social Media Influencers
Jul 30, 2024



Predicting influencers' views and public sentiment on social media is crucial for anticipating societal trends and guiding strategic responses. This study introduces a novel computational framework to predict opinion leaders' perspectives and the emotive reactions of the populace, addressing the inherent challenges posed by the unstructured, context-sensitive, and heterogeneous nature of online communication. Our research introduces an innovative module that starts with the automatic 5W1H (Where, Who, When, What, Why, and How) questions formulation engine, tailored to emerging news stories and trending topics. We then build a total of 60 anonymous opinion leader agents in six domains and realize the views generation based on an enhanced large language model (LLM) coupled with retrieval-augmented generation (RAG). Subsequently, we synthesize the potential views of opinion leaders and predicted the emotional responses to different events. The efficacy of our automated 5W1H module is corroborated by an average GPT-4 score of 8.83/10, indicative of high fidelity. The influencer agents exhibit a consistent performance, achieving an average GPT-4 rating of 6.85/10 across evaluative metrics. Utilizing the 'Russia-Ukraine War' as a case study, our methodology accurately foresees key influencers' perspectives and aligns emotional predictions with real-world sentiment trends in various domains.
MonoGaussianAvatar: Monocular Gaussian Point-based Head Avatar
Dec 07, 2023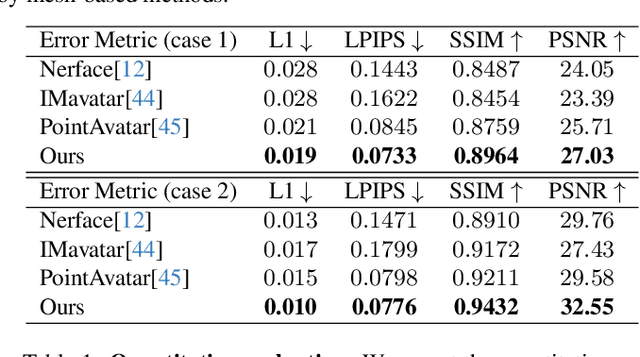
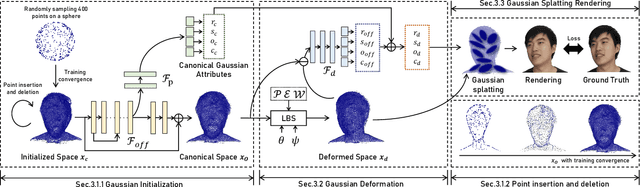
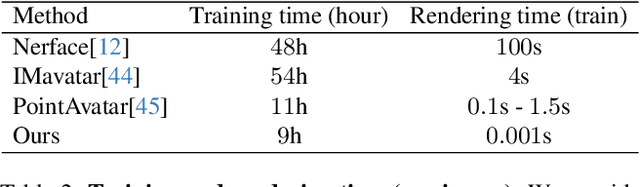
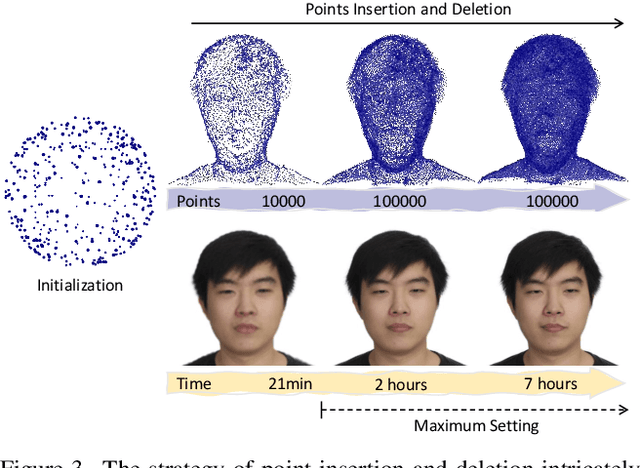
The ability to animate photo-realistic head avatars reconstructed from monocular portrait video sequences represents a crucial step in bridging the gap between the virtual and real worlds. Recent advancements in head avatar techniques, including explicit 3D morphable meshes (3DMM), point clouds, and neural implicit representation have been exploited for this ongoing research. However, 3DMM-based methods are constrained by their fixed topologies, point-based approaches suffer from a heavy training burden due to the extensive quantity of points involved, and the last ones suffer from limitations in deformation flexibility and rendering efficiency. In response to these challenges, we propose MonoGaussianAvatar (Monocular Gaussian Point-based Head Avatar), a novel approach that harnesses 3D Gaussian point representation coupled with a Gaussian deformation field to learn explicit head avatars from monocular portrait videos. We define our head avatars with Gaussian points characterized by adaptable shapes, enabling flexible topology. These points exhibit movement with a Gaussian deformation field in alignment with the target pose and expression of a person, facilitating efficient deformation. Additionally, the Gaussian points have controllable shape, size, color, and opacity combined with Gaussian splatting, allowing for efficient training and rendering. Experiments demonstrate the superior performance of our method, which achieves state-of-the-art results among previous methods.