 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
Jun 11, 2025Holistic 3D scene understanding, which jointly models geometry, appearance, and semantics, is crucial for applications like augmented reality and robotic interaction. Existing feed-forward 3D scene understanding methods (e.g., LSM) are limited to extracting language-based semantics from scenes, failing to achieve holistic scene comprehension. Additionally, they suffer from low-quality geometry reconstruction and noisy artifacts. In contrast, per-scene optimization methods rely on dense input views, which reduces practicality and increases complexity during deployment. In this paper, we propose SemanticSplat, a feed-forward semantic-aware 3D reconstruction method, which unifies 3D Gaussians with latent semantic attributes for joint geometry-appearance-semantics modeling. To predict the semantic anisotropic Gaussians, SemanticSplat fuses diverse feature fields (e.g., LSeg, SAM) with a cost volume representation that stores cross-view feature similarities, enhancing coherent and accurate scene comprehension. Leveraging a two-stage distillation framework, SemanticSplat reconstructs a holistic multi-modal semantic feature field from sparse-view images. Experiments demonstrate the effectiveness of our method for 3D scene understanding tasks like promptable and open-vocabulary segmentation. Video results are available at https://semanticsplat.github.io.
MonoGaussianAvatar: Monocular Gaussian Point-based Head Avatar
Dec 07, 2023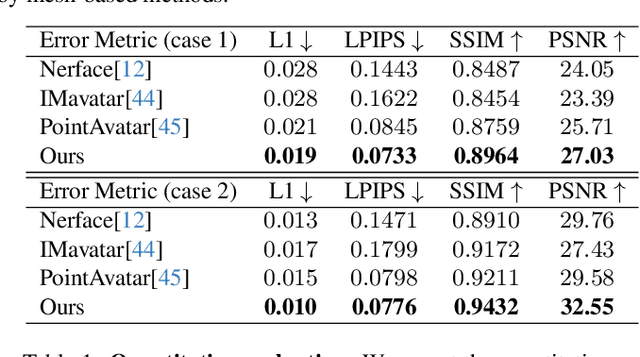
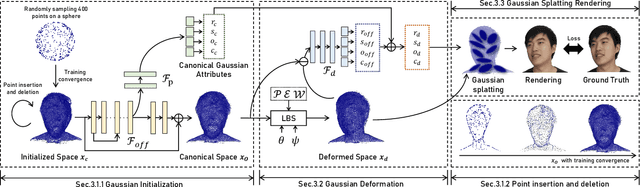
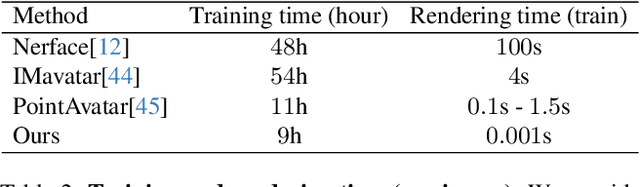
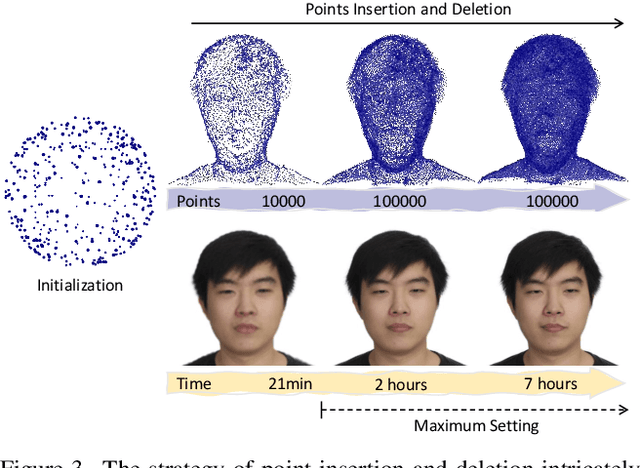
The ability to animate photo-realistic head avatars reconstructed from monocular portrait video sequences represents a crucial step in bridging the gap between the virtual and real worlds. Recent advancements in head avatar techniques, including explicit 3D morphable meshes (3DMM), point clouds, and neural implicit representation have been exploited for this ongoing research. However, 3DMM-based methods are constrained by their fixed topologies, point-based approaches suffer from a heavy training burden due to the extensive quantity of points involved, and the last ones suffer from limitations in deformation flexibility and rendering efficiency. In response to these challenges, we propose MonoGaussianAvatar (Monocular Gaussian Point-based Head Avatar), a novel approach that harnesses 3D Gaussian point representation coupled with a Gaussian deformation field to learn explicit head avatars from monocular portrait videos. We define our head avatars with Gaussian points characterized by adaptable shapes, enabling flexible topology. These points exhibit movement with a Gaussian deformation field in alignment with the target pose and expression of a person, facilitating efficient deformation. Additionally, the Gaussian points have controllable shape, size, color, and opacity combined with Gaussian splatting, allowing for efficient training and rendering. Experiments demonstrate the superior performance of our method, which achieves state-of-the-art results among previous methods.