 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
DreamActor-H1: High-Fidelity Human-Product Demonstration Video Generation via Motion-designed Diffusion Transformers
Jun 12, 2025In e-commerce and digital marketing, generating high-fidelity human-product demonstration videos is important for effective product presentation. However, most existing frameworks either fail to preserve the identities of both humans and products or lack an understanding of human-product spatial relationships, leading to unrealistic representations and unnatural interactions. To address these challenges, we propose a Diffusion Transformer (DiT)-based framework. Our method simultaneously preserves human identities and product-specific details, such as logos and textures, by injecting paired human-product reference information and utilizing an additional masked cross-attention mechanism. We employ a 3D body mesh template and product bounding boxes to provide precise motion guidance, enabling intuitive alignment of hand gestures with product placements. Additionally, structured text encoding is used to incorporate category-level semantics, enhancing 3D consistency during small rotational changes across frames. Trained on a hybrid dataset with extensive data augmentation strategies, our approach outperforms state-of-the-art techniques in maintaining the identity integrity of both humans and products and generating realistic demonstration motions. Project page: https://submit2025-dream.github.io/DreamActor-H1/.
DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance
Apr 03, 2025While recent image-based human animation methods achieve realistic body and facial motion synthesis, critical gaps remain in fine-grained holistic controllability, multi-scale adaptability, and long-term temporal coherence, which leads to their lower expressiveness and robustness. We propose a diffusion transformer (DiT) based framework, DreamActor-M1, with hybrid guidance to overcome these limitations. For motion guidance, our hybrid control signals that integrate implicit facial representations, 3D head spheres, and 3D body skeletons achieve robust control of facial expressions and body movements, while producing expressive and identity-preserving animations. For scale adaptation, to handle various body poses and image scales ranging from portraits to full-body views, we employ a progressive training strategy using data with varying resolutions and scales. For appearance guidance, we integrate motion patterns from sequential frames with complementary visual references, ensuring long-term temporal coherence for unseen regions during complex movements. Experiments demonstrate that our method outperforms the state-of-the-art works, delivering expressive results for portraits, upper-body, and full-body generation with robust long-term consistency. Project Page: https://grisoon.github.io/DreamActor-M1/.
Stereo-Talker: Audio-driven 3D Human Synthesis with Prior-Guided Mixture-of-Experts
Oct 31, 2024



This paper introduces Stereo-Talker, a novel one-shot audio-driven human video synthesis system that generates 3D talking videos with precise lip synchronization, expressive body gestures, temporally consistent photo-realistic quality, and continuous viewpoint control. The process follows a two-stage approach. In the first stage, the system maps audio input to high-fidelity motion sequences, encompassing upper-body gestures and facial expressions. To enrich motion diversity and authenticity, large language model (LLM) priors are integrated with text-aligned semantic audio features, leveraging LLMs' cross-modal generalization power to enhance motion quality. In the second stage, we improve diffusion-based video generation models by incorporating a prior-guided Mixture-of-Experts (MoE) mechanism: a view-guided MoE focuses on view-specific attributes, while a mask-guided MoE enhances region-based rendering stability. Additionally, a mask prediction module is devised to derive human masks from motion data, enhancing the stability and accuracy of masks and enabling mask guiding during inference. We also introduce a comprehensive human video dataset with 2,203 identities, covering diverse body gestures and detailed annotations, facilitating broad generalization. The code, data, and pre-trained models will be released for research purposes.
3D Gaussian Parametric Head Model
Jul 21, 2024



Creating high-fidelity 3D human head avatars is crucial for applications in VR/AR, telepresence, digital human interfaces, and film production. Recent advances have leveraged morphable face models to generate animated head avatars from easily accessible data, representing varying identities and expressions within a low-dimensional parametric space. However, existing methods often struggle with modeling complex appearance details, e.g., hairstyles and accessories, and suffer from low rendering quality and efficiency. This paper introduces a novel approach, 3D Gaussian Parametric Head Model, which employs 3D Gaussians to accurately represent the complexities of the human head, allowing precise control over both identity and expression. Additionally, it enables seamless face portrait interpolation and the reconstruction of detailed head avatars from a single image. Unlike previous methods, the Gaussian model can handle intricate details, enabling realistic representations of varying appearances and complex expressions. Furthermore, this paper presents a well-designed training framework to ensure smooth convergence, providing a guarantee for learning the rich content. Our method achieves high-quality, photo-realistic rendering with real-time efficiency, making it a valuable contribution to the field of parametric head models.
GMTalker: Gaussian Mixture based Emotional talking video Portraits
Dec 12, 2023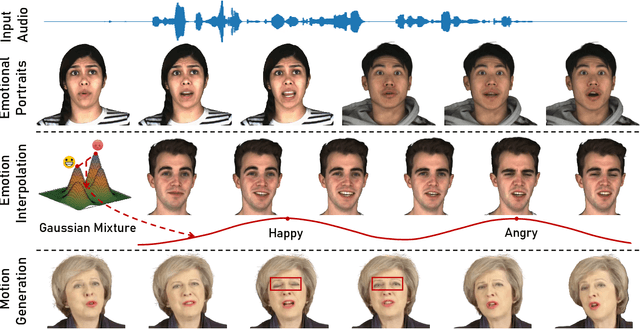
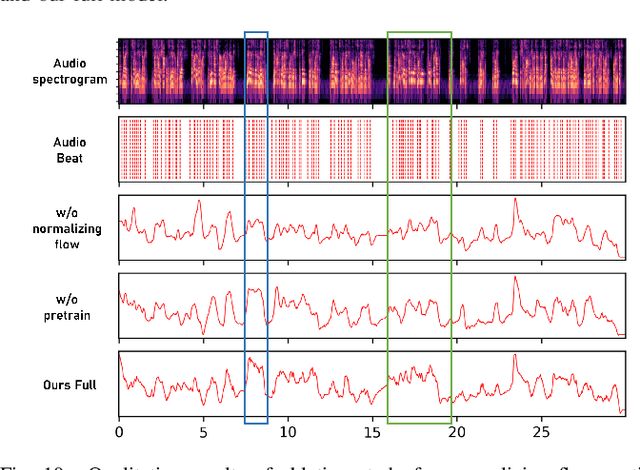

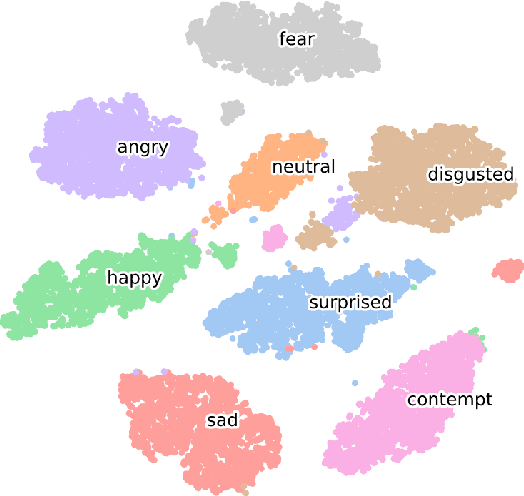
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expression, realistic head pose, and eye blink, is an important and challenging task in recent years. Most of the existing methods suffer in achieving personalized precise emotion control or continuously interpolating between different emotions and generating diverse motion. To address these problems, we present GMTalker, a Gaussian mixture based emotional talking portraits generation framework. Specifically, we propose a Gaussian Mixture based Expression Generator (GMEG) which can construct a continuous and multi-modal latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow based motion generator pretrained on the dataset with a wide-range motion to generate diverse motions. Finally, we propose a personalized emotion-guided head generator with an Emotion Mapping Network (EMN) which can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy and motion diversity.
MonoGaussianAvatar: Monocular Gaussian Point-based Head Avatar
Dec 07, 2023
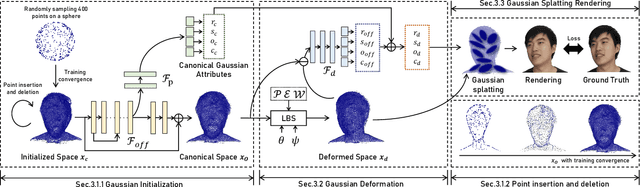
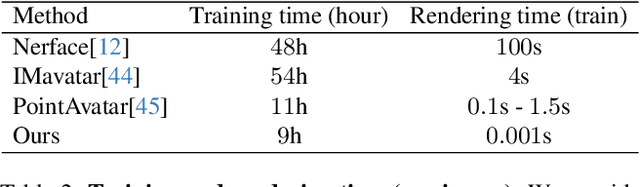
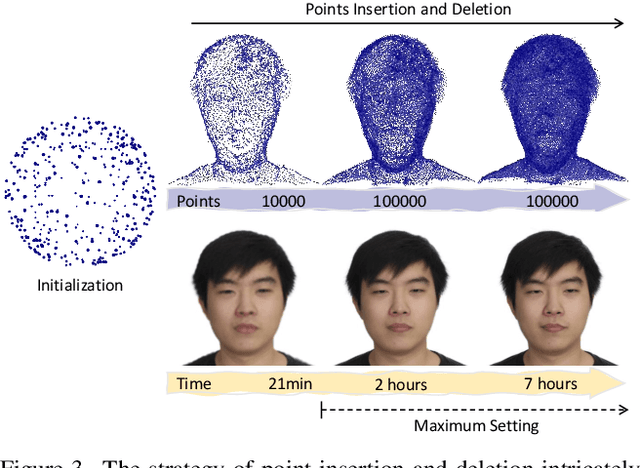
The ability to animate photo-realistic head avatars reconstructed from monocular portrait video sequences represents a crucial step in bridging the gap between the virtual and real worlds. Recent advancements in head avatar techniques, including explicit 3D morphable meshes (3DMM), point clouds, and neural implicit representation have been exploited for this ongoing research. However, 3DMM-based methods are constrained by their fixed topologies, point-based approaches suffer from a heavy training burden due to the extensive quantity of points involved, and the last ones suffer from limitations in deformation flexibility and rendering efficiency. In response to these challenges, we propose MonoGaussianAvatar (Monocular Gaussian Point-based Head Avatar), a novel approach that harnesses 3D Gaussian point representation coupled with a Gaussian deformation field to learn explicit head avatars from monocular portrait videos. We define our head avatars with Gaussian points characterized by adaptable shapes, enabling flexible topology. These points exhibit movement with a Gaussian deformation field in alignment with the target pose and expression of a person, facilitating efficient deformation. Additionally, the Gaussian points have controllable shape, size, color, and opacity combined with Gaussian splatting, allowing for efficient training and rendering. Experiments demonstrate the superior performance of our method, which achieves state-of-the-art results among previous methods.
Gaussian Head Avatar: Ultra High-fidelity Head Avatar via Dynamic Gaussians
Dec 05, 2023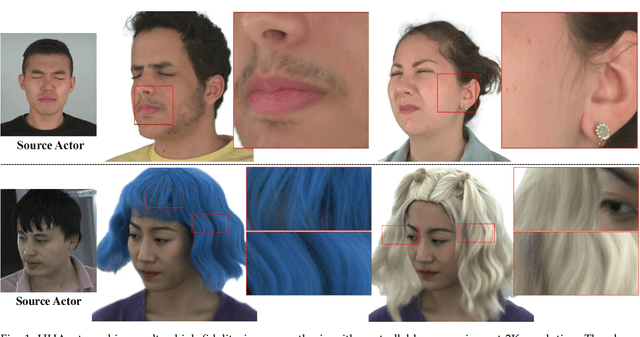

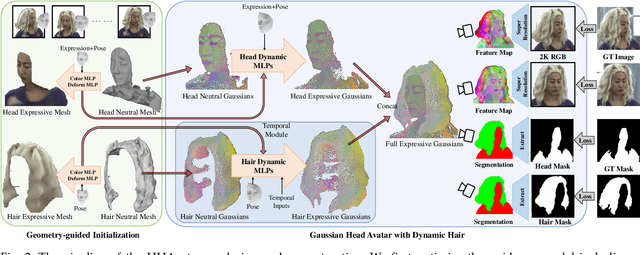
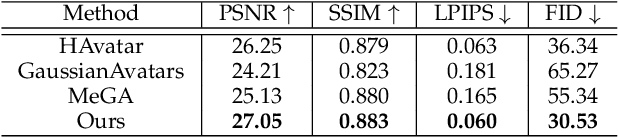
Creating high-fidelity 3D head avatars has always been a research hotspot, but there remains a great challenge under lightweight sparse view setups. In this paper, we propose Gaussian Head Avatar represented by controllable 3D Gaussians for high-fidelity head avatar modeling. We optimize the neutral 3D Gaussians and a fully learned MLP-based deformation field to capture complex expressions. The two parts benefit each other, thereby our method can model fine-grained dynamic details while ensuring expression accuracy. Furthermore, we devise a well-designed geometry-guided initialization strategy based on implicit SDF and Deep Marching Tetrahedra for the stability and convergence of the training procedure. Experiments show our approach outperforms other state-of-the-art sparse-view methods, achieving ultra high-fidelity rendering quality at 2K resolution even under exaggerated expressions.
InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars
Dec 03, 2023While high fidelity and efficiency are central to the creation of digital head avatars, recent methods relying on 2D or 3D generative models often experience limitations such as shape distortion, expression inaccuracy, and identity flickering. Additionally, existing one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction. We propose a novel framework, \textbf{Incremental 3D GAN Inversion}, that enhances avatar reconstruction performance using an algorithm designed to increase the fidelity from multiple frames, resulting in improved reconstruction quality proportional to frame count. Our method introduces a unique animatable 3D GAN prior with two crucial modifications for enhanced expression controllability alongside an innovative neural texture encoder that categorizes texture feature spaces based on UV parameterization. Differentiating from traditional techniques, our architecture emphasizes pixel-aligned image-to-image translation, mitigating the need to learn correspondences between observation and canonical spaces. Furthermore, we incorporate ConvGRU-based recurrent networks for temporal data aggregation from multiple frames, boosting geometry and texture detail reconstruction. The proposed paradigm demonstrates state-of-the-art performance on one-shot and few-shot avatar animation tasks.
Animatable Gaussians: Learning Pose-dependent Gaussian Maps for High-fidelity Human Avatar Modeling
Nov 27, 2023


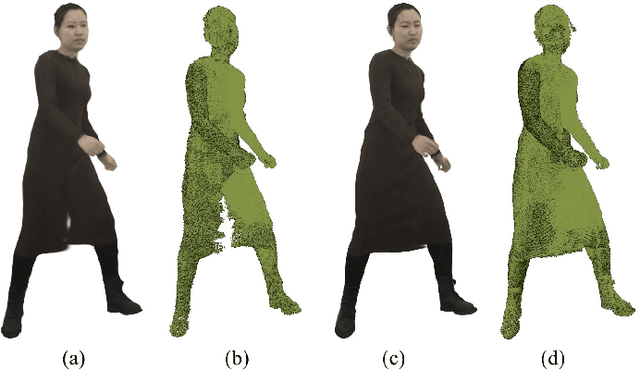
Modeling animatable human avatars from RGB videos is a long-standing and challenging problem. Recent works usually adopt MLP-based neural radiance fields (NeRF) to represent 3D humans, but it remains difficult for pure MLPs to regress pose-dependent garment details. To this end, we introduce Animatable Gaussians, a new avatar representation that leverages powerful 2D CNNs and 3D Gaussian splatting to create high-fidelity avatars. To associate 3D Gaussians with the animatable avatar, we learn a parametric template from the input videos, and then parameterize the template on two front \& back canonical Gaussian maps where each pixel represents a 3D Gaussian. The learned template is adaptive to the wearing garments for modeling looser clothes like dresses. Such template-guided 2D parameterization enables us to employ a powerful StyleGAN-based CNN to learn the pose-dependent Gaussian maps for modeling detailed dynamic appearances. Furthermore, we introduce a pose projection strategy for better generalization given novel poses. Overall, our method can create lifelike avatars with dynamic, realistic and generalized appearances. Experiments show that our method outperforms other state-of-the-art approaches. Code: https://github.com/lizhe00/AnimatableGaussians