 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamActor-M2: Universal Character Image Animation via Spatiotemporal In-Context Learning
Jan 29, 2026Character image animation aims to synthesize high-fidelity videos by transferring motion from a driving sequence to a static reference image. Despite recent advancements, existing methods suffer from two fundamental challenges: (1) suboptimal motion injection strategies that lead to a trade-off between identity preservation and motion consistency, manifesting as a "see-saw", and (2) an over-reliance on explicit pose priors (e.g., skeletons), which inadequately capture intricate dynamics and hinder generalization to arbitrary, non-humanoid characters. To address these challenges, we present DreamActor-M2, a universal animation framework that reimagines motion conditioning as an in-context learning problem. Our approach follows a two-stage paradigm. First, we bridge the input modality gap by fusing reference appearance and motion cues into a unified latent space, enabling the model to jointly reason about spatial identity and temporal dynamics by leveraging the generative prior of foundational models. Second, we introduce a self-bootstrapped data synthesis pipeline that curates pseudo cross-identity training pairs, facilitating a seamless transition from pose-dependent control to direct, end-to-end RGB-driven animation. This strategy significantly enhances generalization across diverse characters and motion scenarios. To facilitate comprehensive evaluation, we further introduce AW Bench, a versatile benchmark encompassing a wide spectrum of characters types and motion scenarios. Extensive experiments demonstrate that DreamActor-M2 achieves state-of-the-art performance, delivering superior visual fidelity and robust cross-domain generalization. Project Page: https://grisoon.github.io/DreamActor-M2/
FlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
Bridging Your Imagination with Audio-Video Generation via a Unified Director
Dec 29, 2025Existing AI-driven video creation systems typically treat script drafting and key-shot design as two disjoint tasks: the former relies on large language models, while the latter depends on image generation models. We argue that these two tasks should be unified within a single framework, as logical reasoning and imaginative thinking are both fundamental qualities of a film director. In this work, we propose UniMAGE, a unified director model that bridges user prompts with well-structured scripts, thereby empowering non-experts to produce long-context, multi-shot films by leveraging existing audio-video generation models. To achieve this, we employ the Mixture-of-Transformers architecture that unifies text and image generation. To further enhance narrative logic and keyframe consistency, we introduce a ``first interleaving, then disentangling'' training paradigm. Specifically, we first perform Interleaved Concept Learning, which utilizes interleaved text-image data to foster the model's deeper understanding and imaginative interpretation of scripts. We then conduct Disentangled Expert Learning, which decouples script writing from keyframe generation, enabling greater flexibility and creativity in storytelling. Extensive experiments demonstrate that UniMAGE achieves state-of-the-art performance among open-source models, generating logically coherent video scripts and visually consistent keyframe images.
DreamActor-H1: High-Fidelity Human-Product Demonstration Video Generation via Motion-designed Diffusion Transformers
Jun 12, 2025In e-commerce and digital marketing, generating high-fidelity human-product demonstration videos is important for effective product presentation. However, most existing frameworks either fail to preserve the identities of both humans and products or lack an understanding of human-product spatial relationships, leading to unrealistic representations and unnatural interactions. To address these challenges, we propose a Diffusion Transformer (DiT)-based framework. Our method simultaneously preserves human identities and product-specific details, such as logos and textures, by injecting paired human-product reference information and utilizing an additional masked cross-attention mechanism. We employ a 3D body mesh template and product bounding boxes to provide precise motion guidance, enabling intuitive alignment of hand gestures with product placements. Additionally, structured text encoding is used to incorporate category-level semantics, enhancing 3D consistency during small rotational changes across frames. Trained on a hybrid dataset with extensive data augmentation strategies, our approach outperforms state-of-the-art techniques in maintaining the identity integrity of both humans and products and generating realistic demonstration motions. Project page: https://submit2025-dream.github.io/DreamActor-H1/.
DreamActor-M1: Holistic, Expressive and Robust Human Image Animation with Hybrid Guidance
Apr 03, 2025While recent image-based human animation methods achieve realistic body and facial motion synthesis, critical gaps remain in fine-grained holistic controllability, multi-scale adaptability, and long-term temporal coherence, which leads to their lower expressiveness and robustness. We propose a diffusion transformer (DiT) based framework, DreamActor-M1, with hybrid guidance to overcome these limitations. For motion guidance, our hybrid control signals that integrate implicit facial representations, 3D head spheres, and 3D body skeletons achieve robust control of facial expressions and body movements, while producing expressive and identity-preserving animations. For scale adaptation, to handle various body poses and image scales ranging from portraits to full-body views, we employ a progressive training strategy using data with varying resolutions and scales. For appearance guidance, we integrate motion patterns from sequential frames with complementary visual references, ensuring long-term temporal coherence for unseen regions during complex movements. Experiments demonstrate that our method outperforms the state-of-the-art works, delivering expressive results for portraits, upper-body, and full-body generation with robust long-term consistency. Project Page: https://grisoon.github.io/DreamActor-M1/.
INFP: Audio-Driven Interactive Head Generation in Dyadic Conversations
Dec 05, 2024Imagine having a conversation with a socially intelligent agent. It can attentively listen to your words and offer visual and linguistic feedback promptly. This seamless interaction allows for multiple rounds of conversation to flow smoothly and naturally. In pursuit of actualizing it, we propose INFP, a novel audio-driven head generation framework for dyadic interaction. Unlike previous head generation works that only focus on single-sided communication, or require manual role assignment and explicit role switching, our model drives the agent portrait dynamically alternates between speaking and listening state, guided by the input dyadic audio. Specifically, INFP comprises a Motion-Based Head Imitation stage and an Audio-Guided Motion Generation stage. The first stage learns to project facial communicative behaviors from real-life conversation videos into a low-dimensional motion latent space, and use the motion latent codes to animate a static image. The second stage learns the mapping from the input dyadic audio to motion latent codes through denoising, leading to the audio-driven head generation in interactive scenarios. To facilitate this line of research, we introduce DyConv, a large scale dataset of rich dyadic conversations collected from the Internet. Extensive experiments and visualizations demonstrate superior performance and effectiveness of our method. Project Page: https://grisoon.github.io/INFP/.
PersonaTalk: Bring Attention to Your Persona in Visual Dubbing
Sep 09, 2024



For audio-driven visual dubbing, it remains a considerable challenge to uphold and highlight speaker's persona while synthesizing accurate lip synchronization. Existing methods fall short of capturing speaker's unique speaking style or preserving facial details. In this paper, we present PersonaTalk, an attention-based two-stage framework, including geometry construction and face rendering, for high-fidelity and personalized visual dubbing. In the first stage, we propose a style-aware audio encoding module that injects speaking style into audio features through a cross-attention layer. The stylized audio features are then used to drive speaker's template geometry to obtain lip-synced geometries. In the second stage, a dual-attention face renderer is introduced to render textures for the target geometries. It consists of two parallel cross-attention layers, namely Lip-Attention and Face-Attention, which respectively sample textures from different reference frames to render the entire face. With our innovative design, intricate facial details can be well preserved. Comprehensive experiments and user studies demonstrate our advantages over other state-of-the-art methods in terms of visual quality, lip-sync accuracy and persona preservation. Furthermore, as a person-generic framework, PersonaTalk can achieve competitive performance as state-of-the-art person-specific methods. Project Page: https://grisoon.github.io/PersonaTalk/.
Building an Invisible Shield for Your Portrait against Deepfakes
May 22, 2023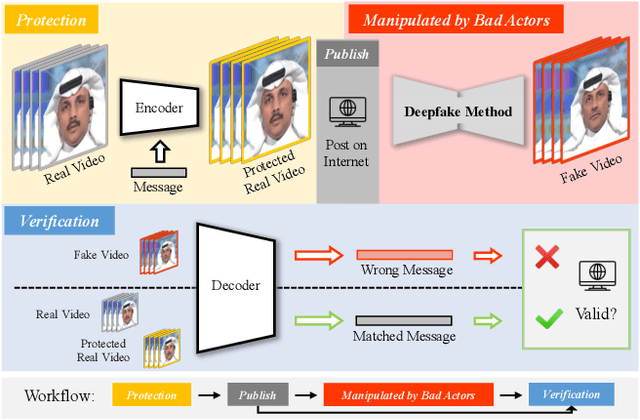



The issue of detecting deepfakes has garnered significant attention in the research community, with the goal of identifying facial manipulations for abuse prevention. Although recent studies have focused on developing generalized models that can detect various types of deepfakes, their performance is not always be reliable and stable, which poses limitations in real-world applications. Instead of learning a forgery detector, in this paper, we propose a novel framework - Integrity Encryptor, aiming to protect portraits in a proactive strategy. Our methodology involves covertly encoding messages that are closely associated with key facial attributes into authentic images prior to their public release. Unlike authentic images, where the hidden messages can be extracted with precision, manipulating the facial attributes through deepfake techniques can disrupt the decoding process. Consequently, the modified facial attributes serve as a mean of detecting manipulated images through a comparison of the decoded messages. Our encryption approach is characterized by its brevity and efficiency, and the resulting method exhibits a good robustness against typical image processing traces, such as image degradation and noise. When compared to baselines that struggle to detect deepfakes in a black-box setting, our method utilizing conditional encryption showcases superior performance when presented with a range of different types of forgeries. In experiments conducted on our protected data, our approach outperforms existing state-of-the-art methods by a significant margin.
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator
May 09, 2023



Despite recent advances in syncing lip movements with any audio waves, current methods still struggle to balance generation quality and the model's generalization ability. Previous studies either require long-term data for training or produce a similar movement pattern on all subjects with low quality. In this paper, we propose StyleSync, an effective framework that enables high-fidelity lip synchronization. We identify that a style-based generator would sufficiently enable such a charming property on both one-shot and few-shot scenarios. Specifically, we design a mask-guided spatial information encoding module that preserves the details of the given face. The mouth shapes are accurately modified by audio through modulated convolutions. Moreover, our design also enables personalized lip-sync by introducing style space and generator refinement on only limited frames. Thus the identity and talking style of a target person could be accurately preserved. Extensive experiments demonstrate the effectiveness of our method in producing high-fidelity results on a variety of scenes. Resources can be found at https://hangz-nju-cuhk.github.io/projects/StyleSync.
Delicate Textured Mesh Recovery from NeRF via Adaptive Surface Refinement
Mar 03, 2023



Neural Radiance Fields (NeRF) have constituted a remarkable breakthrough in image-based 3D reconstruction. However, their implicit volumetric representations differ significantly from the widely-adopted polygonal meshes and lack support from common 3D software and hardware, making their rendering and manipulation inefficient. To overcome this limitation, we present a novel framework that generates textured surface meshes from images. Our approach begins by efficiently initializing the geometry and view-dependency decomposed appearance with a NeRF. Subsequently, a coarse mesh is extracted, and an iterative surface refining algorithm is developed to adaptively adjust both vertex positions and face density based on re-projected rendering errors. We jointly refine the appearance with geometry and bake it into texture images for real-time rendering. Extensive experiments demonstrate that our method achieves superior mesh quality and competitive rendering quality.