 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Computers
Apr 07, 2026We propose a new frontier: Neural Computers (NCs) -- an emerging machine form that unifies computation, memory, and I/O in a learned runtime state. Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. Our long-term goal is the Completely Neural Computer (CNC): the mature, general-purpose realization of this emerging machine form, with stable execution, explicit reprogramming, and durable capability reuse. As an initial step, we study whether early NC primitives can be learned solely from collected I/O traces, without instrumented program state. Concretely, we instantiate NCs as video models that roll out screen frames from instructions, pixels, and user actions (when available) in CLI and GUI settings. These implementations show that learned runtimes can acquire early interface primitives, especially I/O alignment and short-horizon control, while routine reuse, controlled updates, and symbolic stability remain open. We outline a roadmap toward CNCs around these challenges. If overcome, CNCs could establish a new computing paradigm beyond today's agents, world models, and conventional computers.
OneLatent: Single-Token Compression for Visual Latent Reasoning
Feb 14, 2026Chain-of-thought (CoT) prompting improves reasoning but often increases inference cost by one to two orders of magnitude. To address these challenges, we present \textbf{OneLatent}, a framework that compresses intermediate reasoning into a single latent token via supervision from rendered CoT images and DeepSeek-OCR hidden states. By rendering textual steps into images, we obtain a deterministic supervision signal that can be inspected and audited without requiring the model to output verbose textual rationales. Across benchmarks, OneLatent reduces average output length by $11\times$ with only a $2.21\%$ average accuracy drop relative to textual CoT, while improving output token contribution (OTC) by $6.8\times$. On long-chain logical reasoning, OneLatent reaches $99.80\%$ on ProntoQA and $97.80\%$ on ProsQA with one latent token, with compression up to $87.4\times$, supporting compression-constrained generalization.
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025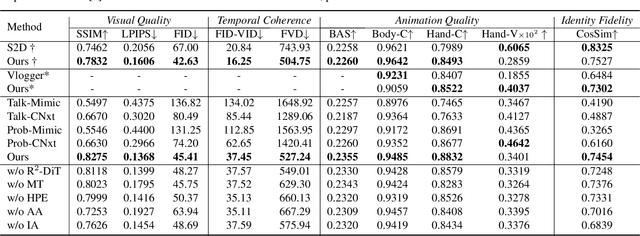
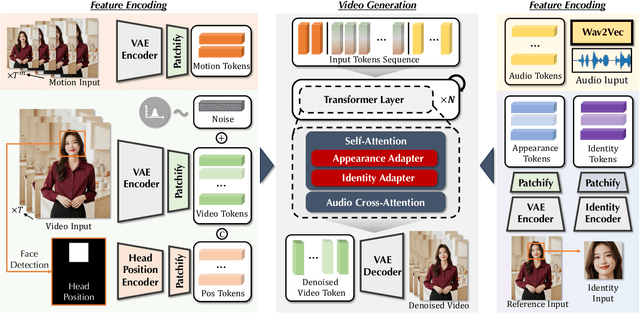
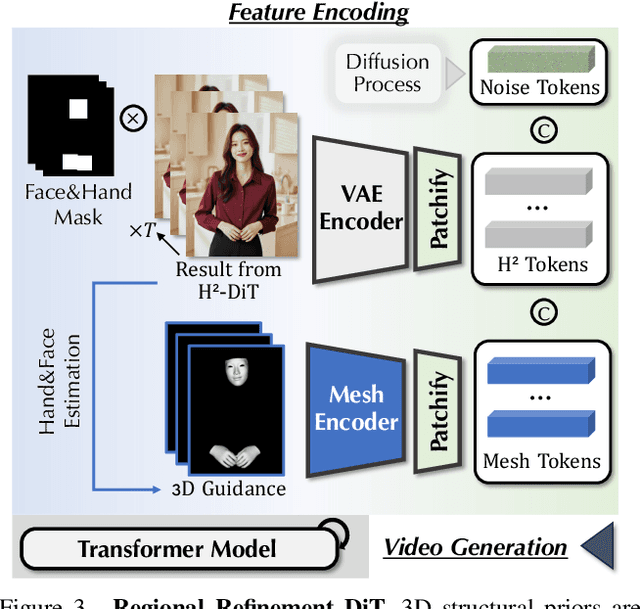

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
Cosh-DiT: Co-Speech Gesture Video Synthesis via Hybrid Audio-Visual Diffusion Transformers
Mar 13, 2025Co-speech gesture video synthesis is a challenging task that requires both probabilistic modeling of human gestures and the synthesis of realistic images that align with the rhythmic nuances of speech. To address these challenges, we propose Cosh-DiT, a Co-speech gesture video system with hybrid Diffusion Transformers that perform audio-to-motion and motion-to-video synthesis using discrete and continuous diffusion modeling, respectively. First, we introduce an audio Diffusion Transformer (Cosh-DiT-A) to synthesize expressive gesture dynamics synchronized with speech rhythms. To capture upper body, facial, and hand movement priors, we employ vector-quantized variational autoencoders (VQ-VAEs) to jointly learn their dependencies within a discrete latent space. Then, for realistic video synthesis conditioned on the generated speech-driven motion, we design a visual Diffusion Transformer (Cosh-DiT-V) that effectively integrates spatial and temporal contexts. Extensive experiments demonstrate that our framework consistently generates lifelike videos with expressive facial expressions and natural, smooth gestures that align seamlessly with speech.
OccScene: Semantic Occupancy-based Cross-task Mutual Learning for 3D Scene Generation
Dec 15, 2024



Recent diffusion models have demonstrated remarkable performance in both 3D scene generation and perception tasks. Nevertheless, existing methods typically separate these two processes, acting as a data augmenter to generate synthetic data for downstream perception tasks. In this work, we propose OccScene, a novel mutual learning paradigm that integrates fine-grained 3D perception and high-quality generation in a unified framework, achieving a cross-task win-win effect. OccScene generates new and consistent 3D realistic scenes only depending on text prompts, guided with semantic occupancy in a joint-training diffusion framework. To align the occupancy with the diffusion latent, a Mamba-based Dual Alignment module is introduced to incorporate fine-grained semantics and geometry as perception priors. Within OccScene, the perception module can be effectively improved with customized and diverse generated scenes, while the perception priors in return enhance the generation performance for mutual benefits. Extensive experiments show that OccScene achieves realistic 3D scene generation in broad indoor and outdoor scenarios, while concurrently boosting the perception models to achieve substantial performance improvements in the 3D perception task of semantic occupancy prediction.
Hierarchical Context Alignment with Disentangled Geometric and Temporal Modeling for Semantic Occupancy Prediction
Dec 11, 2024



Camera-based 3D Semantic Occupancy Prediction (SOP) is crucial for understanding complex 3D scenes from limited 2D image observations. Existing SOP methods typically aggregate contextual features to assist the occupancy representation learning, alleviating issues like occlusion or ambiguity. However, these solutions often face misalignment issues wherein the corresponding features at the same position across different frames may have different semantic meanings during the aggregation process, which leads to unreliable contextual fusion results and an unstable representation learning process. To address this problem, we introduce a new Hierarchical context alignment paradigm for a more accurate SOP (Hi-SOP). Hi-SOP first disentangles the geometric and temporal context for separate alignment, which two branches are then composed to enhance the reliability of SOP. This parsing of the visual input into a local-global alignment hierarchy includes: (I) disentangled geometric and temporal separate alignment, within each leverages depth confidence and camera pose as prior for relevant feature matching respectively; (II) global alignment and composition of the transformed geometric and temporal volumes based on semantics consistency. Our method outperforms SOTAs for semantic scene completion on the SemanticKITTI & NuScenes-Occupancy datasets and LiDAR semantic segmentation on the NuScenes dataset.
AVI-Talking: Learning Audio-Visual Instructions for Expressive 3D Talking Face Generation
Feb 25, 2024While considerable progress has been made in achieving accurate lip synchronization for 3D speech-driven talking face generation, the task of incorporating expressive facial detail synthesis aligned with the speaker's speaking status remains challenging. Our goal is to directly leverage the inherent style information conveyed by human speech for generating an expressive talking face that aligns with the speaking status. In this paper, we propose AVI-Talking, an Audio-Visual Instruction system for expressive Talking face generation. This system harnesses the robust contextual reasoning and hallucination capability offered by Large Language Models (LLMs) to instruct the realistic synthesis of 3D talking faces. Instead of directly learning facial movements from human speech, our two-stage strategy involves the LLMs first comprehending audio information and generating instructions implying expressive facial details seamlessly corresponding to the speech. Subsequently, a diffusion-based generative network executes these instructions. This two-stage process, coupled with the incorporation of LLMs, enhances model interpretability and provides users with flexibility to comprehend instructions and specify desired operations or modifications. Extensive experiments showcase the effectiveness of our approach in producing vivid talking faces with expressive facial movements and consistent emotional status.
ImageBrush: Learning Visual In-Context Instructions for Exemplar-Based Image Manipulation
Aug 02, 2023
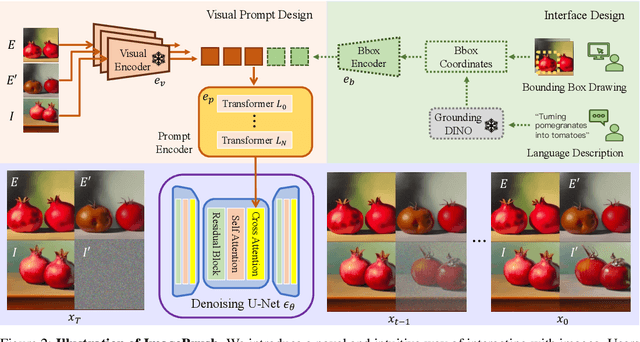

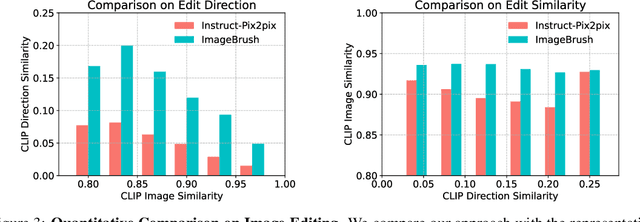
While language-guided image manipulation has made remarkable progress, the challenge of how to instruct the manipulation process faithfully reflecting human intentions persists. An accurate and comprehensive description of a manipulation task using natural language is laborious and sometimes even impossible, primarily due to the inherent uncertainty and ambiguity present in linguistic expressions. Is it feasible to accomplish image manipulation without resorting to external cross-modal language information? If this possibility exists, the inherent modality gap would be effortlessly eliminated. In this paper, we propose a novel manipulation methodology, dubbed ImageBrush, that learns visual instructions for more accurate image editing. Our key idea is to employ a pair of transformation images as visual instructions, which not only precisely captures human intention but also facilitates accessibility in real-world scenarios. Capturing visual instructions is particularly challenging because it involves extracting the underlying intentions solely from visual demonstrations and then applying this operation to a new image. To address this challenge, we formulate visual instruction learning as a diffusion-based inpainting problem, where the contextual information is fully exploited through an iterative process of generation. A visual prompting encoder is carefully devised to enhance the model's capacity in uncovering human intent behind the visual instructions. Extensive experiments show that our method generates engaging manipulation results conforming to the transformations entailed in demonstrations. Moreover, our model exhibits robust generalization capabilities on various downstream tasks such as pose transfer, image translation and video inpainting.
StereoScene: BEV-Assisted Stereo Matching Empowers 3D Semantic Scene Completion
Mar 30, 20233D semantic scene completion (SSC) is an ill-posed task that requires inferring a dense 3D scene from incomplete observations. Previous methods either explicitly incorporate 3D geometric input or rely on learnt 3D prior behind monocular RGB images. However, 3D sensors such as LiDAR are expensive and intrusive while monocular cameras face challenges in modeling precise geometry due to the inherent ambiguity. In this work, we propose StereoScene for 3D Semantic Scene Completion (SSC), which explores taking full advantage of light-weight camera inputs without resorting to any external 3D sensors. Our key insight is to leverage stereo matching to resolve geometric ambiguity. To improve its robustness in unmatched areas, we introduce bird's-eye-view (BEV) representation to inspire hallucination ability with rich context information. On top of the stereo and BEV representations, a mutual interactive aggregation (MIA) module is carefully devised to fully unleash their power. Specifically, a Bi-directional Interaction Transformer (BIT) augmented with confidence re-weighting is used to encourage reliable prediction through mutual guidance while a Dual Volume Aggregation (DVA) module is designed to facilitate complementary aggregation. Experimental results on SemanticKITTI demonstrate that the proposed StereoScene outperforms the state-of-the-art camera-based methods by a large margin with a relative improvement of 26.9% in geometry and 38.6% in semantic.
Make Your Brief Stroke Real and Stereoscopic: 3D-Aware Simplified Sketch to Portrait Generation
Feb 14, 2023



Creating the photo-realistic version of people sketched portraits is useful to various entertainment purposes. Existing studies only generate portraits in the 2D plane with fixed views, making the results less vivid. In this paper, we present Stereoscopic Simplified Sketch-to-Portrait (SSSP), which explores the possibility of creating Stereoscopic 3D-aware portraits from simple contour sketches by involving 3D generative models. Our key insight is to design sketch-aware constraints that can fully exploit the prior knowledge of a tri-plane-based 3D-aware generative model. Specifically, our designed region-aware volume rendering strategy and global consistency constraint further enhance detail correspondences during sketch encoding. Moreover, in order to facilitate the usage of layman users, we propose a Contour-to-Sketch module with vector quantized representations, so that easily drawn contours can directly guide the generation of 3D portraits. Extensive comparisons show that our method generates high-quality results that match the sketch. Our usability study verifies that our system is greatly preferred by user.