 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Single-View 3D Gaussian Splatting using Unsupervised Hierarchical Disentangled Representation Learning
Apr 05, 2025Gaussian Splatting (GS) has recently marked a significant advancement in 3D reconstruction, delivering both rapid rendering and high-quality results. However, existing 3DGS methods pose challenges in understanding underlying 3D semantics, which hinders model controllability and interpretability. To address it, we propose an interpretable single-view 3DGS framework, termed 3DisGS, to discover both coarse- and fine-grained 3D semantics via hierarchical disentangled representation learning (DRL). Specifically, the model employs a dual-branch architecture, consisting of a point cloud initialization branch and a triplane-Gaussian generation branch, to achieve coarse-grained disentanglement by separating 3D geometry and visual appearance features. Subsequently, fine-grained semantic representations within each modality are further discovered through DRL-based encoder-adapters. To our knowledge, this is the first work to achieve unsupervised interpretable 3DGS. Evaluations indicate that our model achieves 3D disentanglement while preserving high-quality and rapid reconstruction.
Disentangled World Models: Learning to Transfer Semantic Knowledge from Distracting Videos for Reinforcement Learning
Mar 11, 2025Training visual reinforcement learning (RL) in practical scenarios presents a significant challenge, $\textit{i.e.,}$ RL agents suffer from low sample efficiency in environments with variations. While various approaches have attempted to alleviate this issue by disentanglement representation learning, these methods usually start learning from scratch without prior knowledge of the world. This paper, in contrast, tries to learn and understand underlying semantic variations from distracting videos via offline-to-online latent distillation and flexible disentanglement constraints. To enable effective cross-domain semantic knowledge transfer, we introduce an interpretable model-based RL framework, dubbed Disentangled World Models (DisWM). Specifically, we pretrain the action-free video prediction model offline with disentanglement regularization to extract semantic knowledge from distracting videos. The disentanglement capability of the pretrained model is then transferred to the world model through latent distillation. For finetuning in the online environment, we exploit the knowledge from the pretrained model and introduce a disentanglement constraint to the world model. During the adaptation phase, the incorporation of actions and rewards from online environment interactions enriches the diversity of the data, which in turn strengthens the disentangled representation learning. Experimental results validate the superiority of our approach on various benchmarks.
OccScene: Semantic Occupancy-based Cross-task Mutual Learning for 3D Scene Generation
Dec 15, 2024



Recent diffusion models have demonstrated remarkable performance in both 3D scene generation and perception tasks. Nevertheless, existing methods typically separate these two processes, acting as a data augmenter to generate synthetic data for downstream perception tasks. In this work, we propose OccScene, a novel mutual learning paradigm that integrates fine-grained 3D perception and high-quality generation in a unified framework, achieving a cross-task win-win effect. OccScene generates new and consistent 3D realistic scenes only depending on text prompts, guided with semantic occupancy in a joint-training diffusion framework. To align the occupancy with the diffusion latent, a Mamba-based Dual Alignment module is introduced to incorporate fine-grained semantics and geometry as perception priors. Within OccScene, the perception module can be effectively improved with customized and diverse generated scenes, while the perception priors in return enhance the generation performance for mutual benefits. Extensive experiments show that OccScene achieves realistic 3D scene generation in broad indoor and outdoor scenarios, while concurrently boosting the perception models to achieve substantial performance improvements in the 3D perception task of semantic occupancy prediction.
Scene Graph Disentanglement and Composition for Generalizable Complex Image Generation
Oct 01, 2024



There has been exciting progress in generating images from natural language or layout conditions. However, these methods struggle to faithfully reproduce complex scenes due to the insufficient modeling of multiple objects and their relationships. To address this issue, we leverage the scene graph, a powerful structured representation, for complex image generation. Different from the previous works that directly use scene graphs for generation, we employ the generative capabilities of variational autoencoders and diffusion models in a generalizable manner, compositing diverse disentangled visual clues from scene graphs. Specifically, we first propose a Semantics-Layout Variational AutoEncoder (SL-VAE) to jointly derive (layouts, semantics) from the input scene graph, which allows a more diverse and reasonable generation in a one-to-many mapping. We then develop a Compositional Masked Attention (CMA) integrated with a diffusion model, incorporating (layouts, semantics) with fine-grained attributes as generation guidance. To further achieve graph manipulation while keeping the visual content consistent, we introduce a Multi-Layered Sampler (MLS) for an "isolated" image editing effect. Extensive experiments demonstrate that our method outperforms recent competitors based on text, layout, or scene graph, in terms of generation rationality and controllability.
Graph-based Unsupervised Disentangled Representation Learning via Multimodal Large Language Models
Jul 26, 2024
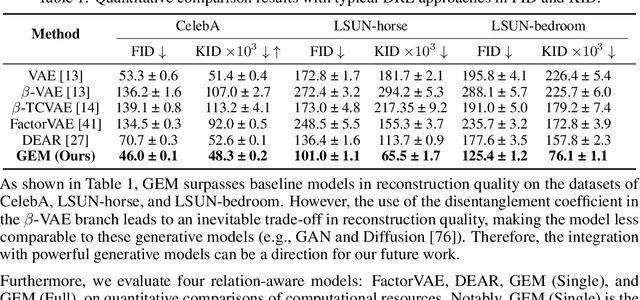
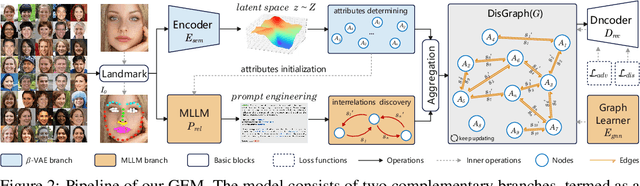
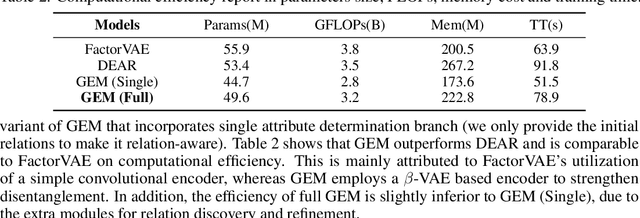
Disentangled representation learning (DRL) aims to identify and decompose underlying factors behind observations, thus facilitating data perception and generation. However, current DRL approaches often rely on the unrealistic assumption that semantic factors are statistically independent. In reality, these factors may exhibit correlations, which off-the-shelf solutions have yet to properly address. To tackle this challenge, we introduce a bidirectional weighted graph-based framework, to learn factorized attributes and their interrelations within complex data. Specifically, we propose a $\beta$-VAE based module to extract factors as the initial nodes of the graph, and leverage the multimodal large language model (MLLM) to discover and rank latent correlations, thereby updating the weighted edges. By integrating these complementary modules, our model successfully achieves fine-grained, practical and unsupervised disentanglement. Experiments demonstrate our method's superior performance in disentanglement and reconstruction. Furthermore, the model inherits enhanced interpretability and generalizability from MLLMs.
NaviNeRF: NeRF-based 3D Representation Disentanglement by Latent Semantic Navigation
Apr 22, 20233D representation disentanglement aims to identify, decompose, and manipulate the underlying explanatory factors of 3D data, which helps AI fundamentally understand our 3D world. This task is currently under-explored and poses great challenges: (i) the 3D representations are complex and in general contains much more information than 2D image; (ii) many 3D representations are not well suited for gradient-based optimization, let alone disentanglement. To address these challenges, we use NeRF as a differentiable 3D representation, and introduce a self-supervised Navigation to identify interpretable semantic directions in the latent space. To our best knowledge, this novel method, dubbed NaviNeRF, is the first work to achieve fine-grained 3D disentanglement without any priors or supervisions. Specifically, NaviNeRF is built upon the generative NeRF pipeline, and equipped with an Outer Navigation Branch and an Inner Refinement Branch. They are complementary -- the outer navigation is to identify global-view semantic directions, and the inner refinement dedicates to fine-grained attributes. A synergistic loss is further devised to coordinate two branches. Extensive experiments demonstrate that NaviNeRF has a superior fine-grained 3D disentanglement ability than the previous 3D-aware models. Its performance is also comparable to editing-oriented models relying on semantic or geometry priors.