 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEDformer: Event-Synchronous Spiking Transformers for Irregular Telemetry Time Series Forecasting
Feb 03, 2026Telemetry streams from large-scale Internet-connected systems (e.g., IoT deployments and online platforms) naturally form an irregular multivariate time series (IMTS) whose accurate forecasting is operationally vital. A closer examination reveals a defining Sparsity-Event Duality (SED) property of IMTS, i.e., long stretches with sparse or no observations are punctuated by short, dense bursts where most semantic events (observations) occur. However, existing Graph- and Transformer-based forecasters ignore SED: pre-alignment to uniform grids with heavy padding violates sparsity by inflating sequences and forcing computation at non-informative steps, while relational recasting weakens event semantics by disrupting local temporal continuity. These limitations motivate a more faithful and natural modeling paradigm for IMTS that aligns with its SED property. We find that Spiking Neural Networks meet this requirement, as they communicate via sparse binary spikes and update in an event-driven manner, aligning naturally with the SED nature of IMTS. Therefore, we present SEDformer, an SED-enhanced Spiking Transformer for telemetry IMTS forecasting that couples: (1) a SED-based Spike Encoder converts raw observations into event synchronous spikes using an Event-Aligned LIF neuron, (2) an Event-Preserving Temporal Downsampling module compresses long gaps while retaining salient firings and (3) a stack of SED-based Spike Transformer blocks enable intra-series dependency modeling with a membrane-based linear attention driven by EA-LIF spiking features. Experiments on public telemetry IMTS datasets show that SEDformer attains state-of-the-art forecasting accuracy while reducing energy and memory usage, providing a natural and efficient path for modeling IMTS.
STReasoner: Empowering LLMs for Spatio-Temporal Reasoning in Time Series via Spatial-Aware Reinforcement Learning
Jan 06, 2026Spatio-temporal reasoning in time series involves the explicit synthesis of temporal dynamics, spatial dependencies, and textual context. This capability is vital for high-stakes decision-making in systems such as traffic networks, power grids, and disease propagation. However, the field remains underdeveloped because most existing works prioritize predictive accuracy over reasoning. To address the gap, we introduce ST-Bench, a benchmark consisting of four core tasks, including etiological reasoning, entity identification, correlation reasoning, and in-context forecasting, developed via a network SDE-based multi-agent data synthesis pipeline. We then propose STReasoner, which empowers LLM to integrate time series, graph structure, and text for explicit reasoning. To promote spatially grounded logic, we introduce S-GRPO, a reinforcement learning algorithm that rewards performance gains specifically attributable to spatial information. Experiments show that STReasoner achieves average accuracy gains between 17% and 135% at only 0.004X the cost of proprietary models and generalizes robustly to real-world data.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025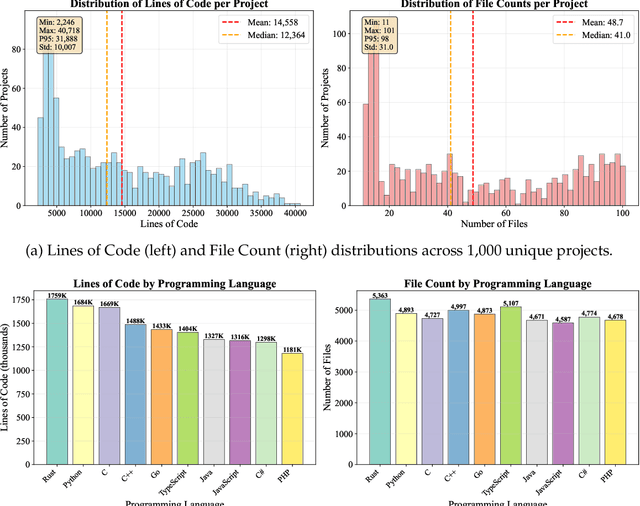
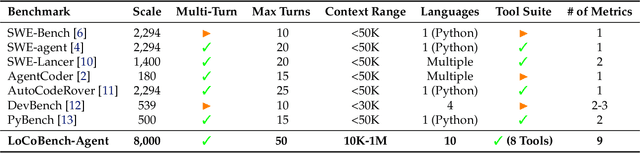

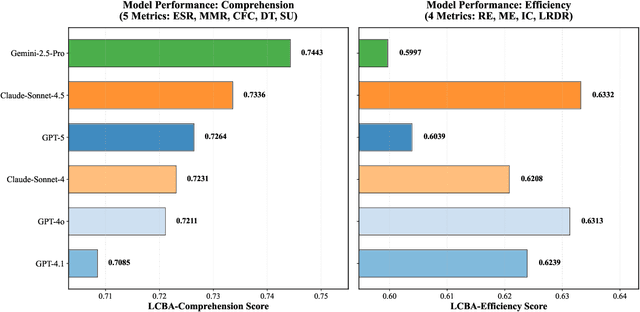
As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
GeoGNN: Quantifying and Mitigating Semantic Drift in Text-Attributed Graphs
Nov 12, 2025Graph neural networks (GNNs) on text--attributed graphs (TAGs) typically encode node texts using pretrained language models (PLMs) and propagate these embeddings through linear neighborhood aggregation. However, the representation spaces of modern PLMs are highly non--linear and geometrically structured, where textual embeddings reside on curved semantic manifolds rather than flat Euclidean spaces. Linear aggregation on such manifolds inevitably distorts geometry and causes semantic drift--a phenomenon where aggregated representations deviate from the intrinsic manifold, losing semantic fidelity and expressive power. To quantitatively investigate this problem, this work introduces a local PCA--based metric that measures the degree of semantic drift and provides the first quantitative framework to analyze how different aggregation mechanisms affect manifold structure. Building upon these insights, we propose Geodesic Aggregation, a manifold--aware mechanism that aggregates neighbor information along geodesics via log--exp mappings on the unit sphere, ensuring that representations remain faithful to the semantic manifold during message passing. We further develop GeoGNN, a practical instantiation that integrates spherical attention with manifold interpolation. Extensive experiments across four benchmark datasets and multiple text encoders show that GeoGNN substantially mitigates semantic drift and consistently outperforms strong baselines, establishing the importance of manifold--aware aggregation in text--attributed graph learning.
Relation as a Prior: A Novel Paradigm for LLM-based Document-level Relation Extraction
Nov 11, 2025Large Language Models (LLMs) have demonstrated their remarkable capabilities in document understanding. However, recent research reveals that LLMs still exhibit performance gaps in Document-level Relation Extraction (DocRE) as requiring fine-grained comprehension. The commonly adopted "extract entities then predict relations" paradigm in LLM-based methods leads to these gaps due to two main reasons: (1) Numerous unrelated entity pairs introduce noise and interfere with the relation prediction for truly related entity pairs. (2) Although LLMs have identified semantic associations between entities, relation labels beyond the predefined set are still treated as prediction errors. To address these challenges, we propose a novel Relation as a Prior (RelPrior) paradigm for LLM-based DocRE. For challenge (1), RelPrior utilizes binary relation as a prior to extract and determine whether two entities are correlated, thereby filtering out irrelevant entity pairs and reducing prediction noise. For challenge (2), RelPrior utilizes predefined relation as a prior to match entities for triples extraction instead of directly predicting relation. Thus, it avoids misjudgment caused by strict predefined relation labeling. Extensive experiments on two benchmarks demonstrate that RelPrior achieves state-of-the-art performance, surpassing existing LLM-based methods.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025



The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.
Using Large Language Models to Assess Teachers' Pedagogical Content Knowledge
May 25, 2025Assessing teachers' pedagogical content knowledge (PCK) through performance-based tasks is both time and effort-consuming. While large language models (LLMs) offer new opportunities for efficient automatic scoring, little is known about whether LLMs introduce construct-irrelevant variance (CIV) in ways similar to or different from traditional machine learning (ML) and human raters. This study examines three sources of CIV -- scenario variability, rater severity, and rater sensitivity to scenario -- in the context of video-based constructed-response tasks targeting two PCK sub-constructs: analyzing student thinking and evaluating teacher responsiveness. Using generalized linear mixed models (GLMMs), we compared variance components and rater-level scoring patterns across three scoring sources: human raters, supervised ML, and LLM. Results indicate that scenario-level variance was minimal across tasks, while rater-related factors contributed substantially to CIV, especially in the more interpretive Task II. The ML model was the most severe and least sensitive rater, whereas the LLM was the most lenient. These findings suggest that the LLM contributes to scoring efficiency while also introducing CIV as human raters do, yet with varying levels of contribution compared to supervised ML. Implications for rater training, automated scoring design, and future research on model interpretability are discussed.
APIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay
Apr 08, 2025Training effective AI agents for multi-turn interactions requires high-quality data that captures realistic human-agent dynamics, yet such data is scarce and expensive to collect manually. We introduce APIGen-MT, a two-phase framework that generates verifiable and diverse multi-turn agent data. In the first phase, our agentic pipeline produces detailed task blueprints with ground-truth actions, leveraging a committee of LLM reviewers and iterative feedback loops. These blueprints are then transformed into complete interaction trajectories through simulated human-agent interplay. We train a family of models -- the xLAM-2-fc-r series with sizes ranging from 1B to 70B parameters. Our models outperform frontier models such as GPT-4o and Claude 3.5 on $\tau$-bench and BFCL benchmarks, with the smaller models surpassing their larger counterparts, particularly in multi-turn settings, while maintaining superior consistency across multiple trials. Comprehensive experiments demonstrate that our verified blueprint-to-details approach yields high-quality training data, enabling the development of more reliable, efficient, and capable agents. We open-source both the synthetic data collected and the trained xLAM-2-fc-r models to advance research in AI agents. Models are available on HuggingFace at https://huggingface.co/collections/Salesforce/xlam-2-67ef5be12949d8dcdae354c4 and project website is https://apigen-mt.github.io
ActionStudio: A Lightweight Framework for Data and Training of Large Action Models
Mar 31, 2025Action models are essential for enabling autonomous agents to perform complex tasks. However, training large action models remains challenging due to the diversity of agent environments and the complexity of agentic data. Despite growing interest, existing infrastructure provides limited support for scalable, agent-specific fine-tuning. We present ActionStudio, a lightweight and extensible data and training framework designed for large action models. ActionStudio unifies heterogeneous agent trajectories through a standardized format, supports diverse training paradigms including LoRA, full fine-tuning, and distributed setups, and integrates robust preprocessing and verification tools. We validate its effectiveness across both public and realistic industry benchmarks, demonstrating strong performance and practical scalability. We open-sourced code and data at https://github.com/SalesforceAIResearch/xLAM to facilitate research in the community.
How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and Outlook
Mar 14, 2025Time series analysis (TSA) is a longstanding research topic in the data mining community and has wide real-world significance. Compared to "richer" modalities such as language and vision, which have recently experienced explosive development and are densely connected, the time-series modality remains relatively underexplored and isolated. We notice that many recent TSA works have formed a new research field, i.e., Multiple Modalities for TSA (MM4TSA). In general, these MM4TSA works follow a common motivation: how TSA can benefit from multiple modalities. This survey is the first to offer a comprehensive review and a detailed outlook for this emerging field. Specifically, we systematically discuss three benefits: (1) reusing foundation models of other modalities for efficient TSA, (2) multimodal extension for enhanced TSA, and (3) cross-modality interaction for advanced TSA. We further group the works by the introduced modality type, including text, images, audio, tables, and others, within each perspective. Finally, we identify the gaps with future opportunities, including the reused modalities selections, heterogeneous modality combinations, and unseen tasks generalizations, corresponding to the three benefits. We release an up-to-date GitHub repository that includes key papers and resources.