 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPIGen-MT: Agentic Pipeline for Multi-Turn Data Generation via Simulated Agent-Human Interplay
Apr 08, 2025Training effective AI agents for multi-turn interactions requires high-quality data that captures realistic human-agent dynamics, yet such data is scarce and expensive to collect manually. We introduce APIGen-MT, a two-phase framework that generates verifiable and diverse multi-turn agent data. In the first phase, our agentic pipeline produces detailed task blueprints with ground-truth actions, leveraging a committee of LLM reviewers and iterative feedback loops. These blueprints are then transformed into complete interaction trajectories through simulated human-agent interplay. We train a family of models -- the xLAM-2-fc-r series with sizes ranging from 1B to 70B parameters. Our models outperform frontier models such as GPT-4o and Claude 3.5 on $\tau$-bench and BFCL benchmarks, with the smaller models surpassing their larger counterparts, particularly in multi-turn settings, while maintaining superior consistency across multiple trials. Comprehensive experiments demonstrate that our verified blueprint-to-details approach yields high-quality training data, enabling the development of more reliable, efficient, and capable agents. We open-source both the synthetic data collected and the trained xLAM-2-fc-r models to advance research in AI agents. Models are available on HuggingFace at https://huggingface.co/collections/Salesforce/xlam-2-67ef5be12949d8dcdae354c4 and project website is https://apigen-mt.github.io
ActionStudio: A Lightweight Framework for Data and Training of Large Action Models
Mar 31, 2025Action models are essential for enabling autonomous agents to perform complex tasks. However, training large action models remains challenging due to the diversity of agent environments and the complexity of agentic data. Despite growing interest, existing infrastructure provides limited support for scalable, agent-specific fine-tuning. We present ActionStudio, a lightweight and extensible data and training framework designed for large action models. ActionStudio unifies heterogeneous agent trajectories through a standardized format, supports diverse training paradigms including LoRA, full fine-tuning, and distributed setups, and integrates robust preprocessing and verification tools. We validate its effectiveness across both public and realistic industry benchmarks, demonstrating strong performance and practical scalability. We open-sourced code and data at https://github.com/SalesforceAIResearch/xLAM to facilitate research in the community.
SpecTool: A Benchmark for Characterizing Errors in Tool-Use LLMs
Nov 20, 2024



Evaluating the output of Large Language Models (LLMs) is one of the most critical aspects of building a performant compound AI system. Since the output from LLMs propagate to downstream steps, identifying LLM errors is crucial to system performance. A common task for LLMs in AI systems is tool use. While there are several benchmark environments for evaluating LLMs on this task, they typically only give a success rate without any explanation of the failure cases. To solve this problem, we introduce SpecTool, a new benchmark to identify error patterns in LLM output on tool-use tasks. Our benchmark data set comprises of queries from diverse environments that can be used to test for the presence of seven newly characterized error patterns. Using SPECTOOL , we show that even the most prominent LLMs exhibit these error patterns in their outputs. Researchers can use the analysis and insights from SPECTOOL to guide their error mitigation strategies.
PRACT: Optimizing Principled Reasoning and Acting of LLM Agent
Oct 24, 2024



We introduce the Principled Reasoning and Acting (PRAct) framework, a novel method for learning and enforcing action principles from trajectory data. Central to our approach is the use of text gradients from a reflection and optimization engine to derive these action principles. To adapt action principles to specific task requirements, we propose a new optimization framework, Reflective Principle Optimization (RPO). After execution, RPO employs a reflector to critique current action principles and an optimizer to update them accordingly. We develop the RPO framework under two scenarios: Reward-RPO, which uses environmental rewards for reflection, and Self-RPO, which conducts self-reflection without external rewards. Additionally, two RPO methods, RPO-Traj and RPO-Batch, is introduced to adapt to different settings. Experimental results across four environments demonstrate that the PRAct agent, leveraging the RPO framework, effectively learns and applies action principles to enhance performance.
xLAM: A Family of Large Action Models to Empower AI Agent Systems
Sep 05, 2024



Autonomous agents powered by large language models (LLMs) have attracted significant research interest. However, the open-source community faces many challenges in developing specialized models for agent tasks, driven by the scarcity of high-quality agent datasets and the absence of standard protocols in this area. We introduce and publicly release xLAM, a series of large action models designed for AI agent tasks. The xLAM series includes five models with both dense and mixture-of-expert architectures, ranging from 1B to 8x22B parameters, trained using a scalable, flexible pipeline that unifies, augments, and synthesizes diverse datasets to enhance AI agents' generalizability and performance across varied environments. Our experimental results demonstrate that xLAM consistently delivers exceptional performance across multiple agent ability benchmarks, notably securing the 1st position on the Berkeley Function-Calling Leaderboard, outperforming GPT-4, Claude-3, and many other models in terms of tool use. By releasing the xLAM series, we aim to advance the performance of open-source LLMs for autonomous AI agents, potentially accelerating progress and democratizing access to high-performance models for agent tasks. Models are available at https://huggingface.co/collections/Salesforce/xlam-models-65f00e2a0a63bbcd1c2dade4
APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets
Jun 26, 2024



The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to synthesize verifiable high-quality datasets for function-calling applications. We leverage APIGen and collect 3,673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains. The dataset is available on Huggingface: https://huggingface.co/datasets/Salesforce/xlam-function-calling-60k and the project homepage: https://apigen-pipeline.github.io/
AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning
Feb 26, 2024



Autonomous agents powered by large language models (LLMs) have garnered significant research attention. However, fully harnessing the potential of LLMs for agent-based tasks presents inherent challenges due to the heterogeneous nature of diverse data sources featuring multi-turn trajectories. In this paper, we introduce \textbf{AgentOhana} as a comprehensive solution to address these challenges. \textit{AgentOhana} aggregates agent trajectories from distinct environments, spanning a wide array of scenarios. It meticulously standardizes and unifies these trajectories into a consistent format, streamlining the creation of a generic data loader optimized for agent training. Leveraging the data unification, our training pipeline maintains equilibrium across different data sources and preserves independent randomness across devices during dataset partitioning and model training. Additionally, we present \textbf{xLAM-v0.1}, a large action model tailored for AI agents, which demonstrates exceptional performance across various benchmarks.
PhoMT: A High-Quality and Large-Scale Benchmark Dataset for Vietnamese-English Machine Translation
Oct 23, 2021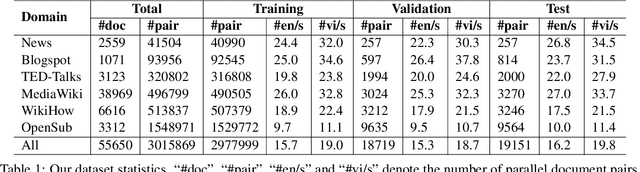
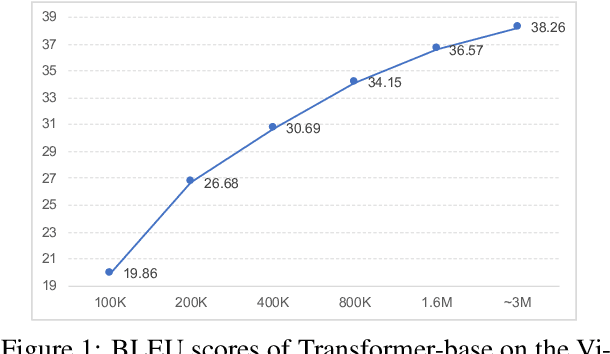
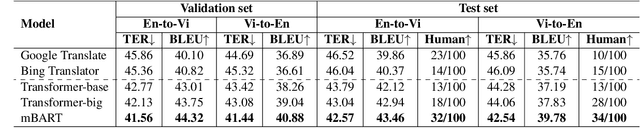

We introduce a high-quality and large-scale Vietnamese-English parallel dataset of 3.02M sentence pairs, which is 2.9M pairs larger than the benchmark Vietnamese-English machine translation corpus IWSLT15. We conduct experiments comparing strong neural baselines and well-known automatic translation engines on our dataset and find that in both automatic and human evaluations: the best performance is obtained by fine-tuning the pre-trained sequence-to-sequence denoising auto-encoder mBART. To our best knowledge, this is the first large-scale Vietnamese-English machine translation study. We hope our publicly available dataset and study can serve as a starting point for future research and applications on Vietnamese-English machine translation.