 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRIME: Planning and Retrieval-Integrated Memory for Enhanced Reasoning
Sep 26, 2025Inspired by the dual-process theory of human cognition from \textit{Thinking, Fast and Slow}, we introduce \textbf{PRIME} (Planning and Retrieval-Integrated Memory for Enhanced Reasoning), a multi-agent reasoning framework that dynamically integrates \textbf{System 1} (fast, intuitive thinking) and \textbf{System 2} (slow, deliberate thinking). PRIME first employs a Quick Thinking Agent (System 1) to generate a rapid answer; if uncertainty is detected, it then triggers a structured System 2 reasoning pipeline composed of specialized agents for \textit{planning}, \textit{hypothesis generation}, \textit{retrieval}, \textit{information integration}, and \textit{decision-making}. This multi-agent design faithfully mimics human cognitive processes and enhances both efficiency and accuracy. Experimental results with LLaMA 3 models demonstrate that PRIME enables open-source LLMs to perform competitively with state-of-the-art closed-source models like GPT-4 and GPT-4o on benchmarks requiring multi-hop and knowledge-grounded reasoning. This research establishes PRIME as a scalable solution for improving LLMs in domains requiring complex, knowledge-intensive reasoning.
A High-Quality and Large-Scale Dataset for English-Vietnamese Speech Translation
Aug 08, 2022


In this paper, we introduce a high-quality and large-scale benchmark dataset for English-Vietnamese speech translation with 508 audio hours, consisting of 331K triplets of (sentence-lengthed audio, English source transcript sentence, Vietnamese target subtitle sentence). We also conduct empirical experiments using strong baselines and find that the traditional "Cascaded" approach still outperforms the modern "End-to-End" approach. To the best of our knowledge, this is the first large-scale English-Vietnamese speech translation study. We hope both our publicly available dataset and study can serve as a starting point for future research and applications on English-Vietnamese speech translation. Our dataset is available at https://github.com/VinAIResearch/PhoST
PhoMT: A High-Quality and Large-Scale Benchmark Dataset for Vietnamese-English Machine Translation
Oct 23, 2021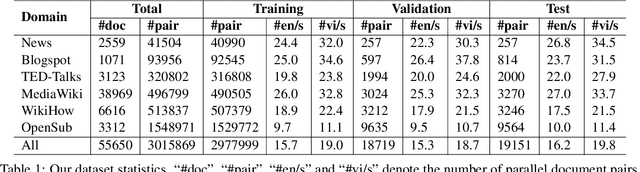
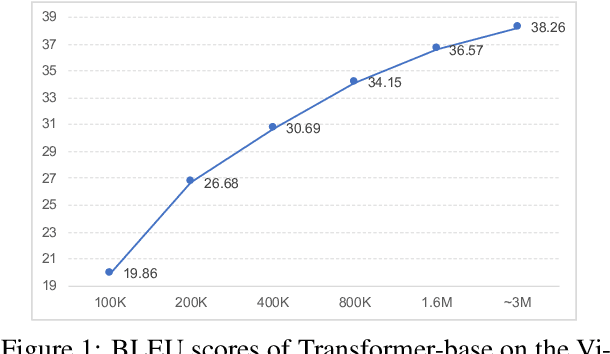
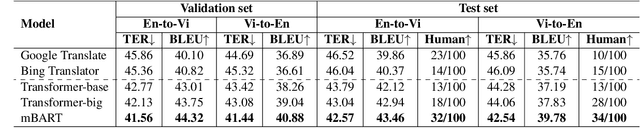

We introduce a high-quality and large-scale Vietnamese-English parallel dataset of 3.02M sentence pairs, which is 2.9M pairs larger than the benchmark Vietnamese-English machine translation corpus IWSLT15. We conduct experiments comparing strong neural baselines and well-known automatic translation engines on our dataset and find that in both automatic and human evaluations: the best performance is obtained by fine-tuning the pre-trained sequence-to-sequence denoising auto-encoder mBART. To our best knowledge, this is the first large-scale Vietnamese-English machine translation study. We hope our publicly available dataset and study can serve as a starting point for future research and applications on Vietnamese-English machine translation.
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Sep 20, 2021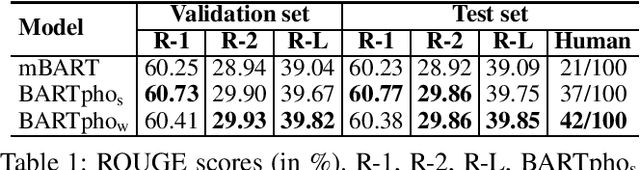
We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future research and applications of generative Vietnamese NLP tasks. Our BARTpho models are available at: https://github.com/VinAIResearch/BARTpho