 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Decoding for Cross-lingual Label Projection
Feb 05, 2024Zero-shot cross-lingual transfer utilizing multilingual LLMs has become a popular learning paradigm for low-resource languages with no labeled training data. However, for NLP tasks that involve fine-grained predictions on words and phrases, the performance of zero-shot cross-lingual transfer learning lags far behind supervised fine-tuning methods. Therefore, it is common to exploit translation and label projection to further improve the performance by (1) translating training data that is available in a high-resource language (e.g., English) together with the gold labels into low-resource languages, and/or (2) translating test data in low-resource languages to a high-source language to run inference on, then projecting the predicted span-level labels back onto the original test data. However, state-of-the-art marker-based label projection methods suffer from translation quality degradation due to the extra label markers injected in the input to the translation model. In this work, we explore a new direction that leverages constrained decoding for label projection to overcome the aforementioned issues. Our new method not only can preserve the quality of translated texts but also has the versatility of being applicable to both translating training and translating test data strategies. This versatility is crucial as our experiments reveal that translating test data can lead to a considerable boost in performance compared to translating only training data. We evaluate on two cross-lingual transfer tasks, namely Named Entity Recognition and Event Argument Extraction, spanning 20 languages. The results demonstrate that our approach outperforms the state-of-the-art marker-based method by a large margin and also shows better performance than other label projection methods that rely on external word alignment.
Improved Instruction Ordering in Recipe-Grounded Conversation
May 26, 2023In this paper, we study the task of instructional dialogue and focus on the cooking domain. Analyzing the generated output of the GPT-J model, we reveal that the primary challenge for a recipe-grounded dialog system is how to provide the instructions in the correct order. We hypothesize that this is due to the model's lack of understanding of user intent and inability to track the instruction state (i.e., which step was last instructed). Therefore, we propose to explore two auxiliary subtasks, namely User Intent Detection and Instruction State Tracking, to support Response Generation with improved instruction grounding. Experimenting with our newly collected dataset, ChattyChef, shows that incorporating user intent and instruction state information helps the response generation model mitigate the incorrect order issue. Furthermore, to investigate whether ChatGPT has completely solved this task, we analyze its outputs and find that it also makes mistakes (10.7% of the responses), about half of which are out-of-order instructions. We will release ChattyChef to facilitate further research in this area at: https://github.com/octaviaguo/ChattyChef.
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Sep 20, 2021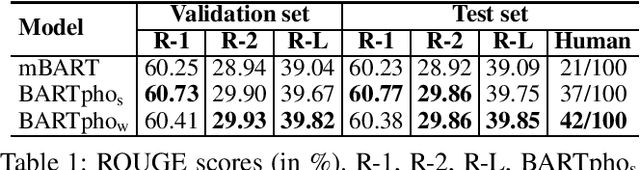
We present BARTpho with two versions -- BARTpho_word and BARTpho_syllable -- the first public large-scale monolingual sequence-to-sequence models pre-trained for Vietnamese. Our BARTpho uses the "large" architecture and pre-training scheme of the sequence-to-sequence denoising model BART, thus especially suitable for generative NLP tasks. Experiments on a downstream task of Vietnamese text summarization show that in both automatic and human evaluations, our BARTpho outperforms the strong baseline mBART and improves the state-of-the-art. We release BARTpho to facilitate future research and applications of generative Vietnamese NLP tasks. Our BARTpho models are available at: https://github.com/VinAIResearch/BARTpho