 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgevLinear: A Powerful Linear Model for Multivariate Time Series Forecasting
Jan 20, 2026In this paper, we present \textbf{vLinear}, an effective yet efficient \textbf{linear}-based multivariate time series forecaster featuring two components: the \textbf{v}ecTrans module and the WFMLoss objective. Many state-of-the-art forecasters rely on self-attention or its variants to capture multivariate correlations, typically incurring $\mathcal{O}(N^2)$ computational complexity with respect to the number of variates $N$. To address this, we propose vecTrans, a lightweight module that utilizes a learnable vector to model multivariate correlations, reducing the complexity to $\mathcal{O}(N)$. Notably, vecTrans can be seamlessly integrated into Transformer-based forecasters, delivering up to 5$\times$ inference speedups and consistent performance gains. Furthermore, we introduce WFMLoss (Weighted Flow Matching Loss) as the objective. In contrast to typical \textbf{velocity-oriented} flow matching objectives, we demonstrate that a \textbf{final-series-oriented} formulation yields significantly superior forecasting accuracy. WFMLoss also incorporates path- and horizon-weighted strategies to focus learning on more reliable paths and horizons. Empirically, vLinear achieves state-of-the-art performance across 22 benchmarks and 124 forecasting settings. Moreover, WFMLoss serves as an effective plug-and-play objective, consistently improving existing forecasters. The code is available at https://anonymous.4open.science/r/vLinear.
Tree-based Dialogue Reinforced Policy Optimization for Red-Teaming Attacks
Oct 02, 2025Despite recent rapid progress in AI safety, current large language models remain vulnerable to adversarial attacks in multi-turn interaction settings, where attackers strategically adapt their prompts across conversation turns and pose a more critical yet realistic challenge. Existing approaches that discover safety vulnerabilities either rely on manual red-teaming with human experts or employ automated methods using pre-defined templates and human-curated attack data, with most focusing on single-turn attacks. However, these methods did not explore the vast space of possible multi-turn attacks, failing to consider novel attack trajectories that emerge from complex dialogue dynamics and strategic conversation planning. This gap is particularly critical given recent findings that LLMs exhibit significantly higher vulnerability to multi-turn attacks compared to single-turn attacks. We propose DialTree-RPO, an on-policy reinforcement learning framework integrated with tree search that autonomously discovers diverse multi-turn attack strategies by treating the dialogue as a sequential decision-making problem, enabling systematic exploration without manually curated data. Through extensive experiments, our approach not only achieves more than 25.9% higher ASR across 10 target models compared to previous state-of-the-art approaches, but also effectively uncovers new attack strategies by learning optimal dialogue policies that maximize attack success across multiple turns.
Teacher-Guided Pseudo Supervision and Cross-Modal Alignment for Audio-Visual Video Parsing
Sep 17, 2025Weakly-supervised audio-visual video parsing (AVVP) seeks to detect audible, visible, and audio-visual events without temporal annotations. Previous work has emphasized refining global predictions through contrastive or collaborative learning, but neglected stable segment-level supervision and class-aware cross-modal alignment. To address this, we propose two strategies: (1) an exponential moving average (EMA)-guided pseudo supervision framework that generates reliable segment-level masks via adaptive thresholds or top-k selection, offering stable temporal guidance beyond video-level labels; and (2) a class-aware cross-modal agreement (CMA) loss that aligns audio and visual embeddings at reliable segment-class pairs, ensuring consistency across modalities while preserving temporal structure. Evaluations on LLP and UnAV-100 datasets shows that our method achieves state-of-the-art (SOTA) performance across multiple metrics.
TEn-CATS: Text-Enriched Audio-Visual Video Parsing with Multi-Scale Category-Aware Temporal Graph
Sep 04, 2025Audio-Visual Video Parsing (AVVP) task aims to identify event categories and their occurrence times in a given video with weakly supervised labels. Existing methods typically fall into two categories: (i) designing enhanced architectures based on attention mechanism for better temporal modeling, and (ii) generating richer pseudo-labels to compensate for the absence of frame-level annotations. However, the first type methods treat noisy segment-level pseudo labels as reliable supervision and the second type methods let indiscriminate attention spread them across all frames, the initial errors are repeatedly amplified during training. To address this issue, we propose a method that combines the Bi-Directional Text Fusion (BiT) module and Category-Aware Temporal Graph (CATS) module. Specifically, we integrate the strengths and complementarity of the two previous research directions. We first perform semantic injection and dynamic calibration on audio and visual modality features through the BiT module, to locate and purify cleaner and richer semantic cues. Then, we leverage the CATS module for semantic propagation and connection to enable precise semantic information dissemination across time. Experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance in multiple key indicators on two benchmark datasets, LLP and UnAV-100.
OLinear: A Linear Model for Time Series Forecasting in Orthogonally Transformed Domain
May 14, 2025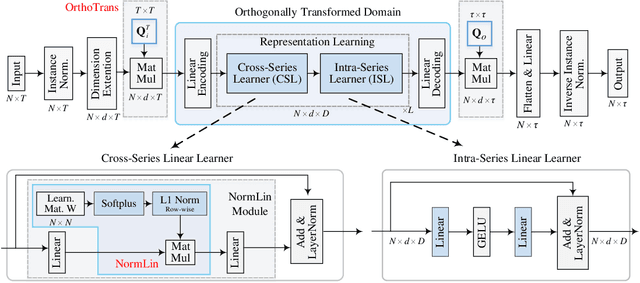
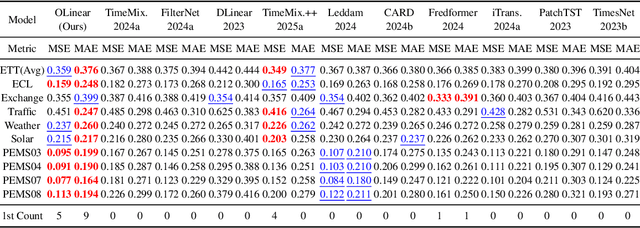
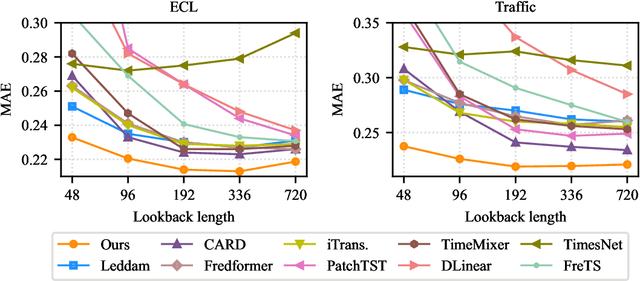
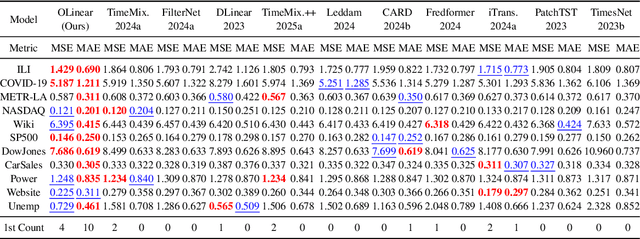
This paper presents $\mathbf{OLinear}$, a $\mathbf{linear}$-based multivariate time series forecasting model that operates in an $\mathbf{o}$rthogonally transformed domain. Recent forecasting models typically adopt the temporal forecast (TF) paradigm, which directly encode and decode time series in the time domain. However, the entangled step-wise dependencies in series data can hinder the performance of TF. To address this, some forecasters conduct encoding and decoding in the transformed domain using fixed, dataset-independent bases (e.g., sine and cosine signals in the Fourier transform). In contrast, we utilize $\mathbf{OrthoTrans}$, a data-adaptive transformation based on an orthogonal matrix that diagonalizes the series' temporal Pearson correlation matrix. This approach enables more effective encoding and decoding in the decorrelated feature domain and can serve as a plug-in module to enhance existing forecasters. To enhance the representation learning for multivariate time series, we introduce a customized linear layer, $\mathbf{NormLin}$, which employs a normalized weight matrix to capture multivariate dependencies. Empirically, the NormLin module shows a surprising performance advantage over multi-head self-attention, while requiring nearly half the FLOPs. Extensive experiments on 24 benchmarks and 140 forecasting tasks demonstrate that OLinear consistently achieves state-of-the-art performance with high efficiency. Notably, as a plug-in replacement for self-attention, the NormLin module consistently enhances Transformer-based forecasters. The code and datasets are available at https://anonymous.4open.science/r/OLinear
How to Protect Yourself from 5G Radiation? Investigating LLM Responses to Implicit Misinformation
Mar 12, 2025



As Large Language Models (LLMs) are widely deployed in diverse scenarios, the extent to which they could tacitly spread misinformation emerges as a critical safety concern. Current research primarily evaluates LLMs on explicit false statements, overlooking how misinformation often manifests subtly as unchallenged premises in real-world user interactions. We curated ECHOMIST, the first comprehensive benchmark for implicit misinformation, where the misinformed assumptions are embedded in a user query to LLMs. ECHOMIST is based on rigorous selection criteria and carefully curated data from diverse sources, including real-world human-AI conversations and social media interactions. We also introduce a new evaluation metric to measure whether LLMs can recognize and counter false information rather than amplify users' misconceptions. Through an extensive empirical study on a wide range of LLMs, including GPT-4, Claude, and Llama, we find that current models perform alarmingly poorly on this task, often failing to detect false premises and generating misleading explanations. Our findings underscore the critical need for an increased focus on implicit misinformation in LLM safety research.
Normal-NeRF: Ambiguity-Robust Normal Estimation for Highly Reflective Scenes
Jan 16, 2025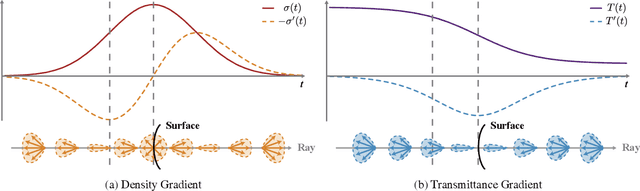



Neural Radiance Fields (NeRF) often struggle with reconstructing and rendering highly reflective scenes. Recent advancements have developed various reflection-aware appearance models to enhance NeRF's capability to render specular reflections. However, the robust reconstruction of highly reflective scenes is still hindered by the inherent shape ambiguity on specular surfaces. Existing methods typically rely on additional geometry priors to regularize the shape prediction, but this can lead to oversmoothed geometry in complex scenes. Observing the critical role of surface normals in parameterizing reflections, we introduce a transmittance-gradient-based normal estimation technique that remains robust even under ambiguous shape conditions. Furthermore, we propose a dual activated densities module that effectively bridges the gap between smooth surface normals and sharp object boundaries. Combined with a reflection-aware appearance model, our proposed method achieves robust reconstruction and high-fidelity rendering of scenes featuring both highly specular reflections and intricate geometric structures. Extensive experiments demonstrate that our method outperforms existing state-of-the-art methods on various datasets.
Towards Open-Vocabulary Audio-Visual Event Localization
Nov 18, 2024The Audio-Visual Event Localization (AVEL) task aims to temporally locate and classify video events that are both audible and visible. Most research in this field assumes a closed-set setting, which restricts these models' ability to handle test data containing event categories absent (unseen) during training. Recently, a few studies have explored AVEL in an open-set setting, enabling the recognition of unseen events as ``unknown'', but without providing category-specific semantics. In this paper, we advance the field by introducing the Open-Vocabulary Audio-Visual Event Localization (OV-AVEL) problem, which requires localizing audio-visual events and predicting explicit categories for both seen and unseen data at inference. To address this new task, we propose the OV-AVEBench dataset, comprising 24,800 videos across 67 real-life audio-visual scenes (seen:unseen = 46:21), each with manual segment-level annotation. We also establish three evaluation metrics for this task. Moreover, we investigate two baseline approaches, one training-free and one using a further fine-tuning paradigm. Specifically, we utilize the unified multimodal space from the pretrained ImageBind model to extract audio, visual, and textual (event classes) features. The training-free baseline then determines predictions by comparing the consistency of audio-text and visual-text feature similarities. The fine-tuning baseline incorporates lightweight temporal layers to encode temporal relations within the audio and visual modalities, using OV-AVEBench training data for model fine-tuning. We evaluate these baselines on the proposed OV-AVEBench dataset and discuss potential directions for future work in this new field.
Open-Vocabulary Audio-Visual Semantic Segmentation
Jul 31, 2024



Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%. The code is available at https://github.com/ruohaoguo/ovavss.
LLMs Assist NLP Researchers: Critique Paper (Meta-)Reviewing
Jun 25, 2024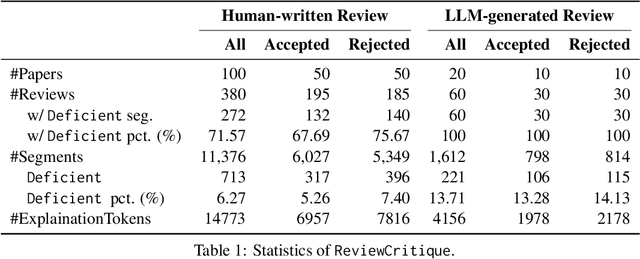
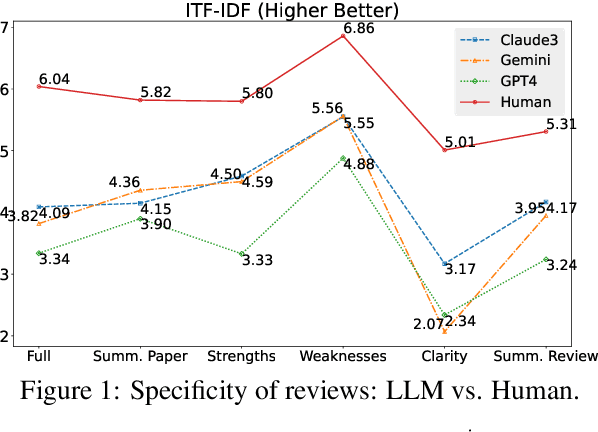

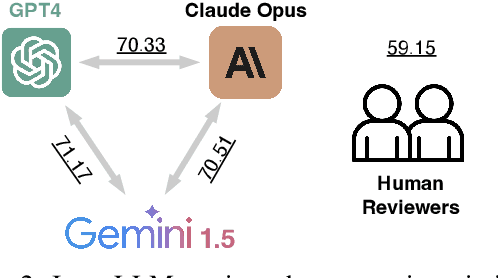
This work is motivated by two key trends. On one hand, large language models (LLMs) have shown remarkable versatility in various generative tasks such as writing, drawing, and question answering, significantly reducing the time required for many routine tasks. On the other hand, researchers, whose work is not only time-consuming but also highly expertise-demanding, face increasing challenges as they have to spend more time reading, writing, and reviewing papers. This raises the question: how can LLMs potentially assist researchers in alleviating their heavy workload? This study focuses on the topic of LLMs assist NLP Researchers, particularly examining the effectiveness of LLM in assisting paper (meta-)reviewing and its recognizability. To address this, we constructed the ReviewCritique dataset, which includes two types of information: (i) NLP papers (initial submissions rather than camera-ready) with both human-written and LLM-generated reviews, and (ii) each review comes with "deficiency" labels and corresponding explanations for individual segments, annotated by experts. Using ReviewCritique, this study explores two threads of research questions: (i) "LLMs as Reviewers", how do reviews generated by LLMs compare with those written by humans in terms of quality and distinguishability? (ii) "LLMs as Metareviewers", how effectively can LLMs identify potential issues, such as Deficient or unprofessional review segments, within individual paper reviews? To our knowledge, this is the first work to provide such a comprehensive analysis.