 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
VAR RL Done Right: Tackling Asynchronous Policy Conflicts in Visual Autoregressive Generation
Jan 05, 2026Visual generation is dominated by three paradigms: AutoRegressive (AR), diffusion, and Visual AutoRegressive (VAR) models. Unlike AR and diffusion, VARs operate on heterogeneous input structures across their generation steps, which creates severe asynchronous policy conflicts. This issue becomes particularly acute in reinforcement learning (RL) scenarios, leading to unstable training and suboptimal alignment. To resolve this, we propose a novel framework to enhance Group Relative Policy Optimization (GRPO) by explicitly managing these conflicts. Our method integrates three synergistic components: 1) a stabilizing intermediate reward to guide early-stage generation; 2) a dynamic time-step reweighting scheme for precise credit assignment; and 3) a novel mask propagation algorithm, derived from principles of Reward Feedback Learning (ReFL), designed to isolate optimization effects both spatially and temporally. Our approach demonstrates significant improvements in sample quality and objective alignment over the vanilla GRPO baseline, enabling robust and effective optimization for VAR models.
DetailFlow: 1D Coarse-to-Fine Autoregressive Image Generation via Next-Detail Prediction
May 27, 2025This paper presents DetailFlow, a coarse-to-fine 1D autoregressive (AR) image generation method that models images through a novel next-detail prediction strategy. By learning a resolution-aware token sequence supervised with progressively degraded images, DetailFlow enables the generation process to start from the global structure and incrementally refine details. This coarse-to-fine 1D token sequence aligns well with the autoregressive inference mechanism, providing a more natural and efficient way for the AR model to generate complex visual content. Our compact 1D AR model achieves high-quality image synthesis with significantly fewer tokens than previous approaches, i.e. VAR/VQGAN. We further propose a parallel inference mechanism with self-correction that accelerates generation speed by approximately 8x while reducing accumulation sampling error inherent in teacher-forcing supervision. On the ImageNet 256x256 benchmark, our method achieves 2.96 gFID with 128 tokens, outperforming VAR (3.3 FID) and FlexVAR (3.05 FID), which both require 680 tokens in their AR models. Moreover, due to the significantly reduced token count and parallel inference mechanism, our method runs nearly 2x faster inference speed compared to VAR and FlexVAR. Extensive experimental results demonstrate DetailFlow's superior generation quality and efficiency compared to existing state-of-the-art methods.
TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation
Dec 04, 2024



We present TokenFlow, a novel unified image tokenizer that bridges the long-standing gap between multimodal understanding and generation. Prior research attempt to employ a single reconstruction-targeted Vector Quantization (VQ) encoder for unifying these two tasks. We observe that understanding and generation require fundamentally different granularities of visual information. This leads to a critical trade-off, particularly compromising performance in multimodal understanding tasks. TokenFlow addresses this challenge through an innovative dual-codebook architecture that decouples semantic and pixel-level feature learning while maintaining their alignment via a shared mapping mechanism. This design enables direct access to both high-level semantic representations crucial for understanding tasks and fine-grained visual features essential for generation through shared indices. Our extensive experiments demonstrate TokenFlow's superiority across multiple dimensions. Leveraging TokenFlow, we demonstrate for the first time that discrete visual input can surpass LLaVA-1.5 13B in understanding performance, achieving a 7.2\% average improvement. For image reconstruction, we achieve a strong FID score of 0.63 at 384*384 resolution. Moreover, TokenFlow establishes state-of-the-art performance in autoregressive image generation with a GenEval score of 0.55 at 256*256 resolution, achieving comparable results to SDXL.
Open-Vocabulary Audio-Visual Semantic Segmentation
Jul 31, 2024



Audio-visual semantic segmentation (AVSS) aims to segment and classify sounding objects in videos with acoustic cues. However, most approaches operate on the close-set assumption and only identify pre-defined categories from training data, lacking the generalization ability to detect novel categories in practical applications. In this paper, we introduce a new task: open-vocabulary audio-visual semantic segmentation, extending AVSS task to open-world scenarios beyond the annotated label space. This is a more challenging task that requires recognizing all categories, even those that have never been seen nor heard during training. Moreover, we propose the first open-vocabulary AVSS framework, OV-AVSS, which mainly consists of two parts: 1) a universal sound source localization module to perform audio-visual fusion and locate all potential sounding objects and 2) an open-vocabulary classification module to predict categories with the help of the prior knowledge from large-scale pre-trained vision-language models. To properly evaluate the open-vocabulary AVSS, we split zero-shot training and testing subsets based on the AVSBench-semantic benchmark, namely AVSBench-OV. Extensive experiments demonstrate the strong segmentation and zero-shot generalization ability of our model on all categories. On the AVSBench-OV dataset, OV-AVSS achieves 55.43% mIoU on base categories and 29.14% mIoU on novel categories, exceeding the state-of-the-art zero-shot method by 41.88%/20.61% and open-vocabulary method by 10.2%/11.6%. The code is available at https://github.com/ruohaoguo/ovavss.
AvatarVerse: High-quality & Stable 3D Avatar Creation from Text and Pose
Aug 07, 2023



Creating expressive, diverse and high-quality 3D avatars from highly customized text descriptions and pose guidance is a challenging task, due to the intricacy of modeling and texturing in 3D that ensure details and various styles (realistic, fictional, etc). We present AvatarVerse, a stable pipeline for generating expressive high-quality 3D avatars from nothing but text descriptions and pose guidance. In specific, we introduce a 2D diffusion model conditioned on DensePose signal to establish 3D pose control of avatars through 2D images, which enhances view consistency from partially observed scenarios. It addresses the infamous Janus Problem and significantly stablizes the generation process. Moreover, we propose a progressive high-resolution 3D synthesis strategy, which obtains substantial improvement over the quality of the created 3D avatars. To this end, the proposed AvatarVerse pipeline achieves zero-shot 3D modeling of 3D avatars that are not only more expressive, but also in higher quality and fidelity than previous works. Rigorous qualitative evaluations and user studies showcase AvatarVerse's superiority in synthesizing high-fidelity 3D avatars, leading to a new standard in high-quality and stable 3D avatar creation. Our project page is: https://avatarverse3d.github.io
The Hidden Dance of Phonemes and Visage: Unveiling the Enigmatic Link between Phonemes and Facial Features
Jul 26, 2023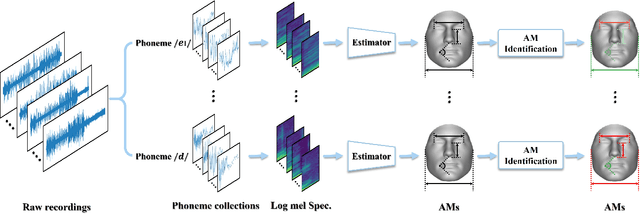
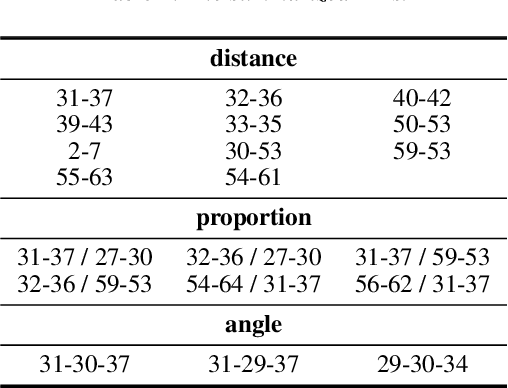
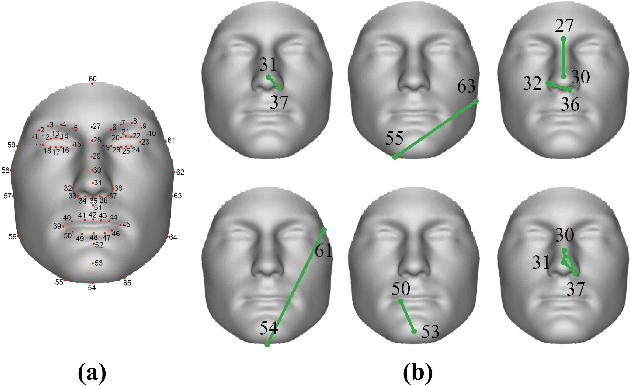
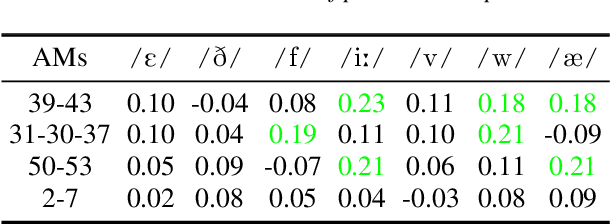
This work unveils the enigmatic link between phonemes and facial features. Traditional studies on voice-face correlations typically involve using a long period of voice input, including generating face images from voices and reconstructing 3D face meshes from voices. However, in situations like voice-based crimes, the available voice evidence may be short and limited. Additionally, from a physiological perspective, each segment of speech -- phoneme -- corresponds to different types of airflow and movements in the face. Therefore, it is advantageous to discover the hidden link between phonemes and face attributes. In this paper, we propose an analysis pipeline to help us explore the voice-face relationship in a fine-grained manner, i.e., phonemes v.s. facial anthropometric measurements (AM). We build an estimator for each phoneme-AM pair and evaluate the correlation through hypothesis testing. Our results indicate that AMs are more predictable from vowels compared to consonants, particularly with plosives. Additionally, we observe that if a specific AM exhibits more movement during phoneme pronunciation, it is more predictable. Our findings support those in physiology regarding correlation and lay the groundwork for future research on speech-face multimodal learning.
Improved Loss Function-Based Prediction Method of Extreme Temperatures in Greenhouses
Nov 02, 2021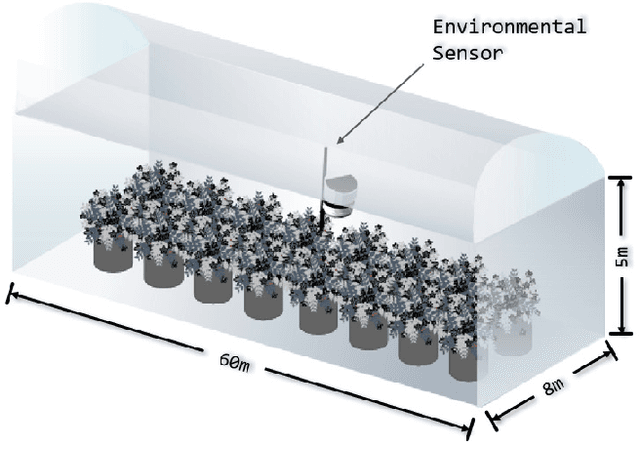
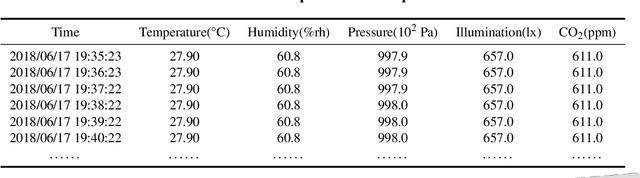
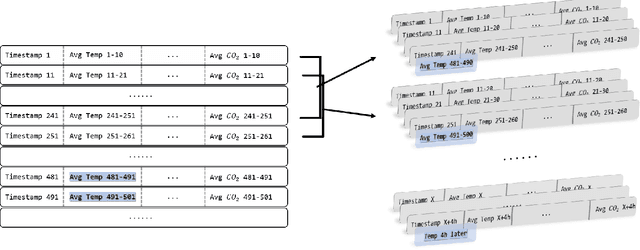

The prediction of extreme greenhouse temperatures to which crops are susceptible is essential in the field of greenhouse planting. It can help avoid heat or freezing damage and economic losses. Therefore, it's important to develop models that can predict them accurately. Due to the lack of extreme temperature data in datasets, it is challenging for models to accurately predict it. In this paper, we propose an improved loss function, which is suitable for a variety of machine learning models. By increasing the weight of extreme temperature samples and reducing the possibility of misjudging extreme temperature as normal, the proposed loss function can enhance the prediction results in extreme situations. To verify the effectiveness of the proposed method, we implement the improved loss function in LightGBM, long short-term memory, and artificial neural network and conduct experiments on a real-world greenhouse dataset. The results show that the performance of models with the improved loss function is enhanced compared to the original models in extreme cases. The improved models can be used to guarantee the timely judgment of extreme temperatures in agricultural greenhouses, thereby preventing unnecessary losses caused by incorrect predictions.
SOTR: Segmenting Objects with Transformers
Aug 17, 2021

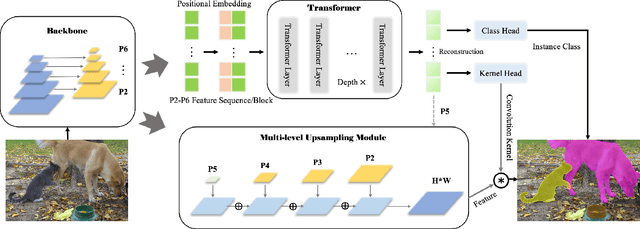
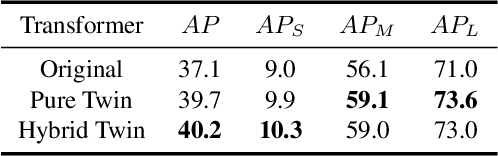
Most recent transformer-based models show impressive performance on vision tasks, even better than Convolution Neural Networks (CNN). In this work, we present a novel, flexible, and effective transformer-based model for high-quality instance segmentation. The proposed method, Segmenting Objects with TRansformers (SOTR), simplifies the segmentation pipeline, building on an alternative CNN backbone appended with two parallel subtasks: (1) predicting per-instance category via transformer and (2) dynamically generating segmentation mask with the multi-level upsampling module. SOTR can effectively extract lower-level feature representations and capture long-range context dependencies by Feature Pyramid Network (FPN) and twin transformer, respectively. Meanwhile, compared with the original transformer, the proposed twin transformer is time- and resource-efficient since only a row and a column attention are involved to encode pixels. Moreover, SOTR is easy to be incorporated with various CNN backbones and transformer model variants to make considerable improvements for the segmentation accuracy and training convergence. Extensive experiments show that our SOTR performs well on the MS COCO dataset and surpasses state-of-the-art instance segmentation approaches. We hope our simple but strong framework could serve as a preferment baseline for instance-level recognition. Our code is available at https://github.com/easton-cau/SOTR.
LeafMask: Towards Greater Accuracy on Leaf Segmentation
Aug 08, 2021
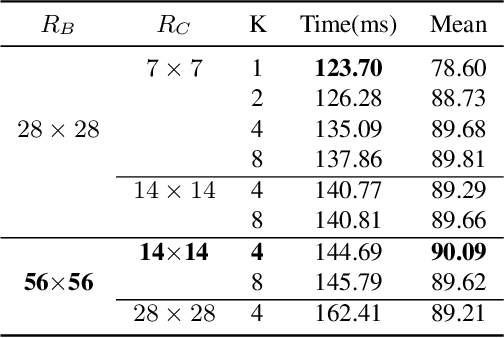
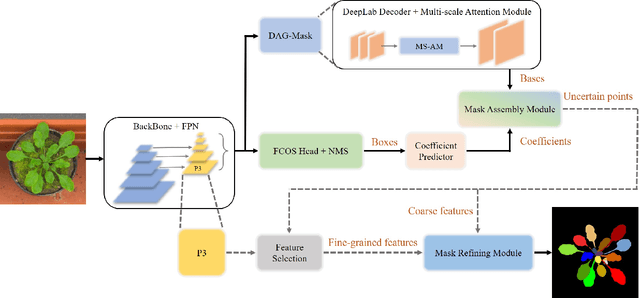
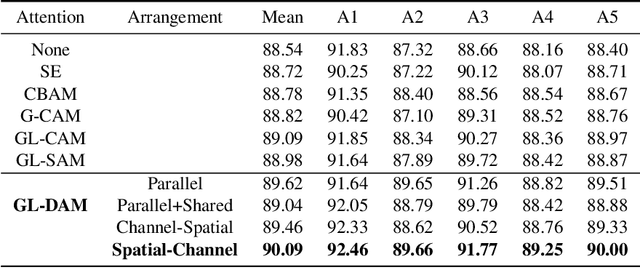
Leaf segmentation is the most direct and effective way for high-throughput plant phenotype data analysis and quantitative researches of complex traits. Currently, the primary goal of plant phenotyping is to raise the accuracy of the autonomous phenotypic measurement. In this work, we present the LeafMask neural network, a new end-to-end model to delineate each leaf region and count the number of leaves, with two main components: 1) the mask assembly module merging position-sensitive bases of each predicted box after non-maximum suppression (NMS) and corresponding coefficients to generate original masks; 2) the mask refining module elaborating leaf boundaries from the mask assembly module by the point selection strategy and predictor. In addition, we also design a novel and flexible multi-scale attention module for the dual attention-guided mask (DAG-Mask) branch to effectively enhance information expression and produce more accurate bases. Our main contribution is to generate the final improved masks by combining the mask assembly module with the mask refining module under the anchor-free instance segmentation paradigm. We validate our LeafMask through extensive experiments on Leaf Segmentation Challenge (LSC) dataset. Our proposed model achieves the 90.09% BestDice score outperforming other state-of-the-art approaches.