 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-view Domain Generalization via Geometric Consistency for LiDAR Semantic Segmentation
Feb 16, 2026Domain-generalized LiDAR semantic segmentation (LSS) seeks to train models on source-domain point clouds that generalize reliably to multiple unseen target domains, which is essential for real-world LiDAR applications. However, existing approaches assume similar acquisition views (e.g., vehicle-mounted) and struggle in cross-view scenarios, where observations differ substantially due to viewpoint-dependent structural incompleteness and non-uniform point density. Accordingly, we formulate cross-view domain generalization for LiDAR semantic segmentation and propose a novel framework, termed CVGC (Cross-View Geometric Consistency). Specifically, we introduce a cross-view geometric augmentation module that models viewpoint-induced variations in visibility and sampling density, generating multiple cross-view observations of the same scene. Subsequently, a geometric consistency module enforces consistent semantic and occupancy predictions across geometrically augmented point clouds of the same scene. Extensive experiments on six public LiDAR datasets establish the first systematic evaluation of cross-view domain generalization for LiDAR semantic segmentation, demonstrating that CVGC consistently outperforms state-of-the-art methods when generalizing from a single source domain to multiple target domains with heterogeneous acquisition viewpoints. The source code will be publicly available at https://github.com/KintomZi/CVGC-DG
Survey of Multimodal Geospatial Foundation Models: Techniques, Applications, and Challenges
Oct 27, 2025Foundation models have transformed natural language processing and computer vision, and their impact is now reshaping remote sensing image analysis. With powerful generalization and transfer learning capabilities, they align naturally with the multimodal, multi-resolution, and multi-temporal characteristics of remote sensing data. To address unique challenges in the field, multimodal geospatial foundation models (GFMs) have emerged as a dedicated research frontier. This survey delivers a comprehensive review of multimodal GFMs from a modality-driven perspective, covering five core visual and vision-language modalities. We examine how differences in imaging physics and data representation shape interaction design, and we analyze key techniques for alignment, integration, and knowledge transfer to tackle modality heterogeneity, distribution shifts, and semantic gaps. Advances in training paradigms, architectures, and task-specific adaptation strategies are systematically assessed alongside a wealth of emerging benchmarks. Representative multimodal visual and vision-language GFMs are evaluated across ten downstream tasks, with insights into their architectures, performance, and application scenarios. Real-world case studies, spanning land cover mapping, agricultural monitoring, disaster response, climate studies, and geospatial intelligence, demonstrate the practical potential of GFMs. Finally, we outline pressing challenges in domain generalization, interpretability, efficiency, and privacy, and chart promising avenues for future research.
Diffusion Models Meet Remote Sensing: Principles, Methods, and Perspectives
Apr 13, 2024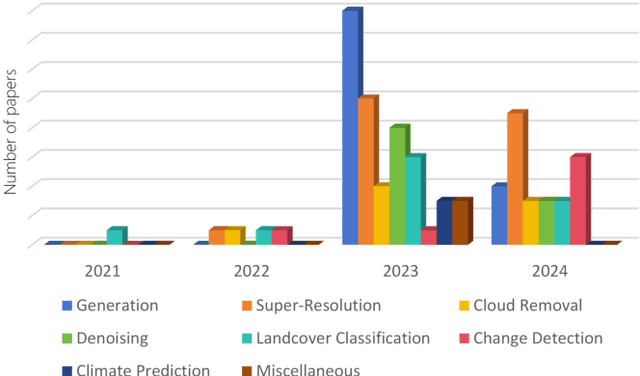


As a newly emerging advance in deep generative models, diffusion models have achieved state-of-the-art results in many fields, including computer vision, natural language processing, and molecule design. The remote sensing community has also noticed the powerful ability of diffusion models and quickly applied them to a variety of tasks for image processing. Given the rapid increase in research on diffusion models in the field of remote sensing, it is necessary to conduct a comprehensive review of existing diffusion model-based remote sensing papers, to help researchers recognize the potential of diffusion models and provide some directions for further exploration. Specifically, this paper first introduces the theoretical background of diffusion models, and then systematically reviews the applications of diffusion models in remote sensing, including image generation, enhancement, and interpretation. Finally, the limitations of existing remote sensing diffusion models and worthy research directions for further exploration are discussed and summarized.
Densify Your Labels: Unsupervised Clustering with Bipartite Matching for Weakly Supervised Point Cloud Segmentation
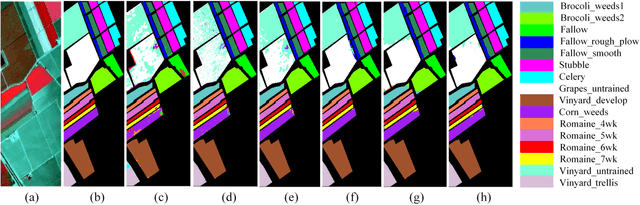
Dec 11, 2023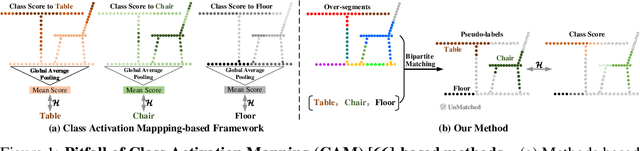
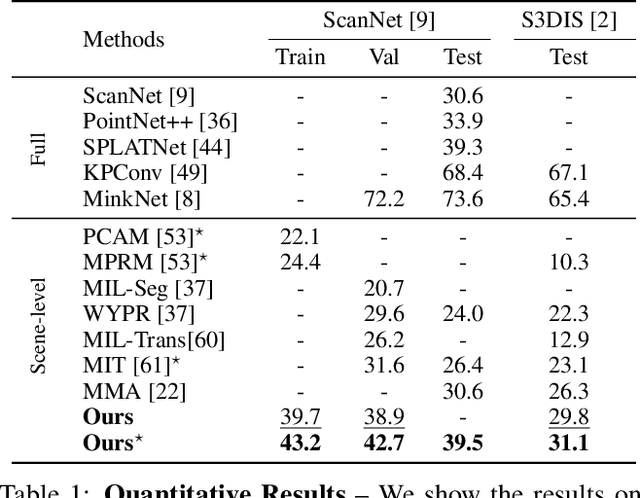
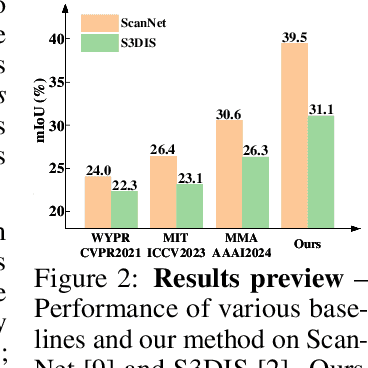
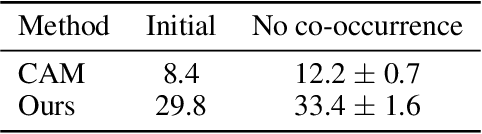
We propose a weakly supervised semantic segmentation method for point clouds that predicts "per-point" labels from just "whole-scene" annotations while achieving the performance of recent fully supervised approaches. Our core idea is to propagate the scene-level labels to each point in the point cloud by creating pseudo labels in a conservative way. Specifically, we over-segment point cloud features via unsupervised clustering and associate scene-level labels with clusters through bipartite matching, thus propagating scene labels only to the most relevant clusters, leaving the rest to be guided solely via unsupervised clustering. We empirically demonstrate that over-segmentation and bipartite assignment plays a crucial role. We evaluate our method on ScanNet and S3DIS datasets, outperforming state of the art, and demonstrate that we can achieve results comparable to fully supervised methods.
SpectralDiff: Hyperspectral Image Classification with Spectral-Spatial Diffusion Models
Apr 12, 2023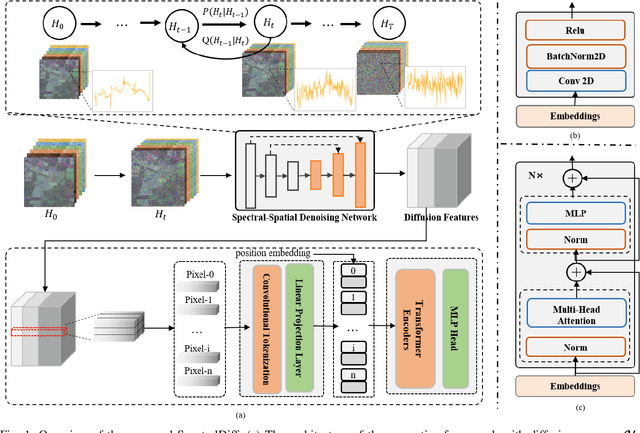
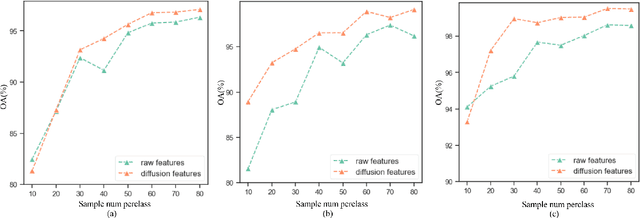

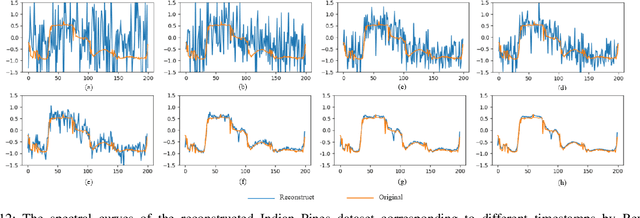
Hyperspectral image (HSI) classification is an important topic in the field of remote sensing, and has a wide range of applications in Earth science. HSIs contain hundreds of continuous bands, which are characterized by high dimension and high correlation between adjacent bands. The high dimension and redundancy of HSI data bring great difficulties to HSI classification. In recent years, a large number of HSI feature extraction and classification methods based on deep learning have been proposed. However, their ability to model the global relationships among samples in both spatial and spectral domains is still limited. In order to solve this problem, an HSI classification method with spectral-spatial diffusion models is proposed. The proposed method realizes the reconstruction of spectral-spatial distribution of the training samples with the forward and reverse spectral-spatial diffusion process, thus modeling the global spatial-spectral relationship between samples. Then, we use the spectral-spatial denoising network of the reverse process to extract the unsupervised diffusion features. Features extracted by the spectral-spatial diffusion models can achieve cross-sample perception from the reconstructed distribution of the training samples, thus obtaining better classification performance. Experiments on three public HSI datasets show that the proposed method can achieve better performance than the state-of-the-art methods. The source code and the pre-trained spectral-spatial diffusion model will be publicly available at https://github.com/chenning0115/SpectralDiff.
Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion Models
Jan 19, 2023


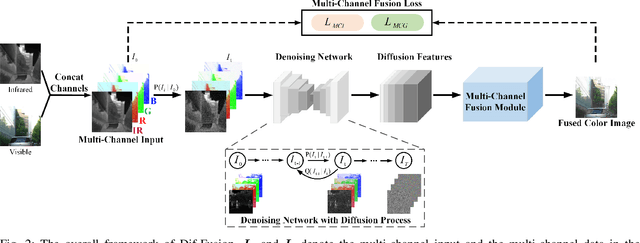
Color plays an important role in human visual perception, reflecting the spectrum of objects. However, the existing infrared and visible image fusion methods rarely explore how to handle multi-spectral/channel data directly and achieve high color fidelity. This paper addresses the above issue by proposing a novel method with diffusion models, termed as Dif-Fusion, to generate the distribution of the multi-channel input data, which increases the ability of multi-source information aggregation and the fidelity of colors. In specific, instead of converting multi-channel images into single-channel data in existing fusion methods, we create the multi-channel data distribution with a denoising network in a latent space with forward and reverse diffusion process. Then, we use the the denoising network to extract the multi-channel diffusion features with both visible and infrared information. Finally, we feed the multi-channel diffusion features to the multi-channel fusion module to directly generate the three-channel fused image. To retain the texture and intensity information, we propose multi-channel gradient loss and intensity loss. Along with the current evaluation metrics for measuring texture and intensity fidelity, we introduce a new evaluation metric to quantify color fidelity. Extensive experiments indicate that our method is more effective than other state-of-the-art image fusion methods, especially in color fidelity.
Optical Remote Sensing Image Understanding with Weak Supervision: Concepts, Methods, and Perspectives
Apr 18, 2022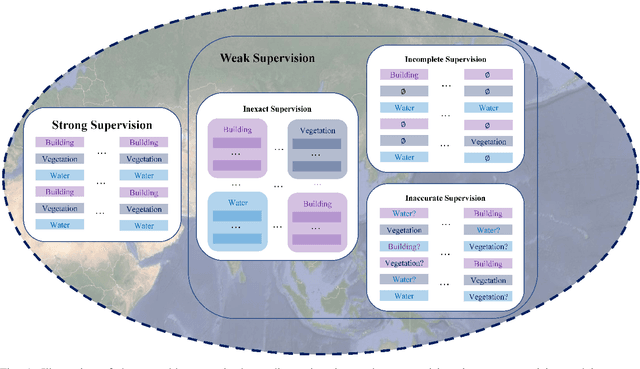
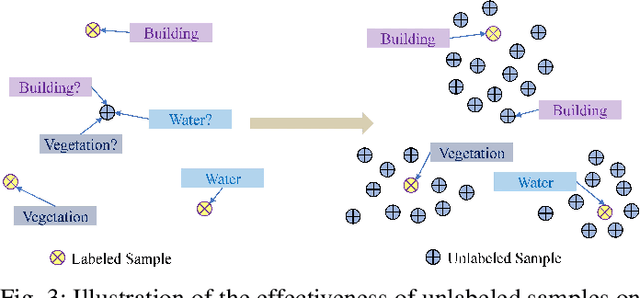

In recent years, supervised learning has been widely used in various tasks of optical remote sensing image understanding, including remote sensing image classification, pixel-wise segmentation, change detection, and object detection. The methods based on supervised learning need a large amount of high-quality training data and their performance highly depends on the quality of the labels. However, in practical remote sensing applications, it is often expensive and time-consuming to obtain large-scale data sets with high-quality labels, which leads to a lack of sufficient supervised information. In some cases, only coarse-grained labels can be obtained, resulting in the lack of exact supervision. In addition, the supervised information obtained manually may be wrong, resulting in a lack of accurate supervision. Therefore, remote sensing image understanding often faces the problems of incomplete, inexact, and inaccurate supervised information, which will affect the breadth and depth of remote sensing applications. In order to solve the above-mentioned problems, researchers have explored various tasks in remote sensing image understanding under weak supervision. This paper summarizes the research progress of weakly supervised learning in the field of remote sensing, including three typical weakly supervised paradigms: 1) Incomplete supervision, where only a subset of training data is labeled; 2) Inexact supervision, where only coarse-grained labels of training data are given; 3) Inaccurate supervision, where the labels given are not always true on the ground.
LeafMask: Towards Greater Accuracy on Leaf Segmentation
Aug 08, 2021
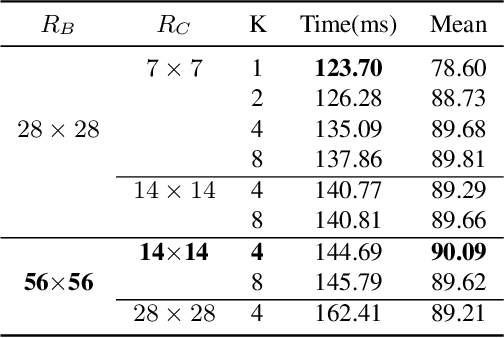
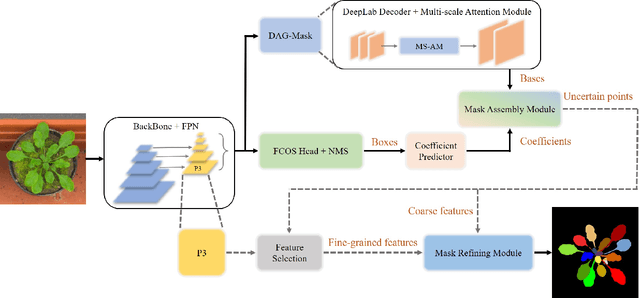
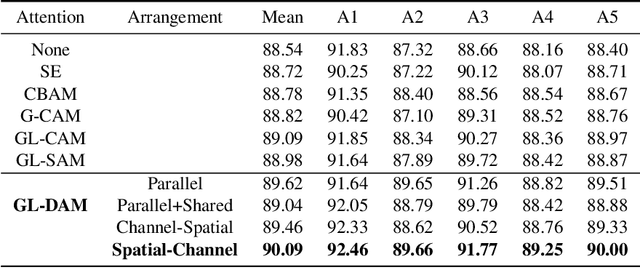
Leaf segmentation is the most direct and effective way for high-throughput plant phenotype data analysis and quantitative researches of complex traits. Currently, the primary goal of plant phenotyping is to raise the accuracy of the autonomous phenotypic measurement. In this work, we present the LeafMask neural network, a new end-to-end model to delineate each leaf region and count the number of leaves, with two main components: 1) the mask assembly module merging position-sensitive bases of each predicted box after non-maximum suppression (NMS) and corresponding coefficients to generate original masks; 2) the mask refining module elaborating leaf boundaries from the mask assembly module by the point selection strategy and predictor. In addition, we also design a novel and flexible multi-scale attention module for the dual attention-guided mask (DAG-Mask) branch to effectively enhance information expression and produce more accurate bases. Our main contribution is to generate the final improved masks by combining the mask assembly module with the mask refining module under the anchor-free instance segmentation paradigm. We validate our LeafMask through extensive experiments on Leaf Segmentation Challenge (LSC) dataset. Our proposed model achieves the 90.09% BestDice score outperforming other state-of-the-art approaches.
Supervised multiview learning based on simultaneous learning of multiview intact and single view classifier
Jan 09, 2016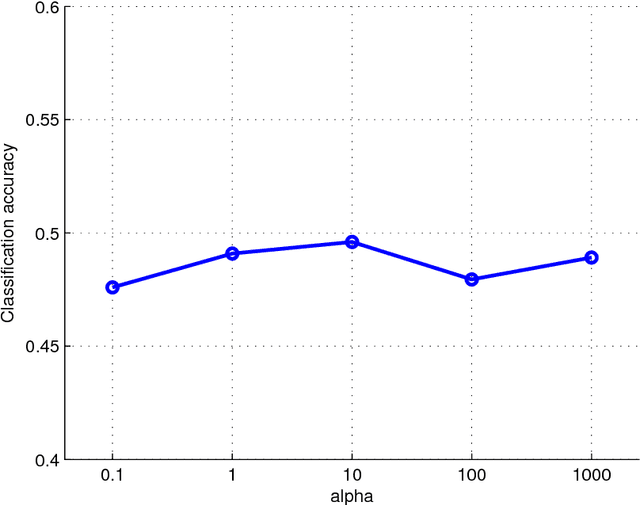
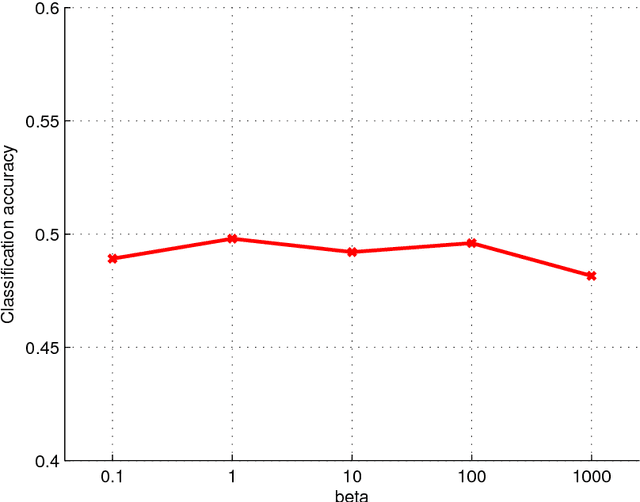
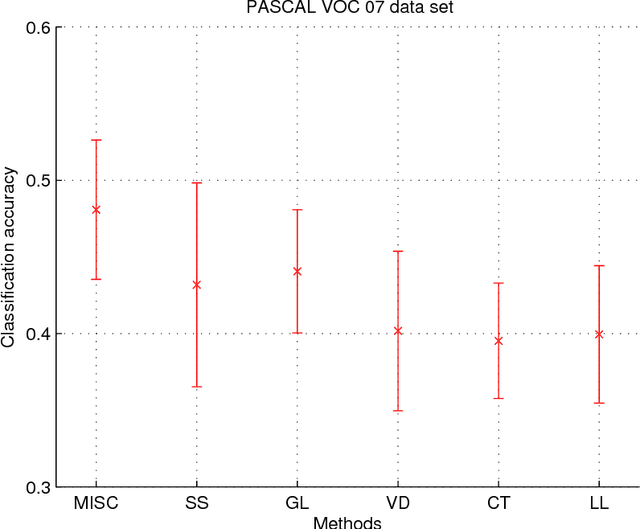
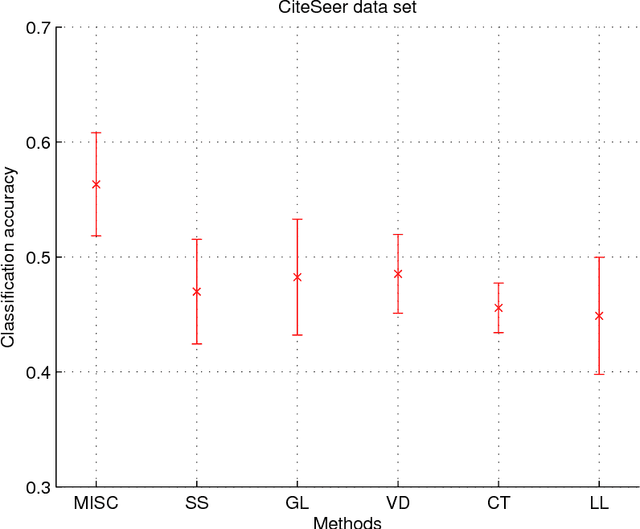
Multiview learning problem refers to the problem of learning a classifier from multiple view data. In this data set, each data points is presented by multiple different views. In this paper, we propose a novel method for this problem. This method is based on two assumptions. The first assumption is that each data point has an intact feature vector, and each view is obtained by a linear transformation from the intact vector. The second assumption is that the intact vectors are discriminative, and in the intact space, we have a linear classifier to separate the positive class from the negative class. We define an intact vector for each data point, and a view-conditional transformation matrix for each view, and propose to reconstruct the multiple view feature vectors by the product of the corresponding intact vectors and transformation matrices. Moreover, we also propose a linear classifier in the intact space, and learn it jointly with the intact vectors. The learning problem is modeled by a minimization problem, and the objective function is composed of a Cauchy error estimator-based view-conditional reconstruction term over all data points and views, and a classification error term measured by hinge loss over all the intact vectors of all the data points. Some regularization terms are also imposed to different variables in the objective function. The minimization problem is solve by an iterative algorithm using alternate optimization strategy and gradient descent algorithm. The proposed algorithm shows it advantage in the compression to other multiview learning algorithms on benchmark data sets.