 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Brain Age with Global and Local Dependencies
Sep 19, 2022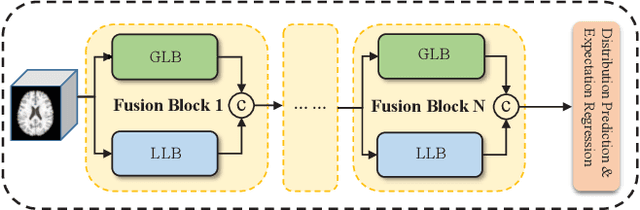
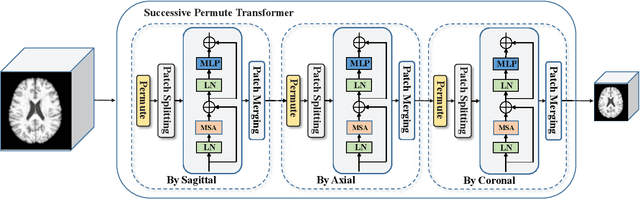
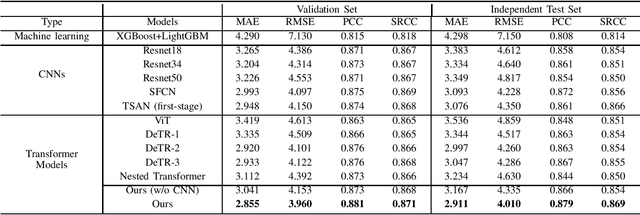
The brain age has been proven to be a phenotype of relevance to cognitive performance and brain disease. Achieving accurate brain age prediction is an essential prerequisite for optimizing the predicted brain-age difference as a biomarker. As a comprehensive biological characteristic, the brain age is hard to be exploited accurately with models using feature engineering and local processing such as local convolution and recurrent operations that process one local neighborhood at a time. Instead, Vision Transformers learn global attentive interaction of patch tokens, introducing less inductive bias and modeling long-range dependencies. In terms of this, we proposed a novel network for learning brain age interpreting with global and local dependencies, where the corresponding representations are captured by Successive Permuted Transformer (SPT) and convolution blocks. The SPT brings computation efficiency and locates the 3D spatial information indirectly via continuously encoding 2D slices from different views. Finally, we collect a large cohort of 22645 subjects with ages ranging from 14 to 97 and our network performed the best among a series of deep learning methods, yielding a mean absolute error (MAE) of 2.855 in validation set, and 2.911 in an independent test set.
Uncertainty Quantification in Medical Image Segmentation with Multi-decoder U-Net
Sep 15, 2021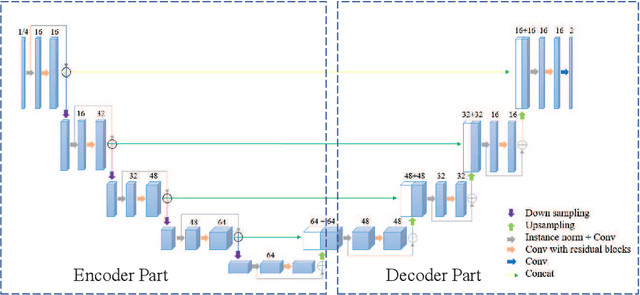
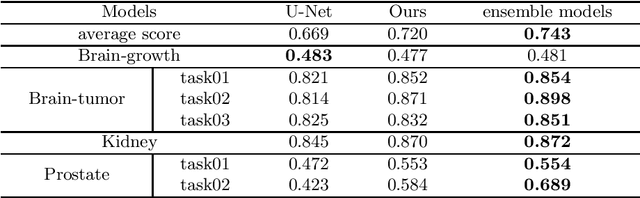
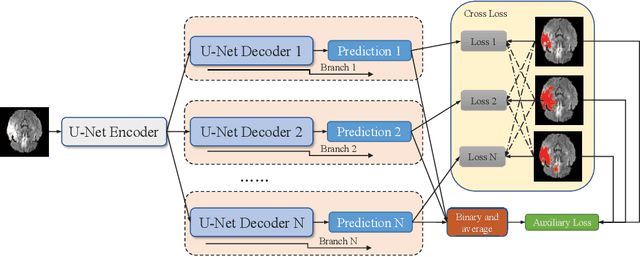
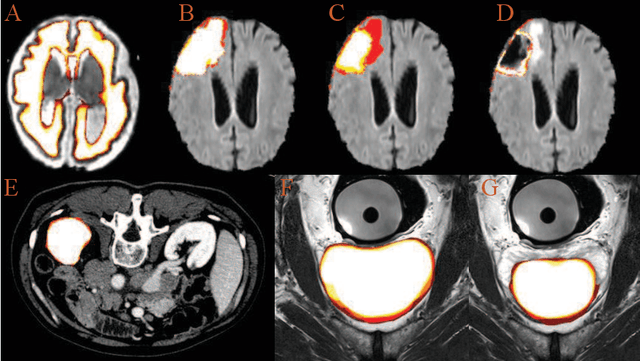
Accurate medical image segmentation is crucial for diagnosis and analysis. However, the models without calibrated uncertainty estimates might lead to errors in downstream analysis and exhibit low levels of robustness. Estimating the uncertainty in the measurement is vital to making definite, informed conclusions. Especially, it is difficult to make accurate predictions on ambiguous areas and focus boundaries for both models and radiologists, even harder to reach a consensus with multiple annotations. In this work, the uncertainty under these areas is studied, which introduces significant information with anatomical structure and is as important as segmentation performance. We exploit the medical image segmentation uncertainty quantification by measuring segmentation performance with multiple annotations in a supervised learning manner and propose a U-Net based architecture with multiple decoders, where the image representation is encoded with the same encoder, and segmentation referring to each annotation is estimated with multiple decoders. Nevertheless, a cross-loss function is proposed for bridging the gap between different branches. The proposed architecture is trained in an end-to-end manner and able to improve predictive uncertainty estimates. The model achieves comparable performance with fewer parameters to the integrated training model that ranked the runner-up in the MICCAI-QUBIQ 2020 challenge.
Supervised multiview learning based on simultaneous learning of multiview intact and single view classifier
Jan 09, 2016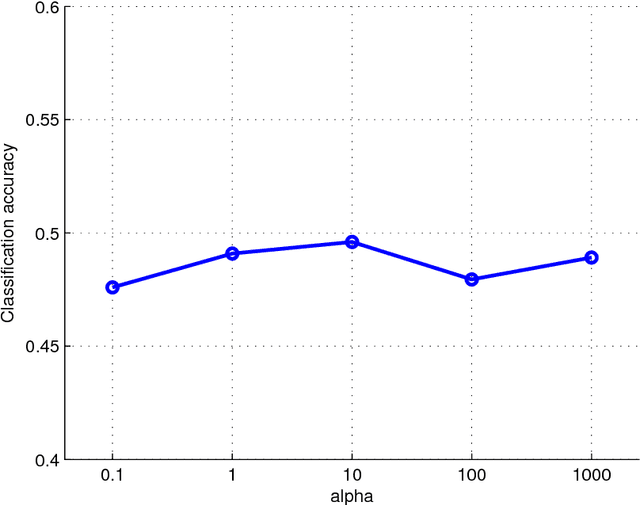
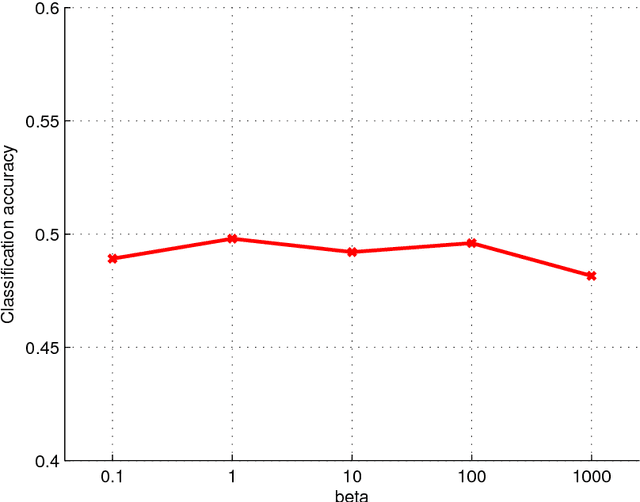
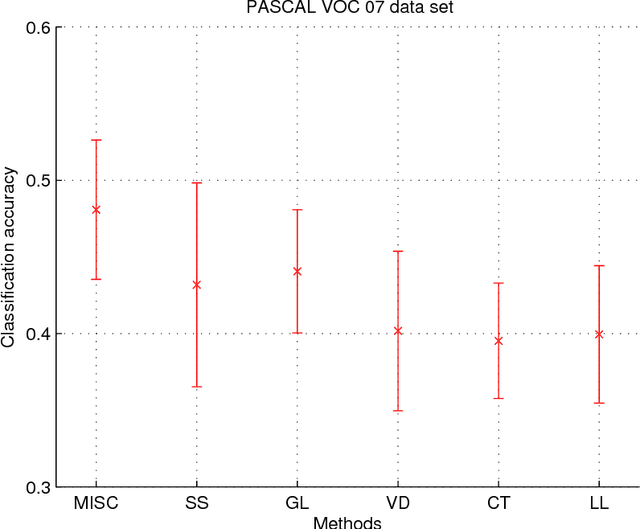
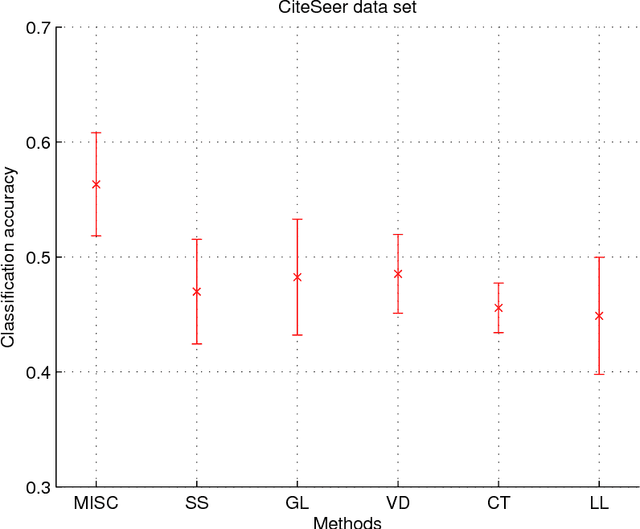
Multiview learning problem refers to the problem of learning a classifier from multiple view data. In this data set, each data points is presented by multiple different views. In this paper, we propose a novel method for this problem. This method is based on two assumptions. The first assumption is that each data point has an intact feature vector, and each view is obtained by a linear transformation from the intact vector. The second assumption is that the intact vectors are discriminative, and in the intact space, we have a linear classifier to separate the positive class from the negative class. We define an intact vector for each data point, and a view-conditional transformation matrix for each view, and propose to reconstruct the multiple view feature vectors by the product of the corresponding intact vectors and transformation matrices. Moreover, we also propose a linear classifier in the intact space, and learn it jointly with the intact vectors. The learning problem is modeled by a minimization problem, and the objective function is composed of a Cauchy error estimator-based view-conditional reconstruction term over all data points and views, and a classification error term measured by hinge loss over all the intact vectors of all the data points. Some regularization terms are also imposed to different variables in the objective function. The minimization problem is solve by an iterative algorithm using alternate optimization strategy and gradient descent algorithm. The proposed algorithm shows it advantage in the compression to other multiview learning algorithms on benchmark data sets.